[EN] Building the CORE High-Performance GPU Cluster

Hello, I'm Suhwan Choi from the WoRV team. Today I'd like to talk about CORE (Compute-Oriented Research Environment), a cluster I led the build of by bringing together twelve DGX H100 systems (96 H100s in total): why we decided to build it, the background knowledge you need, how we actually did the work, and what came out of it.
HPC (High-Performance Computing)
Demand for massive compute has existed consistently for a long time across many purposes such as scientific computing.
Moreover, according to the compute scaling law, the cost of compute has robustly trended down exponentially over more than a century.
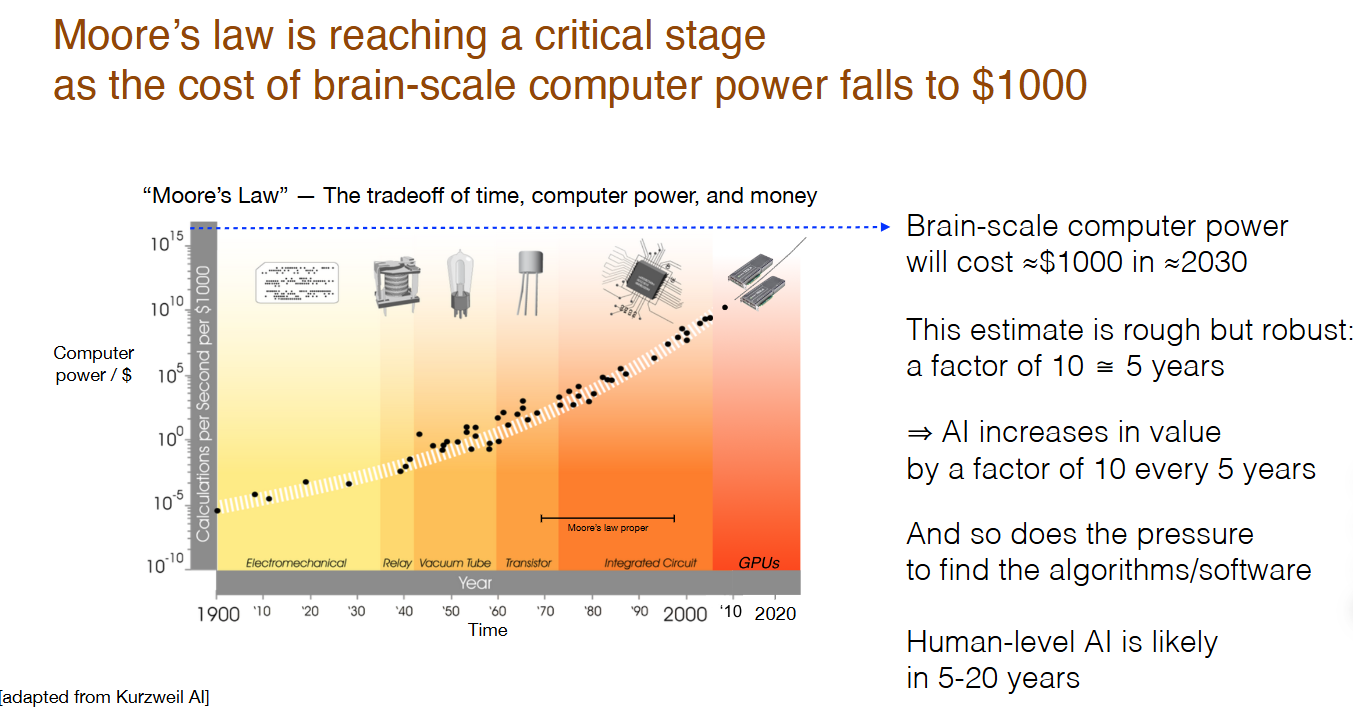
This strong trend in compute scaling, aided by advances in GPUs from the early 2010s, has driven the rapid growth of AI/ML. As the cost of compute drops exponentially, the history of AI has been about adopting end-to-end methods that require huge amounts of computation and data but, when scaled, can outperform earlier approaches.
Side note: "bitter lesson"
The "easiest" way to mimic human intelligence is to hand-engineer it, but that is hardly ever what "works best."
You can build any number of things that imitate humans; the question is just how closely they approximate. Even a function that always returns 0 for any input could be called a (distant) approximation to a human. The history of AI is one of stripping away human-imposed structures and priors and finding the few things that scale most effectively.
Image classification, natural language processing, speech recognition, chess engines, and so on—these were once domains only experts could handle, and only those experts could write the logic. That is no longer the case. It has always turned out that way across tasks, and it will continue to.
However, this trend has not yet fully permeated robotics tasks. The WoRV team aims to drive this inevitable, yet-to-arrive shift through our research and engineering—and we already are.
The importance of communication
There is something particularly pronounced in deep learning clusters: you need massive parallel computation and at the same time massive communication. Contrary to the common perception that HPC is just about "a lot of computation," the share and importance of communication are very high. It's not just about computing in parallel; you must aggregate (e.g., all-reduce) the parallel results and use them. For example,
- Data Parallelism:
- When training AI models, you typically compute some quantity about the data (e.g., gradients) and use it. The total dataset is usually too large for a single node. In such cases, if multiple nodes process different data independently and you only gather the results (e.g., an all-reduce over gradients), you can reap large gains from parallelism. This is data parallelism.
- This gathering step (e.g., all-reduce over gradients) requires a substantial amount of communication.
- Beyond that, deep learning clusters also leverage pipeline parallelism and tensor parallelism to enjoy the benefits of parallelism.
NVIDIA provides many components to address bandwidth. Let's start with the DGX H100.
DGX H100
Below is the internal block diagram of the DGX H100. Let's take a look inside.
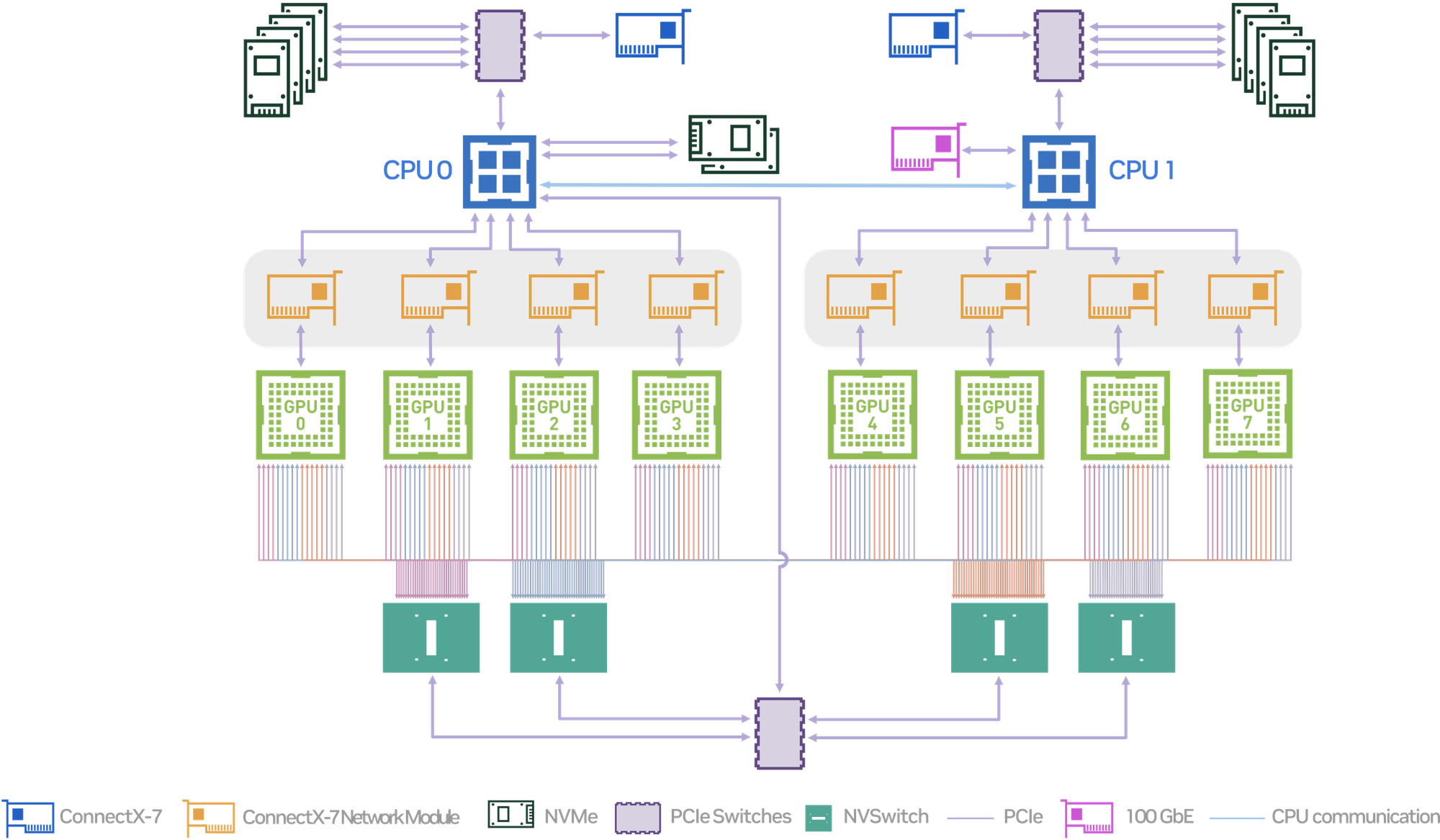
- Modern GPUs offer high compute throughput along with high memory bandwidth. H100 delivers up to 1,979 BF16 teraFLOPS of compute, and at the same time provides 3.35 TB/s of memory bandwidth and 80 GB of memory per GPU.

- Fast intra-node communication is provided by NVLink and NVSwitch. They deliver up to 600 GB/s (Gen3), 900 GB/s (Gen4), and 1.8 TB/s (Gen5) of bandwidth.

- Fast off-node communication is enabled via ConnectX-7 HCAs and 100GbE Ethernet links. A ConnectX-7 HCA is a type of NIC that offers up to 400 Gb/s of throughput.
NVIDIA DGX BasePOD
Next, focusing on off-node communication: under the name DGX BasePOD, NVIDIA provides infrastructure and software that accelerate AI research and development using NVIDIA DGX systems as building blocks. The high-quality architectural blueprints they publish are called the "Reference Architecture" (RA).
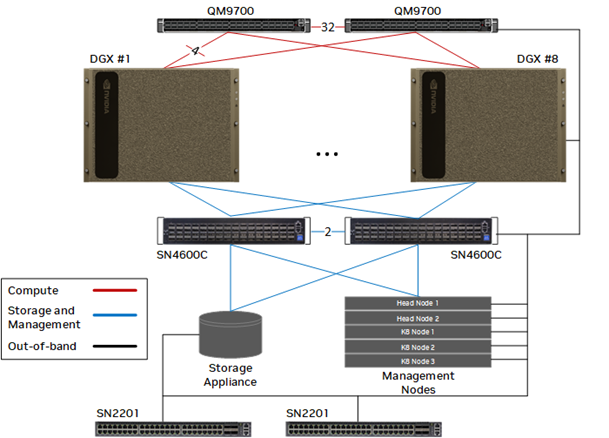
Let's look at the RA. It consists of 2–8 compute nodes plus storage and a management node. They are tied together by two kinds of switches:
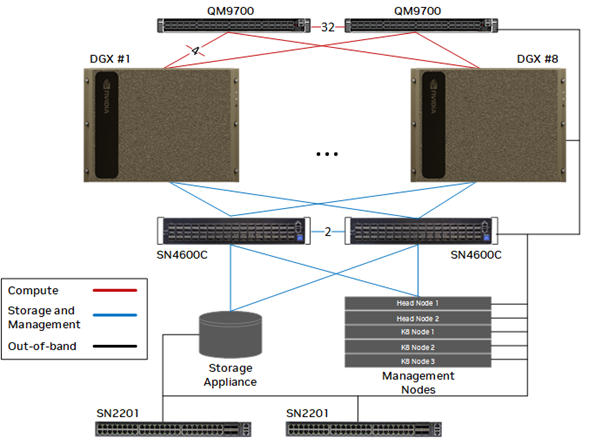
- QM9700: an NVIDIA InfiniBand switch. InfiniBand is a high-speed networking technology known for higher bandwidth and lower latency than Ethernet. QM9700 provides up to 400 Gb/s of bandwidth.
- SN4600C: an NVIDIA Spectrum Ethernet switch. NVIDIA Spectrum (Ethernet) provides up to 400 Gb/s of bandwidth.
The need for high-performance storage
Typical deep learning clusters are paired with high-performance (high-bandwidth, high-capacity) storage. They use parallel or distributed filesystems and multi-level caching to enable fast data access and updates.
In-house, we operate distributed storage based on ceph and cephfs. Ceph is an open-source project that lets you robustly build object storage distributed across many nodes. CephFS also provides a POSIX filesystem interface on top.

CephFS consists of RADOS, Ceph's object storage layer, and MDS for metadata operations. Ceph has been a durable solution maintained over a long period and is actively developed. Managed by Red Hat, the CephFS kernel driver is included in the Linux kernel.
Software stack
So far we've talked about infrastructure and hardware; the software stack you build on top is just as important. Let me first introduce two tools used for infrastructure management, starting with Ansible.
Ansible
To manage infrastructure, you need to be able to operate not one or two nodes but dozens—sometimes far more—at once. For this, you need a tool that performs the same task consistently across many nodes. Ansible does exactly that.
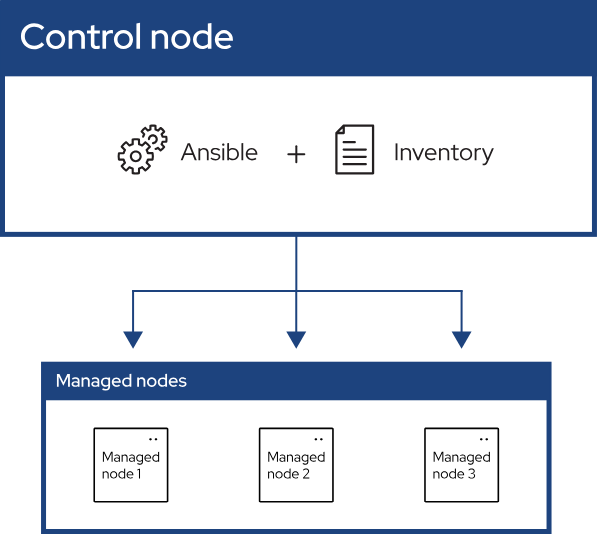
Two big characteristics of Ansible:
- As long as a managed node is reachable over SSH and has Python installed, Ansible works without installing anything extra on that node.
- Operations are idempotent by default—running the same operation n times yields the same end state as running it once.
These two traits make it convenient and consistent to manage large fleets of nodes with Ansible.
Alongside Ansible, Terraform is also widely used for infrastructure. Based on the IaC (Infrastructure as Code) philosophy, Terraform lets you declare and manage resources across multiple clouds like AWS and GCP with code.
ansible galaxy
In Ansible, you bundle units of work into "roles," and then bundle roles into "collections." The community has contributed a huge number of these collections, so you can often accomplish tasks simply by pulling them in—no need to reimplement. You can browse and import these roles/collections via ansible galaxy.
Slurm
When people think "deep learning clusters," many immediately think Slurm. That's largely because Slurm is the interface users directly touch. In reality, Slurm's role is simple—and it does that one job extremely well: it's the scheduler.
To go into a bit more detail, Slurm provides:
- job scheduling & resource allocation:
- It allocates resources by considering job characteristics, the submitting user, group/association, and more.
- parallel job support:
- You can easily parallelize multiple jobs and run them with appropriate resource allocations per job.
- extensive customization:
- It supports a variety of plugins; for example, the container plugin for the Slurm Workload Manager https://github.com/NVIDIA/pyxis.
CORE (Compute-Oriented Research Environment)
CORE is a high-performance GPU cluster currently composed of twelve DGX H100 systems (96 H100 GPUs in total). It is actively used by Maum AI's Brain and WoRV teams for research and development across language, audio, and vision modalities.
How CORE was built
To turn standalone DGX H100s into a single cluster (CORE), we did the following:
- Perform initial environment setup on each node, including SSH settings for Ansible connectivity.
- Apply a common baseline configuration to all nodes. Examples include:
- User/group configuration
- Filesystem setup
- Package installation
- Various environment variables
- Install Slurm
- Deploy monitoring tools
We carried out most of this work with Ansible. By writing playbooks and only tweaking YAML variable files, we made it easy to add/remove/modify nodes freely.
Making CORE convenient to use
The biggest inconvenience when using Slurm is that you cannot directly SSH into compute nodes. From a researcher’s perspective, you used to be able to open VS Code Remote directly on a DGX, spin up a devcontainer, or start a Jupyter Notebook—now you can't, which is frustrating.
Debug/development nodes
Needing direct SSH in the first place can be a sign that you're using an anti-pattern for consuming high-performance resources via Slurm. The reason people fall into this anti-pattern is usually the lack of separate nodes dedicated to debugging/development.
We plan to add dedicated debug/development nodes, but we don't have them yet.
Of course, only SSH is restricted—other commands are not. With a few extra commands, you can still do everything mentioned above: you can connect to a compute node and launch a new SSH daemon, or start a Jupyter Notebook server and access it, and so on. Still, it's undeniably less convenient than before. In research and development—where fast and flexible workflows are paramount—these "small" frictions can become bottlenecks.
Fortunately, Slurm already has a feature to address this: the pam_slurm_adopt module. When enabled, a user who has pre-allocated specific resources on a specific node can SSH directly into that node and see only those resources. If you have multiple allocations, the most recently allocated resources are the ones visible.
With pam_slurm_adopt, you simply request resources first using sbatch/srun/salloc, then SSH in. From there, everything works: VS Code Remote connections, even running Jupyter Notebook right inside VS Code.
Also, many existing users rely heavily on Docker, but Docker is not ideal for HPC. Each node stores images and caches in its own private space, wasting capacity, and when you submit multiple jobs to a single node, you end up with that many containers. To address this, there's a container solution called enroot, and NVIDIA provides pyxis as a Slurm plugin for enroot.
Wrapping up...
That's a brief introduction to the background, the stack, and the process behind building CORE.
Some may wonder why someone from the WoRV team is leading the CORE project and writing this post. It's because the multimodal data we handle requires moving and processing massive volumes of data quickly and efficiently.
In the near future, we'll likely be running training at fairly large scales—on par with what people commonly call pretraining—for multimodal agents. You can think of building CORE as laying the groundwork for that.
The WoRV team is actively hiring. We're looking for people who want to do exciting research with us. Thank you.