[KR] 초고성능 GPU 클러스터: CORE 구축하기

안녕하세요, WoRV팀에서 근무중인 최수환입니다. 오늘은 제가 리드해 사내의 고성능 GPU 자원인 DGX H100 12대(전체 H100 96개)를 모아 구축한 클러스터, CORE(Compute-Oriented Research Environment)을 구축하게 된 배경, 이것을 구축하기 위해 필요한 여러 지식, 실제로 어떻게 작업했는지, 그에 따른 결과물에 대해 소개해드리려고 합니다.
HPC(High-Performance Computing)
과거에서부터 scientific computing 등 여러 용도로 막대한 분량의 compute에 대한 수요는 지속적으로 존재해왔습니다.
더불어서, compute scaling law에 따라, 100년이 넘게 compute의 비용은 시간이 지남에 따라 지수적으로 감소하는 추세를 강건하게 이어왔습니다.
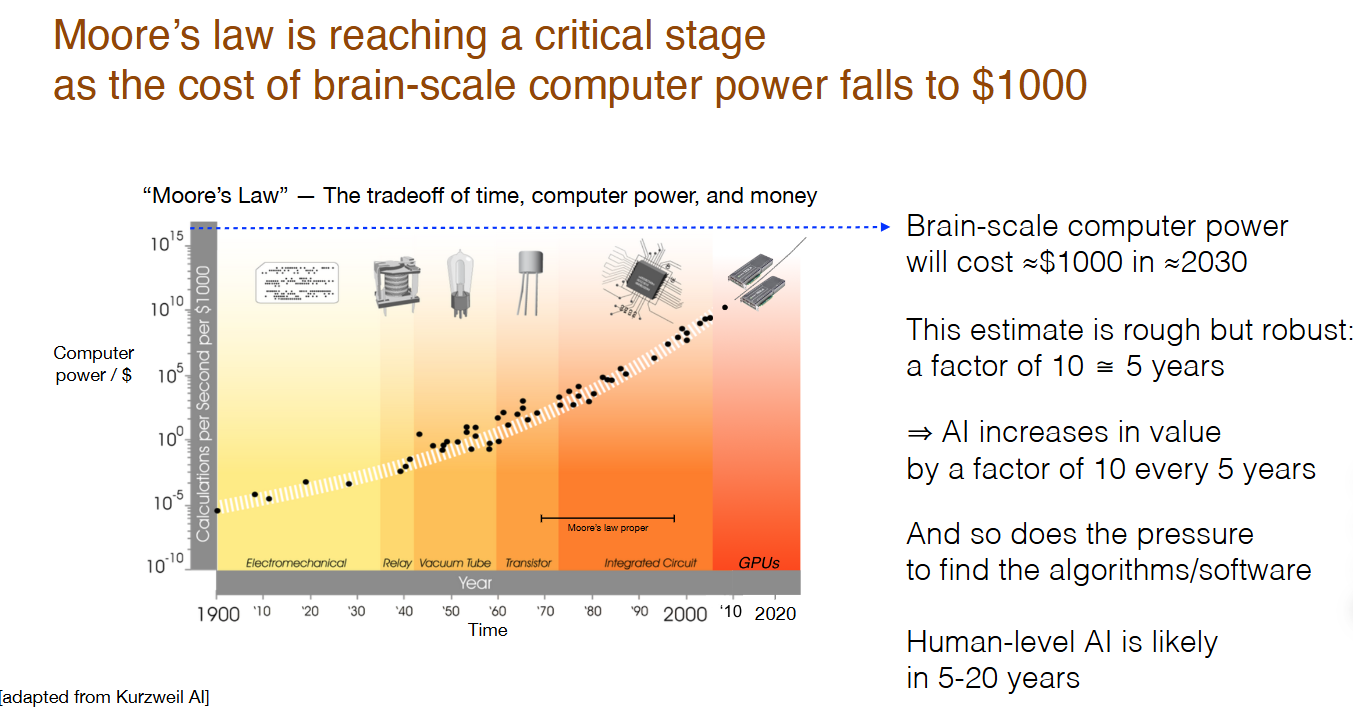
이러한 강건한 compute scaling law의 추세는 2010년대 초반부터 GPU의 발전과 힘입어 인공지능, AI/ML 분야의 급격한 성장을 이끌어왔습니다. 인공지능의 역사는 연산의 비용이 지수적으로 싸짐에 따라, 매우 많은 연산과 데이터를 필요로 하지만 scale한다면 이전의 방법론들을 압도할 수 있는 엔드투엔드 방법론을 도입하는 것과 같이합니다.
곁다리 이야기: "bitter lesson"
인간의 지능을 모방하는 가장 '쉬운' 방법은 사람의 손으로 설계하는 것이지만, 이것은 절대 '잘 작동하는' 방법은 아닙니다.
인간을 모방하는 무언가는 얼마든지 만들 수 있습니다. 결국은 얼마나 잘 근사하냐의 차이가 있을 뿐입니다. 당장 주어진 입력에 대해 항상 0을 반환하는 함수 역시도 그 거리가 멀 뿐 인간을 근사하는 함수라고 말할 수 있습니다. 그리고 인공지능의 역사는 인간이 부여하는 구조나 전제를 제거해나가고 가장 효과적으로 scaling되는 아주 일부의 무언가를 찾아내는 것과 함께합니다.
이미지 분류, 자연어 처리, 음성 인식, 체스 엔진 등. 이러한 것들이 한때는 전부 해당 분야의 전문가만이 다룰 수 있는 분야였으며 그러한 전문가만이 로직을 짤 수 있었습니다. 하지만 지금은 전혀 아닙니다. 여러 태스크에서 항상 그래 왔었고, 앞으로도 그럴 겁니다.
하지만 로보틱스 태스크에는 이러한 경향성이 아직 녹아들어있지 않습니다. WoRV팀은 이러한, 아직 오지 않은, 필연적인 흐름을 여러 연구와 작업을 통해 이끌어나가려 하고, 그렇게 하고 있습니다.
통신의 중요성
딥러닝 클러스터에서 특히 더 두드러지는 부분이 있는데, 바로 막대한 양의 병렬 연산과 동시에 막대한 양의 communication이 필수적이라는 부분입니다. 일반적인 인식으로 HPC에는 "많은 연산만이 들어가겠지"라고 인지하는 것과 다르게, 통신의 비중과 중요도는 매우 높습니다. 이것은 단순히 병렬로 연산하는 게 전부인 게 아니라, 병렬로 연산한 결과물을 모아서(e.g. all-reduce) 활용하는 것이 필요하기 때문입니다. 예컨대,
- Data Parallelism:
- 일반적으로 인공지능 모델을 학습할 때는 데이터에 대한 무언가의 값(e.g. 기울기 등)을 계산하여 활용합니다. 이때 통상적으로 전체 데이터의 양은 하나의 노드에서 처리할 수 없을 정도로 막대한데, 이러한 상황에서 여러 노드에서 여러 데이터를 독립적으로 연산하고 그 결과만을 보아서 활용한다면(e.g. grad에 대한 all-reduce) 병렬성에서의 매우 큰 이득을 볼 수 있습니다. 이것을 Data Parallelism이라고 합니다.
- 이때, 연산 결과를 모으는 과정(e.g. grad에 대한 all-reduce)에서 상당한 양의 통신이 필요합니다.
- 이외에도 딥러닝 클러스터에서는 Pipeline Parallelism, Tensor Parallelism을 활용해 병렬성의 이점을 누립니다.
NVIDIA에서는 그래서 대역폭을 해결해주는 많은 요소들을 제공해줍니다. 먼저 DGX H100에 대해 소개해보겠습니다.
DGX H100
아래는 DGX H100의 내부 구조도입니다. 한번 뜯어봅시다.
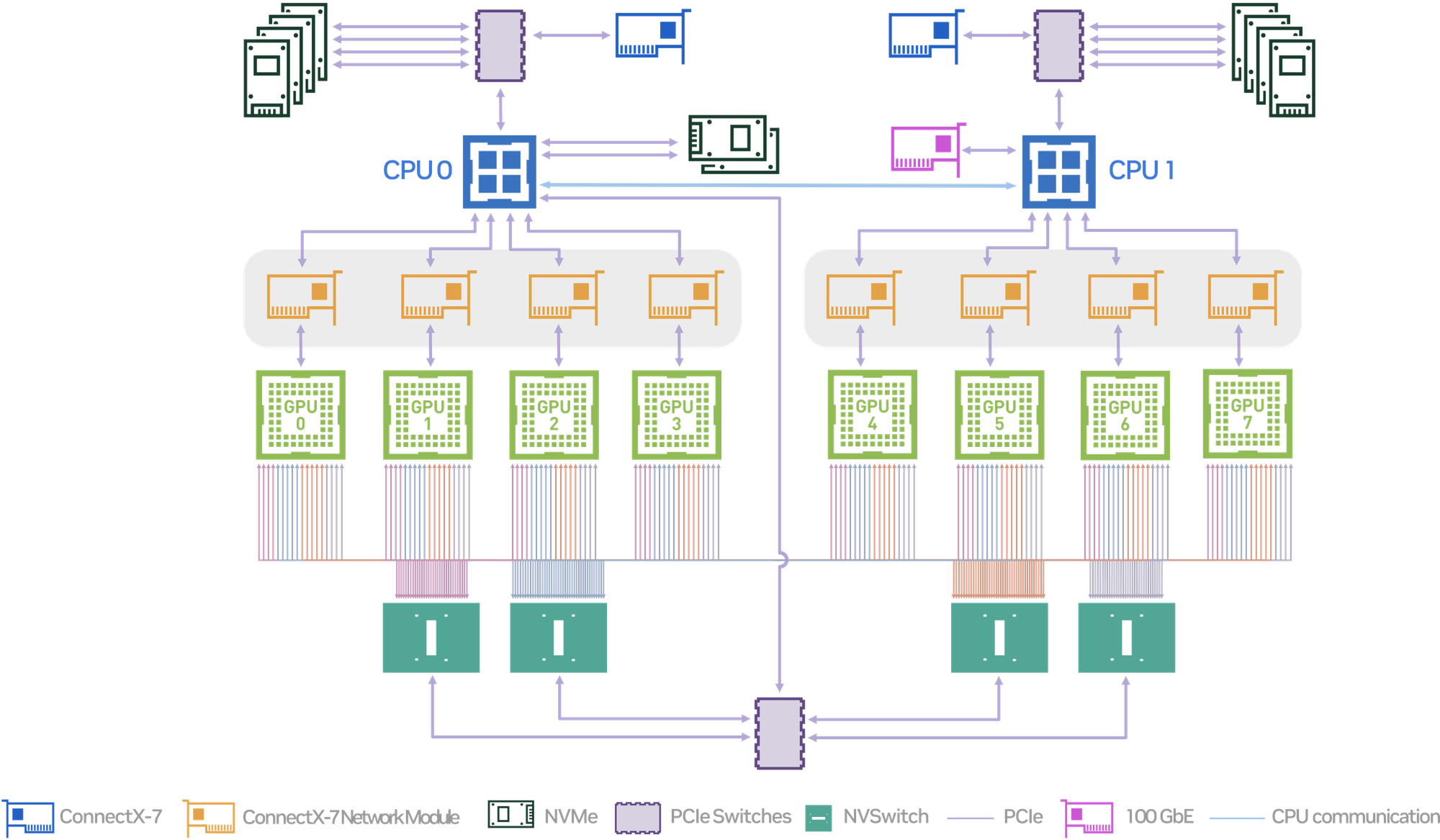
- 최신 GPU들은 높은 양의 연산량과 동시에 높은 메모리 대역폭을 제공합니다. H100은 bfloat16 1979 teraFLOPS에 달하는 연산도 제공하지만, 동시에 3.35TB/s의 메모리 대역폭과 80GB의 메모리 역시도 제공합니다.

- 노드 내에서의 빠른 통신을 위해서 NVLink, NVSwitch를 제공합니다. 이들은 3세대에서 600GB/s, 4세대에서 900GB/s, 5세대에서 1.8TB/s에 달하는 대역폭을 제공합니다.

- 노드 외부로의 빠른 통신을 위해 ConnectX-7 HCA와 100GbE 이더넷 연결을 제공합니다. ConnectX-7 HCA는 네트워크 카드의 일종으로 400Gb/s의 처리량을 제공합니다.
NVIDIA DGX BasePOD
다음은 노드 외부로의 통신에 집중하여 몇가지를 소개하겠습니다. NVIDIA에서는 DX BasePOD라는 이름으로, NVIDIA DGX 시스템을 구성요소로 하여 인공지능 연구/개발을 가속화하는 인프라/소프트웨어 등을 제공하고 있습니다. 이들이 제공하는 좋은 아키텍처 구조도를 "Reference Architecture", RA라고 부릅니다.
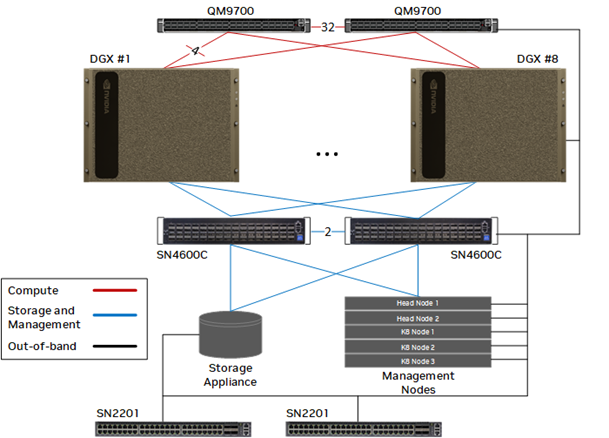
RA를 한번 봅시다. RA에서는 compute node 2-8대와 스토리지, 관리 노드가 존재합니다. 이들을 이어주는 것은 다음 2가지 종류인데요,
- QM9700: NVIDIA Infiniband 스위치입니다. 인피니밴드는 이더넷에 비해 높은 대역폭과 낮은 지연시간을 가져오는 것으로 알려진 고속 네트워크 기술입니다. QM9700은 최대 400Gb/s의 대역폭을 제공합니다.
- SN4600C: NVIDIA Spectrum 스위치입니다. NVIDIA Spectrum은 이더넷에 기반해 최대 400Gb/s의 대역폭을 제공합니다.
고성능 스토리지의 필요성
또한 일반적인 딥러닝 클러스터에는 고성능(high-bandwidth, high-capacity) 스토리지를 같이 사용합니다. 병렬 혹은 분산 파일시스템(parallel filesystem, distributed filesystem)을 사용하며, 다단계의 캐싱 로직으로 데이터에 대한 빠른 접근과 변경이 가능하게 합니다.
현재 사내에서는 ceph, cephfs에 기반한 분산 스토리지를 운영하고 있습니다. Ceph는 오브젝트 스토리지를 여러 노드에 분산하여 강건하게 구축할 수 있게 해주는 오픈소스 프로젝트입니다. 또한 CephFS를 이용해 POSIX 파일시스템 인터페이스 역시 제공해줍니다.

CephFS는 ceph의 오브젝트 스토리지에 해당하는 RADOS와 메타데이터 연산을 위한 MDS로 구성됩니다. ceph는 매우 장기간 유지되어 왔던 강건한 솔루션이며 유지/보수가 활발히 이루어지는 편입니다. Red Hat 재단에서 관리하여 CephFS kernel driver은 linux kernel에 포함되어 있기도 합니다.
소프트웨어 스택
앞서까지는 인프라, 하드웨어에 대해 말했는데, 그 위로 쌓아올릴 소프트웨어 스택 역시 매우 중요합니다. 먼저 인프라 관리에 사용되는 소프트웨어 툴 2가지를 소개하고 싶은데요, Ansible입니다.
Ansible
인프라 관리를 위해서는 한 두대의 노드가 아닌 수십, 그 너머를 넘는 노드를 동시에 관리할 수 있어야 합니다. 이러한 작업을 위해서는 같은 작업을 여러 노드에 걸쳐 일관적으로 수행해주는 툴이 필요하며, ansible은 그러한 역할을 수행합니다.
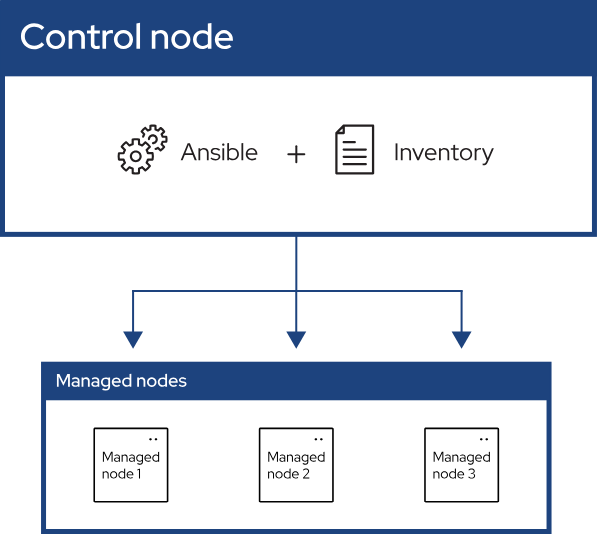
Ansible의 큰 특징은 다음 2가지입니다.
- managed node에 SSH 연결이 가능하고 파이썬이 설치되어 있기만 하면, 별도의 Ansible에 대한 설치 없이도 잘 작동합니다.
- 연산은 기본적으로 idempotent합니다. 이는 같은 연산을 n번 수행해도, 1회 수행한 것과 결과가 다르지 않다는 말입니다.
이러한 2가지 특징은 ansible을 이용해 편리하고 일관적으로 수많은 노드를 관리할 수 있도록 만들어줍니다.
Ansible과 함께 인프라 관리에 자주 사용되는 툴로 Terraform이 있습니다. Terraform은 IaC(Infrastructure-as-Code)의 철학에 기반해 AWS/GCP 등 멀티 클라우드의 리소스들을 선언하고 코드로 관리하는 것을 가능하게 합니다.
ansible galaxy
Ansible은 여러 단위 작업들을 모아 role이라는 이름으로 만들고 이들을 모아 collection이라는 이름으로 만들 수 있습니다. 또한 수많은 커뮤니티의 사람들이 이러한 collection들을 많이 기여해뒀으므로 손쉽고 편리하게 직접 어떠한 작업을 구현하지 않고도 불러오는 것만으로도 수행할 수 있습니다. 이러한 role/collection의 모음은 ansible galaxy를 통해 확인하고 바로 불러올 수 있습니다.
Slurm
"딥러닝 클러스터"를 대변하는 말로 Slurm이 있고 많은 사람들이 클러스터 하면 slurm을 떠올리는 것 같은데요, 이것은 유저 입장에서 접하는 인터페이스가 slurm이기 때문이 큰 것 같습니다. 실제로 Slurm이 수행하는 역할은, 매우 간단하며 동시에 그 하나의 역할을 매우 잘 수행해줍니다. 바로 스케쥴러입니다.
Slurm의 기능을 더 자세히 소개하자면 다음과 같은데요,
- job scheduling & resource allocation:
- 여러 job의 특성과 제출한 유저, 유저의 소속 등을 고려해 자원을 할당합니다.
- parallel job support:
- 쉽게 여러 job을 병렬화하고 각각의 job에 대한 적절한 자원을 할당받아 작업을 수행할 수 있습니다.
- extensive customization:
- 다양한 플러그인을 사용할 수 있게 지원하는데, Slurm Workload Manager을 위한 Container plugin인 https://github.com/NVIDIA/pyxis 가 그러한 예시입니다.
CORE(Compute-Oriented Research Environment)
CORE은 현재 DGX H100 12대(전체 H100 96개)로 이루어진 고성능 GPU 클러스터입니다. 현재 마음AI의 인공지능 연구/개발 조직인 Brain팀과 WoRV팀에서 자연어/오디오/비전 모달리티를 다루며 연구/개발을 하는 데에 CORE이 활발히 사용되고 있습니다.
CORE의 구축 과정
낱대의 DGX H100을 모아서 하나의 클러스터(CORE)로 만들기 위해서는 다음 작업을 수행해야 합니다.
- 각 노드의 초기 환경 설정을 진행합니다. ansible 연결을 위한 ssh 세팅이 포함됩니다.
- 모든 노드에 공통적인 기반 세팅을 진행합니다. 이때 들어가는 세팅의 예시는 다음과 같습니다.
- 유저/그룹 세팅
- 파일시스템 세팅
- 패키지 설치
- 여러 환경변수 세팅
- slurm 설치
- 모니터링 툴 배포
이때 대다수의 작업은 ansible을 이용해 진행했습니다. playbook을 작성하고 variable에 대한 yaml 파일만 수정하면 자유롭게 여러 노드의 추가/제거/변경이 가능하도록 작업했습니다.
CORE의 편리한 사용을 위한 여러 노력
slurm 사용 과정에서 가장 불편한 점은 computing 노드에 대한 직접적인 ssh 접근이 불가능하다는 점에서 기인합니다. 연구원들 입장에서는 원래 DGX에서 바로 VSCode를 remote로 열 수도 있고, devcontainer를 열 수도 있고, Jupyter Notebook을 열 수도 있었는데, 그게 안 되니 불편합니다.
디버깅/개발 노드
물론, 직접적으로 ssh 연결이 필요하다는 것 자체가 어떤 의미로는 slurm으로 고성능 자원을 활용하는 방법의 안티패턴을 사용하고 있다는 뜻일 수 있습니다. 이러한 안티패턴을 사용할 수밖에 없는 경우가 생기는 이유는 디버깅/개발을 위한 노드가 따로 존재하지 않는 것에서 기인합니다.
향후 디버깅/개발 노드의 추가는 계획에 있으나, 아직은 없습니다.
물론 ssh 접근만 안 되는 것이지 다른 커맨드가 막힌 것이 아니기에 커맨드 몇 줄만 더 입력하면 원래 하던, 위에서 언급했던 것들을 할 수 있습니다. 컴퓨팅 노드에 연결한 후에 새로운 ssh daemon을 열어버리거나, 주피터 노트북 서버를 띄운 후에 접근하거나 하는 방식이 전부 가능합니다. 하지만 이전보다 불편한 것은 확실합니다. 빠르고 유연한 프로세스가 최우선이 되어야 하는 연구/개발에 있어 이러한 사소한 불편함이 병목이 되는 것도 사실입니다.
그러나 slurm에서는 이미 이러한 상황을 해결하기 위한 작업을 해뒀습니다. 바로 pam_slurm_adopt 모듈인데요, 이 모듈을 활성화하면 특정 유저가 특정 노드에 특정 자원을 미리 요청해두면 그 자원만 보이도록 그 노드에 직접 ssh 연결을 수행할 수 있습니다. 복수의 자원을 요청하면 가장 마지막에 요청한 자원이 보입니다.
이 pam_slurm_adopt 모듈을 활용하면 단순히 ssh 연결 이전에 sbatch/srun/salloc 등으로 미리 자원만 요청해두면 됩니다. 그 이후로는 ssh 연결이 가능하기 때문에, VSCode remote의 연결부터 시작하여 jupyter notebook을 VSCode 위에서 바로 사용하는 것까지 전부가 가능해집니다.
그리고, 기존 유저들은 도커를 매우 자주 사용하고 있었습니다만, 도커는 HPC에 있어서는 그리 적합하지는 않은 컨테이너화 솔루션입니다. 매 노드마다 private space에 여러 이미지와 캐시를 저장하여 용량의 낭비가 생기고, 하나의 노드에 동시에 여러 job을 던지면 그 수만큼 여러 개의 컨테이너가 생깁니다. 이러한 상황을 해결하기 위해 나온 컨테이너 솔루션으로 enroot가 있으며, NVIDIA에서는 enroot에 대한 slurm plugin으로 pyxis를 제공하고 있습니다.
마치며...
여기까지, CORE의 구축에 필요한 배경 지식과 사용한 기술 스택, 구축 방법에 대해 간단히 소개드렸습니다.
다만, WoRV팀에 근무 중인 제가 왜 이 CORE 구축 프로젝트를 리딩하고 이러한 글을 쓰고 있는지 궁금하신 분들이 계실 것 같습니다. 그 이유는 WoRV팀에서 다루는 멀티모달 데이터의 특성상 막대한 양의 데이터를 빠르고 효율적으로 처리하고 전송할 필요성이 있기 때문입니다.
조만간, 꽤 큰 규모로, 흔히들 말하는 pretraining에 준하는 학습을 멀티모달 에이전트에서 진행할 일이 계속 생길 것 같습니다. CORE의 구축은 그에 앞선 주춧돌이라고 보시면 됩니다.
WoRV팀에서는 현재 활발히 채용을 진행중입니다. 같이 재밌는 연구하실 분들을 기다리고 있습니다. 감사합니다.


