[EN] Diving into Minecraft Embodied AI: Exploring Recent Research in Team CraftJarvis

Hello, I’m Jaeyoon Jung, a Senior AI Researcher at Maum AI, currently working in the WoRV team on a SketchDrive-based autonomous driving commercialization project.
In this post, I introduce Embodied AI research in the Minecraft environment. To help you understand the latest Minecraft AI work, I first outline must-know foundational papers, then focus on research from the field-leading CraftJarvis team.
I’ve added short explanations so readers who haven’t played Minecraft can follow along. I’m still learning this area, so please excuse any inaccuracies—feedback and coffee chats or email are always welcome.
"An agent that can behave and live in an environment."
By this definition, an agent operating within the Minecraft environment is Embodied AI. If these terms or tasks are unfamiliar, the linked primer helps.

Embodied AI for Minecraft Because...

Why researchers move from chess, Go, Atari, Mario, and StarCraft AIs to Minecraft Embodied AI?
Minecraft is hard to play
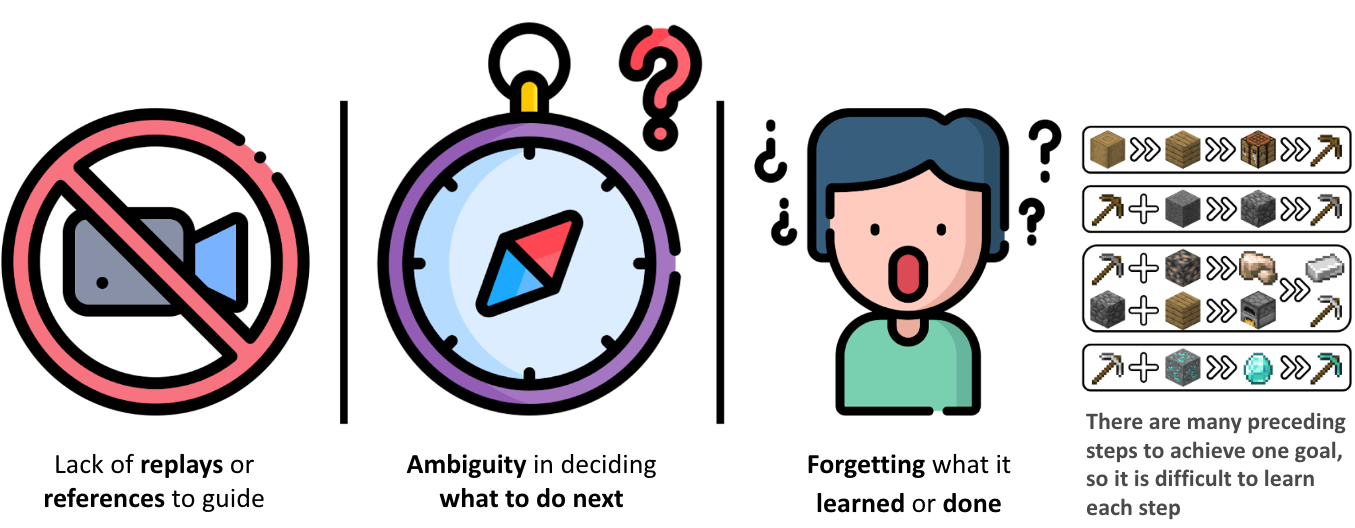
- There’s lots of video but no comprehensive logs of human inputs (WASD, mouse movement, etc.).
- As a sandbox game, there’s no single explicit objective or uniquely correct next task.
- You must remember what you’ve done/achieved to proceed.

For example, crafting a diamond pickaxe varies widely with the player’s state, and the subtasks change accordingly:
To make a diamond pickaxe, you need diamonds → diamond ore spawns underground and requires an iron pickaxe → to get an iron pickaxe, smelt iron in a furnace → I think I have iron, but no furnace → and I lack stone... This looks like a plains biome; if I dig down with a stone pickaxe, I’ll get stone.
Task: Go down and mine stone.
Minecraft has diverse biome(environment)

Minecraft has diverse biomes and tasks, enabling tests of generalization (e.g., training in plains and testing in jungle). You can hunt, farm, build, and more. Following VPT, most work chooses quantifiable goals (like crafting a diamond pickaxe).
Minecraft has diverse task

In Minecraft—an open sandbox game that encourages unrestricted creativity—players can engage in a wide range of activities, such as hunting monsters, farming, and constructing buildings. Among these, most research efforts following the VPT framework have focused on tasks that enable quantitative evaluation, such as achieving objectives like crafting a diamond pickaxe (e.g., success probability of reaching the state where diamonds are mined, or how quickly diamonds are collected).
However, Minecraft contains an extensive variety of tasks, along with numerous types of monsters, craftable items, and complex crafting recipes. Because of this diversity, developing a Minecraft AI that behaves like a human and performs all tasks remains a highly challenging problem.
For these reasons, research on Embodied AI within the Minecraft environment continues to be highly active and rapidly evolving.
Previous Work (Need to Know History)
To better understand recent advancements in Minecraft AI research, I will first briefly summarize the essential contributions of several foundational papers, focusing only on the key points relevant to this work.
Previously on VPT
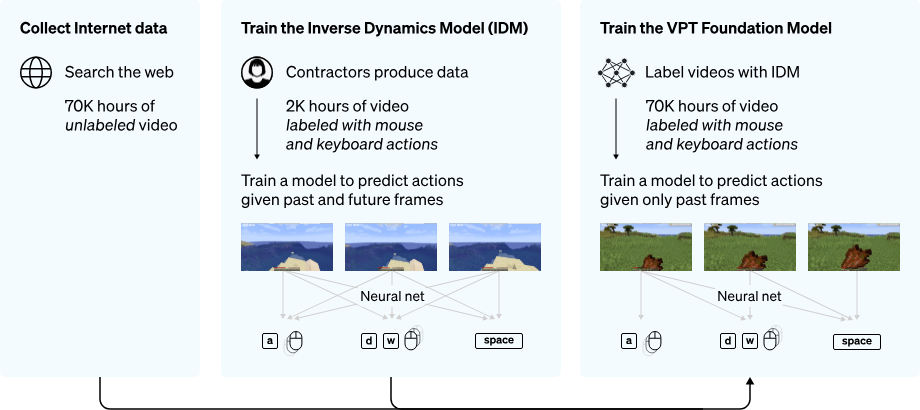
Before announcing ChatGPT, OpenAI introduced the VPT (Video PreTraining) model, which was trained using Minecraft gameplay videos. VPT attracted significant attention because it demonstrated substantially stronger performance compared to prior Minecraft research.
A key idea behind VPT is leveraging large-scale gameplay videos as training data. These videos contained no labels—meaning they did not include records of human actions such as keyboard or mouse inputs. To address this, VPT used a model-based labeling approach to construct a large action-labeled dataset from unlabeled video recordings.
The process is as follows:
- Human contractors collected approximately 2,000 hours of expensive data that included both video and synchronized keyboard/mouse action logs.
- Using this dataset, VPT trained an IDM (Inverse Dynamics Model), which predicts the current action based on past and future video frames.
- The trained IDM was then used to label about 70,000 hours of gameplay videos sourced from the Internet.
- A pretrained model capable of performing basic actions in Minecraft was trained using this newly labeled dataset.
Through this pipeline, VPT successfully learned human-like behavior in the Minecraft environment. However, to perform specific tasks, the model requires additional fine-tuning—similar to how LLMs are adapted for downstream tasks.
To enable task execution, VPT applied behavior cloning using videos of humans building houses or tutorial gameplay, and reinforcement learning with step-by-step rewards for tasks like crafting a diamond pickaxe. As a result, VPT achieved significantly better performance than previous work, successfully crafting a diamond pickaxe with a 2.5% completion rate—something previously considered infeasible.
Nevertheless, VPT has limitations: it cannot directly follow human instructions or conditions, and supporting new instructions requires collecting task-specific data for additional fine-tuning.
Previously on STEVE-1
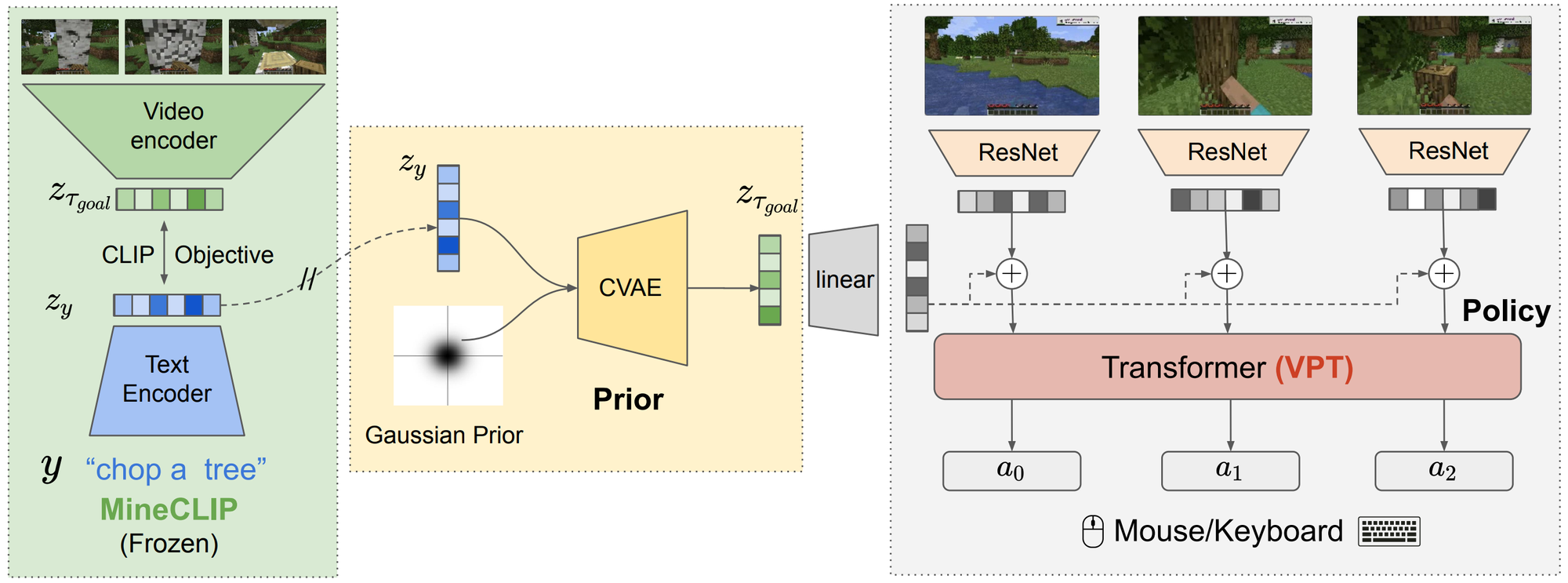
To overcome the limitations described above, the STEVE-1 paper introduced an instruction-following Minecraft agent built on top of VPT. STEVE-1 incorporated visual goals as conditioning inputs, enabling the model to follow human instructions.
STEVE-1 leveraged MineCLIP, a contrastive learning model tailored for Minecraft. By passing goal videos through the MineCLIP Video Encoder, STEVE-1 produced visual goal embeddings, which correspond to embeddings that can also be generated from text using the MineCLIP Text Encoder.
However, since visual goal embeddings were used as conditions during training, using textual instructions at inference time requires converting the text-goal embedding into the corresponding visual-goal embedding. To address this challenge, STEVE-1 employed a CVAE architecture that transforms textual goal embeddings into their visual-goal counterparts.
As a result, STEVE-1 became capable of following both video- and text-based instructions, allowing it to execute keyboard and mouse actions based on high-level goals. Due to these capabilities, STEVE-1 is often used as a low-latency controller conditioned on goal states in subsequent research alongside the modified VPT model.
Previously on Voyager
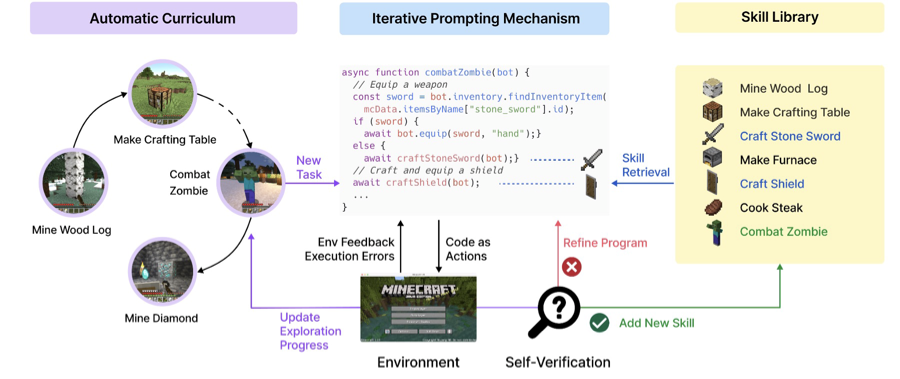
Unlike the previously discussed works, which perform low-level control—including keyboard and mouse operations—in an end-to-end manner, Voyager takes a different approach. Rather than generating raw actions, Voyager interacts with the Minecraft environment using function-like API calls. The internal implementation of Voyager shows that it uses Mineflayer, a JavaScript-based Minecraft API, through which specific behaviors are defined as JavaScript functions called skills.
In Voyager’s pipeline, a sequence of actions needed for a task is expressed as a function, which is then executed to attempt the task. If the function successfully completes the task, it is stored in a skill library for later reuse. In this way, Voyager behaves like an LLM-based agent that performs function calls: it can either call previously learned skills or generate new ones necessary to solve the task. This approach treats reasoning and planning through prompting with an LLM such as GPT, and can be viewed as a function-calling agent or code-generating agent paradigm.
Personally—and as a team—we believe that delegating low-level control to an external API falls within the category of function-call LLM agent research, which is fundamentally different from the embodied AI research direction we aim to pursue.
For example, consider an end-to-end approach to a task like Combat Zombie. The agent must first perform planning based on visual understanding (e.g., determining whether a weapon is available, evaluating health status, analyzing the enemy's location). Then, it must execute real-time actions such as mouse-tracking to follow the zombie’s position, moving using keyboard inputs, and swinging the sword through precise mouse clicks—requiring tight integration of perception, reasoning, and motor control under dynamic conditions.
In contrast, in API-based Minecraft AI like Voyager, the process is greatly simplified. After planning, the LLM issues high-level commands such as “equip a weapon from inventory” or “attack the nearest zombie.” The underlying API automatically handles movement toward the zombie, optimal positioning, and weapon swinging as soon as the target is in range—effectively enabling near-perfect execution similar to a cheat-like gameplay mechanism, which is only possible due to the existence of game-level privileged control.
For these reasons, our team focuses on end-to-end learning approaches that directly generate low-level actions, aiming to build models capable of operating in real environments rather than relying on privileged API control as seen in Voyager.Previously on Ghost in the Minecraft
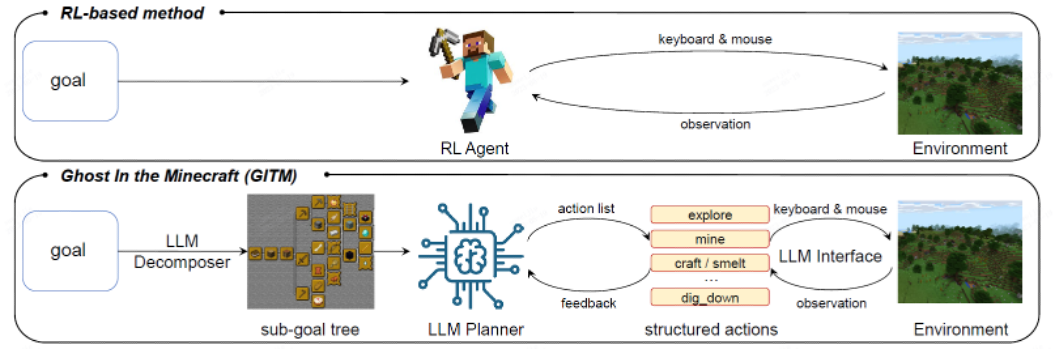
Traditional RL-based methods relied on agents directly attempting to execute complex goals. However, GITM argues that this structure leads to low success rates when tasks become highly complex, and instead introduces a method that decomposes objectives into smaller steps using an LLM.
For example, when given the instruction “Mine diamonds!”, previous methods would provide the agent with the goal “diamond mining” directly and expect it to carry out the task end-to-end. In contrast, GITM employs an LLM Decomposer to break this high-level objective into more manageable sub-goals.
The goal “diamond mining” is decomposed into sequential steps such as:
collect wood → craft wooden pickaxe → craft stone pickaxe → craft iron pickaxe → mine diamonds.
Using these decomposed sub-goals, the system creates a structured plan, and the agent completes the task by sequentially following the plan. Through this design, GITM demonstrates significantly higher success rates on complex goals compared to traditional approaches.
Team CraftJarvis
Now that we have reviewed the fundamentals and overall progression of Minecraft AI research, we will explore the major works conducted by the CraftJarvis team, which specializes in Minecraft agent research.
Team CraftJarvis: GROOT
The first paper we will examine from the CraftJarvis team is GROOT. GROOT is an embodied AI model that takes a gameplay video demonstrating the completion of a specific goal as input and learns to perform the same goal within the Minecraft environment.
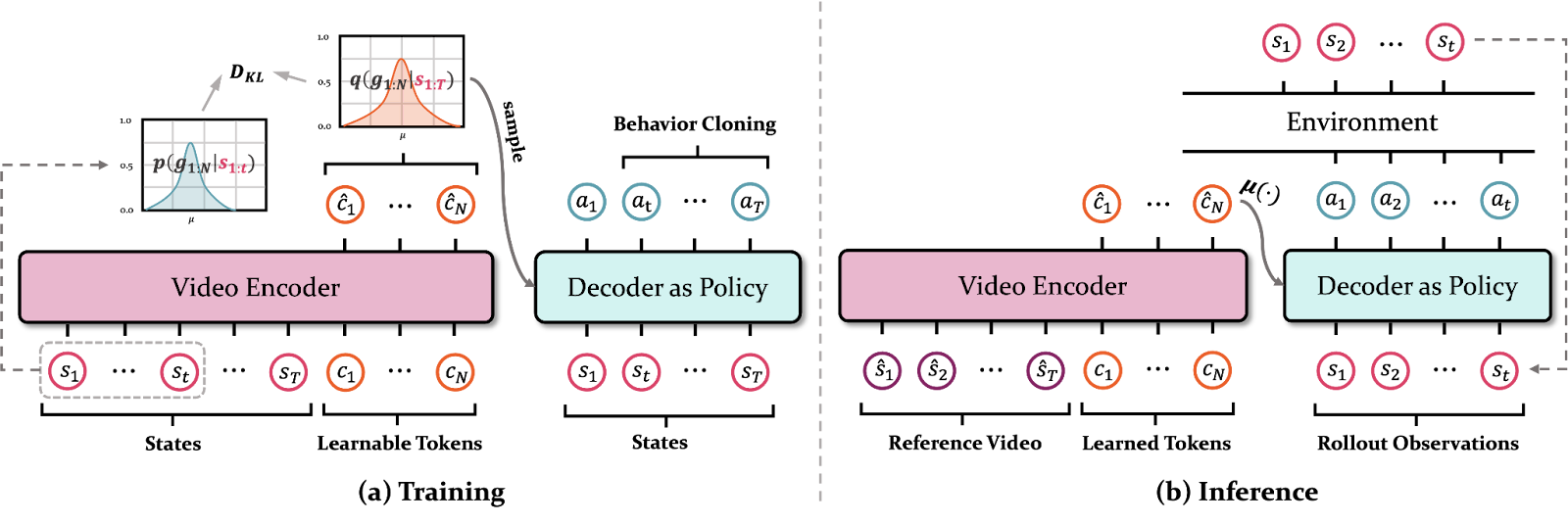
GROOT is designed with an encoder–decoder architecture. During training, the input gameplay video is used to train the encoder to extract a meaningful goal embedding, while the decoder learns to produce appropriate actions based on both the goal embedding and the current state of the environment.
The decoder of GROOT is based on a modified version of VPT. In the original VPT framework, the model can only receive observations and has no mechanism to incorporate conditioned information such as goal embeddings. To address this limitation, GROOT augments the Transformer-XL layers used in VPT with a gated cross-attention dense layer, enabling the decoder to integrate goal information. In this mechanism, environment states serve as keys, while the goal embedding functions as the query and value.
Once trained, GROOT extracts a goal embedding from a reference gameplay video at inference time. It then performs actions by conditioning on this embedding and the observed environment state.
A key advantage of GROOT is that it interprets the reference video itself as the instruction, eliminating the need for textual annotations specifying the goal of each training video. However, the limitation is that inference requires the presence of a reference video that demonstrates the desired task, meaning the agent cannot follow instructions without an explicit example video.

GROOT’s action space is divided into mouse and keyboard components, similar to how humans control the game. An important implementation detail is the prevention of null actions—actions where the agent does nothing. To avoid this issue, GROOT adopts a joint hierarchical action space, following VPT’s approach.
Preventing null actions is more critical than it may initially appear. Unlike humans, the model has no innate understanding of when to resume acting after performing no action, which can cause the agent to freeze indefinitely during training or inference.
In fact, Appendix C of the OpenVLA paper highlights a similar challenge. The BridgeData dataset contains a substantial number of all-zero (null) actions. Because the RT-2-X model was trained without filtering out these actions, the model frequently predicted an all-zero action token. To mitigate this, the authors report using the second-most-likely action (top-2 token) during inference—otherwise, the agent would continually output null actions and remain motionless.
Regarding the structure of GROOT’s action space:
- The Button Space is composed of all combinations of keyboard operations, along with a flag indicating whether the mouse is being used, resulting in a total of 8,461 actions.
- The Camera Space discretizes mouse movement into 121 possible actions.
Therefore, the agent’s action head outputs a vector with dimensions 8,461 (button space) and 121 (camera space).
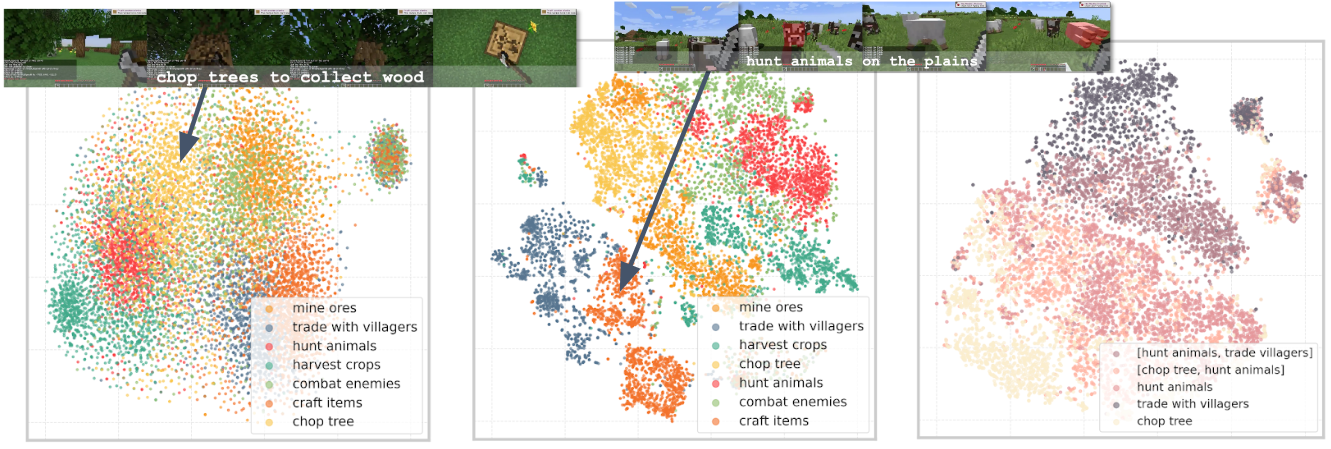
To effectively deliver instructions to the decoder using goal embeddings, the embeddings must accurately capture the semantic meaning of the goal. To evaluate this, GROOT visualizes the goal embedding space using t-SNE.
The visualization is presented in three parts:
- The left shows the goal space generated from a randomly initialized video encoder.
- The middle shows the goal space learned through GROOT’s training.
- The right shows the goal space when videos containing two goal states are merged.
From the results, we observe that the goal space trained with GROOT forms much clearer clusters of semantically similar goals compared to the randomly initialized encoder. Additionally, embeddings representing videos that contain two different goals are positioned between the corresponding clusters, indicating that the goal embedding effectively reflects the combined semantics.
These findings confirm that GROOT successfully learns goal embeddings that meaningfully encode the intended goal, enabling the agent to act based on this representation.
Team CraftJarvis: JARVIS-1
Next, we examine JARVIS-1. JARVIS-1 progresses through tasks in a staged manner using the Minecraft tech tree, which is similar to the goal decomposition strategy seen in GITM. As shown in the example video above, JARVIS-1 treats a task as the final objective and a goal as a sequence of sub-objectives required to achieve that final target, executing instructions step by step accordingly.
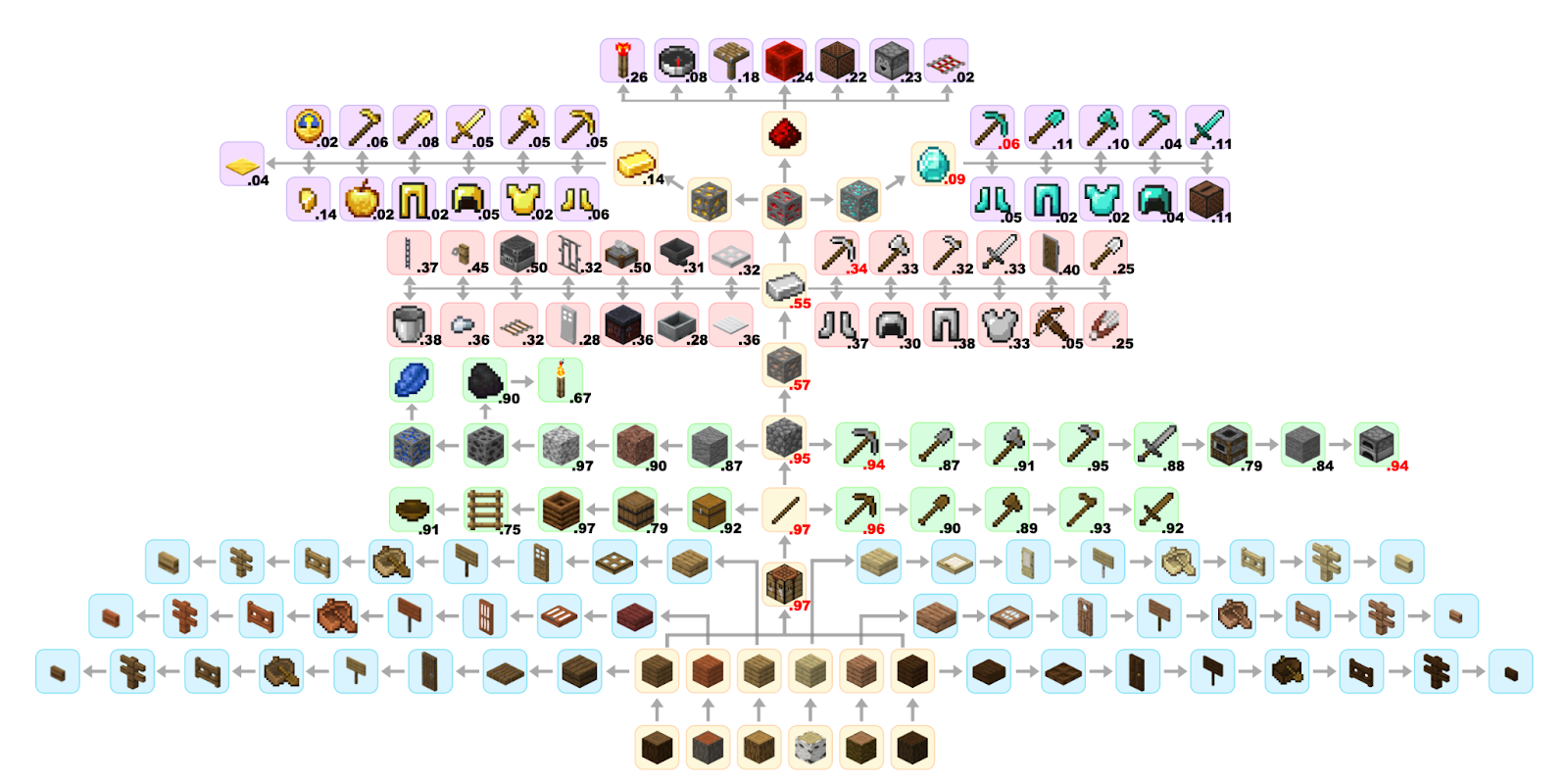
Even from the tech tree alone, tasks such as obtaining redstone or crafting gold items are highly challenging, requiring the collection of more than ten intermediate items. Crafting a diamond pickaxe is also considered a difficult task, yet JARVIS-1 achieves a 6% success rate, outperforming VPT.
How does JARVIS-1 achieve such strong performance and demonstrate the ability to craft a wide variety of items?
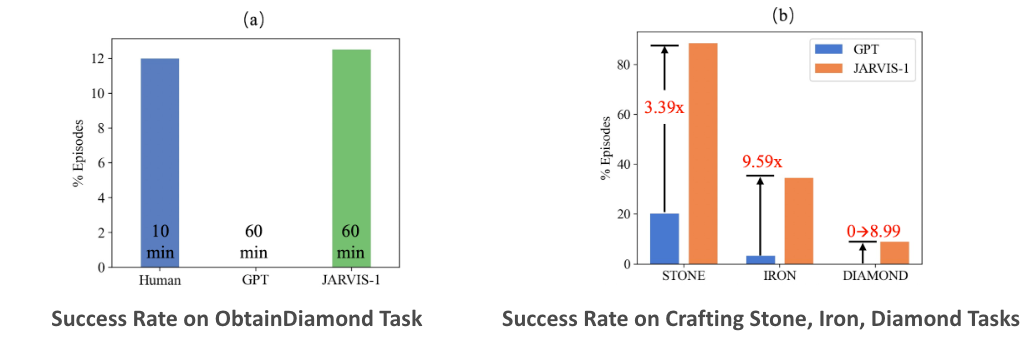
JARVIS-1 leverages Situation-Aware Planning, meaning that it generates plans based on the current state of the environment. Although this may sound obvious from a human perspective, it is a crucial capability for an autonomous agent.
For example, a common method for crafting a bed in Minecraft is to obtain string by defeating spiders and to gather wool by killing sheep. However, if the agent already has shears in its inventory, it can shear sheep to collect more wool more efficiently. Likewise, if the agent is located in a village, it can trade with villagers to acquire the necessary materials.
As another example, consider a scenario where a tool breaks while mining for a target resource. In such a situation, the agent must prioritize crafting a new pickaxe before continuing to mine. Otherwise, it would attempt to mine barehanded—something that makes it impossible to ever obtain the resource.
This concept is not entirely new. Both Voyager and GITM implement similar mechanisms where error messages or feedback during execution are used to adjust plans dynamically, allowing the agent to modify its actions mid-task in a human-like manner depending on the situational context.
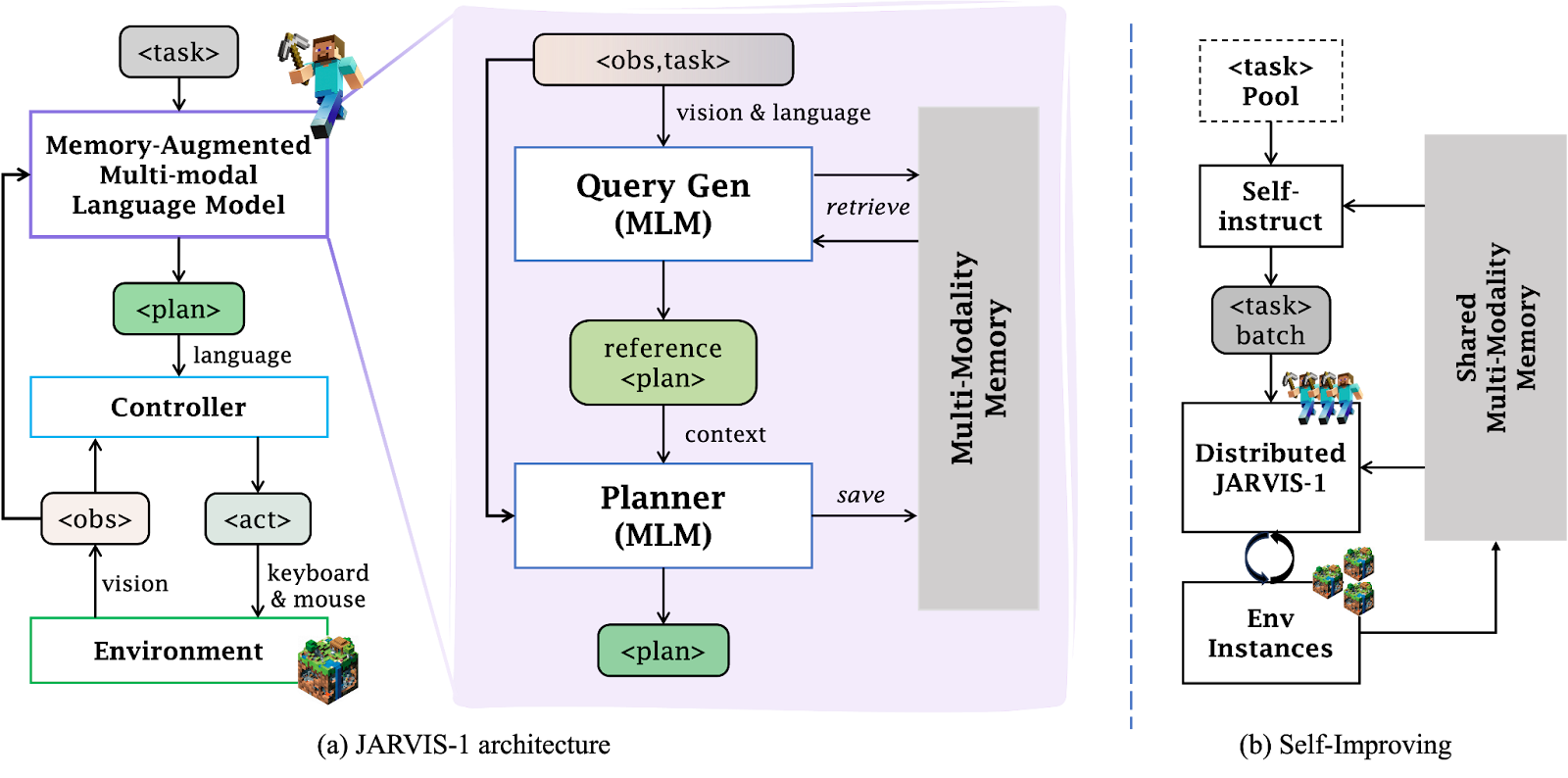
The architecture of JARVIS-1 consists of two main components: a Planner and a Controller. The focus of the JARVIS-1 paper is primarily on the Planner, while the Controller is left unchanged. Within the Planner, a retrieval mechanism is introduced.
When a task instruction is given, the Planner first performs reasoning through a Query Generation module to determine what is required to accomplish the task. It then searches for relevant successful experiences stored in the Multi-Modality Memory, retrieves them, and uses the retrieved examples as references to construct a plan.
In addition, all attempts to complete a task—whether successful or failed—are stored within a unified Shared Multi-Modality Memory structure. This enables the agent to leverage past failures as learning signals, allowing self-improvement over multiple attempts. If the agent fails on the first try, it can revise its plan based on the unsuccessful experience and attempt again more intelligently.
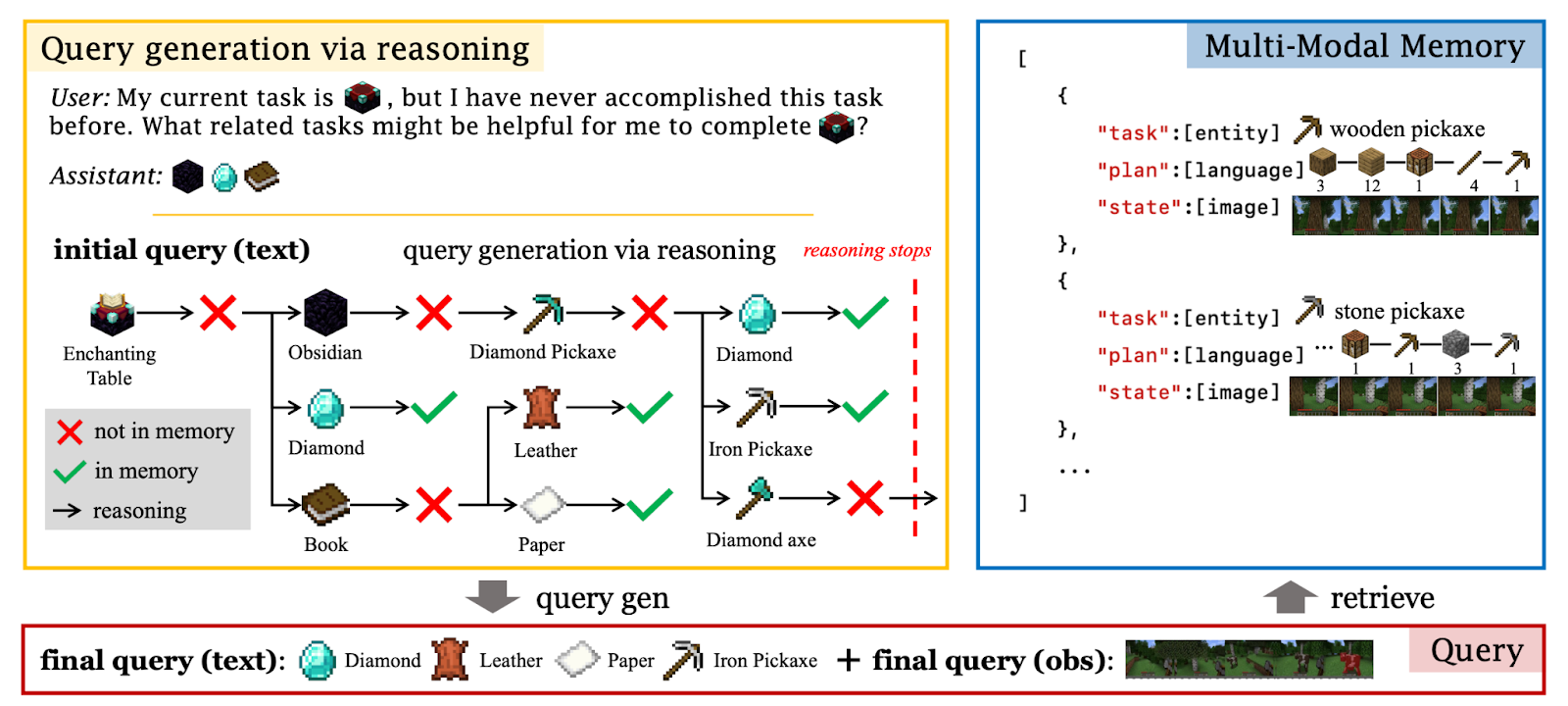
In the example illustration, JARVIS-1 determines which sub-goals are necessary to accomplish the given task based on the current situation. If the memory contains past successful experiences for the required sub-goal, the system retrieves and utilizes those experiences to guide the plan.
Importantly, the more successful examples stored in the Multi-Modal Memory, the better the model performs. Therefore, JARVIS-1 records every successful experience in memory along with the corresponding task, plan, and state information.
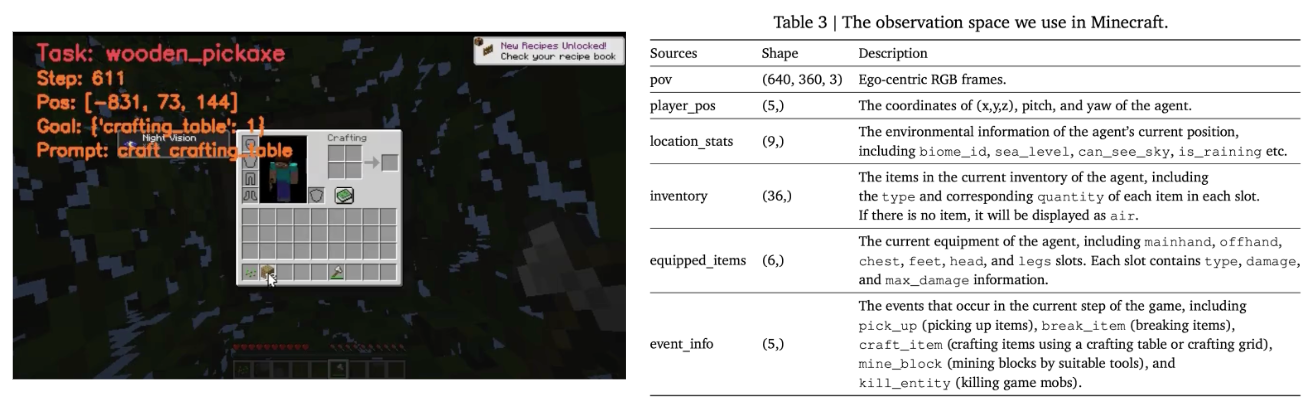
Unlike many previous approaches that rely on privileged observations such as Minecraft X-ray or LiDAR features to gain an advantage, JARVIS-1 operates solely on raw RGB pixel inputs. By doing so, JARVIS-1 perceives the environment in a manner more similar to humans and achieves tasks without depending on additional game-engine information. This design enables the development of a more realistic and human-aligned Embodied AI system.

Examining the experimental results, JARVIS-1 demonstrates strong performance across a variety of biomes (environment types) and shows clear self-improving behavior through the use of the Shared Multi-Modality Memory.
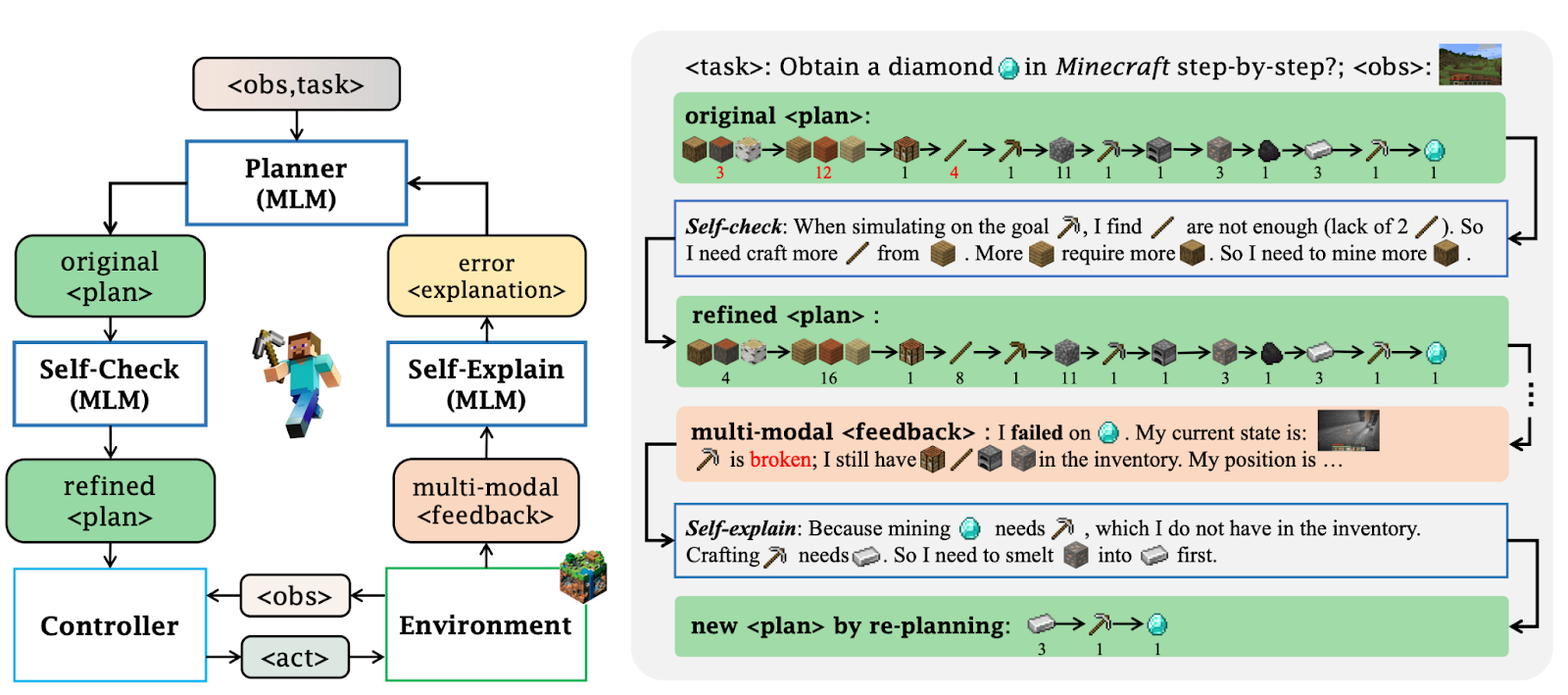
As mentioned above, JARVIS-1 employs Situation-Aware Planning. When the agent fails to achieve a goal, it receives feedback about the failure and performs reflection and re-planning based on that information. Through this iterative improvement process, JARVIS-1 consistently increases its success rate, demonstrating strong and adaptive performance.
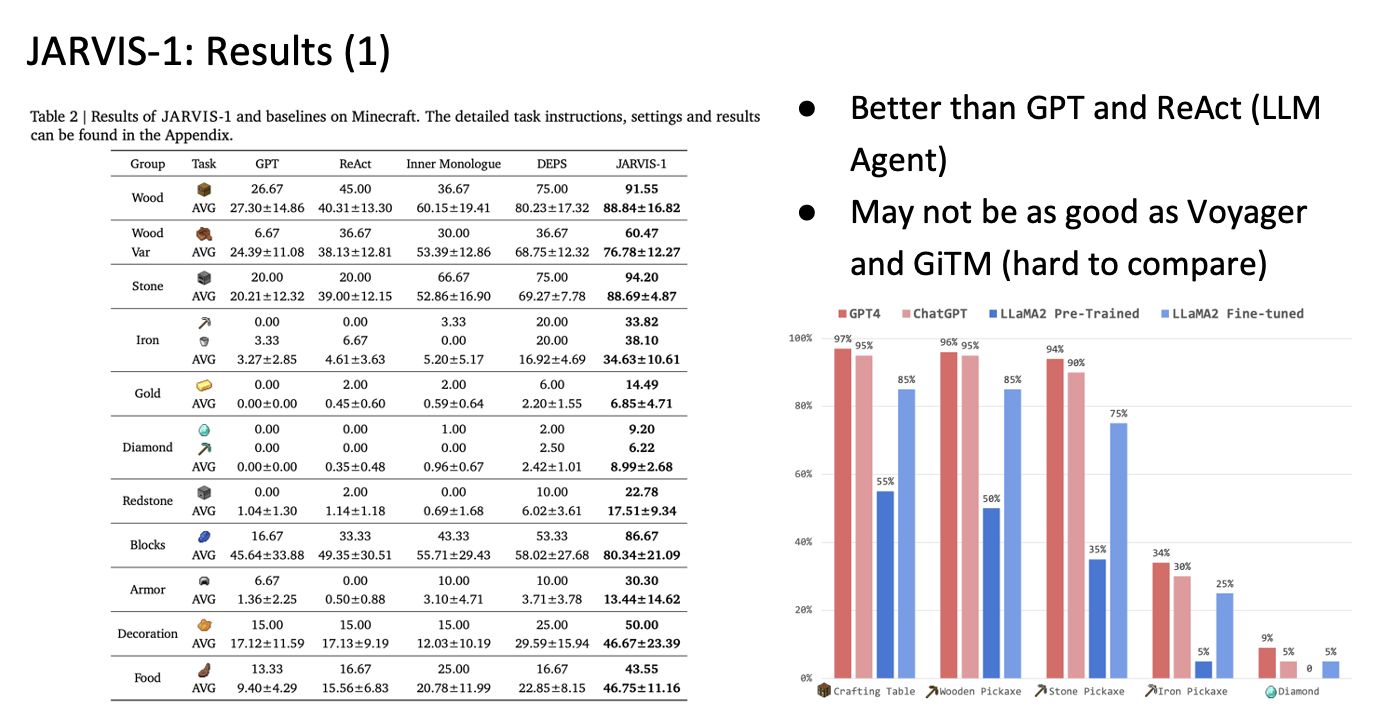
Since JARVIS-1 delegates the Controller component to an existing model—similar to LLM agent architectures—the paper compares performance primarily with approaches such as GPT and ReAct in Table 2. The authors note that they do not compare against Voyager or GITM due to significant architectural differences, which make direct comparison difficult (e.g., GITM relies on LiDAR-based observations, resulting in substantially different implementations).
The results show that success rates increase proportionally with the capability of the underlying LLM, and the best performance is achieved when using GPT-4. (As a side note, it is unclear why the authors chose to include the LLaMA-2 Pretrained model as a baseline for comparison.)
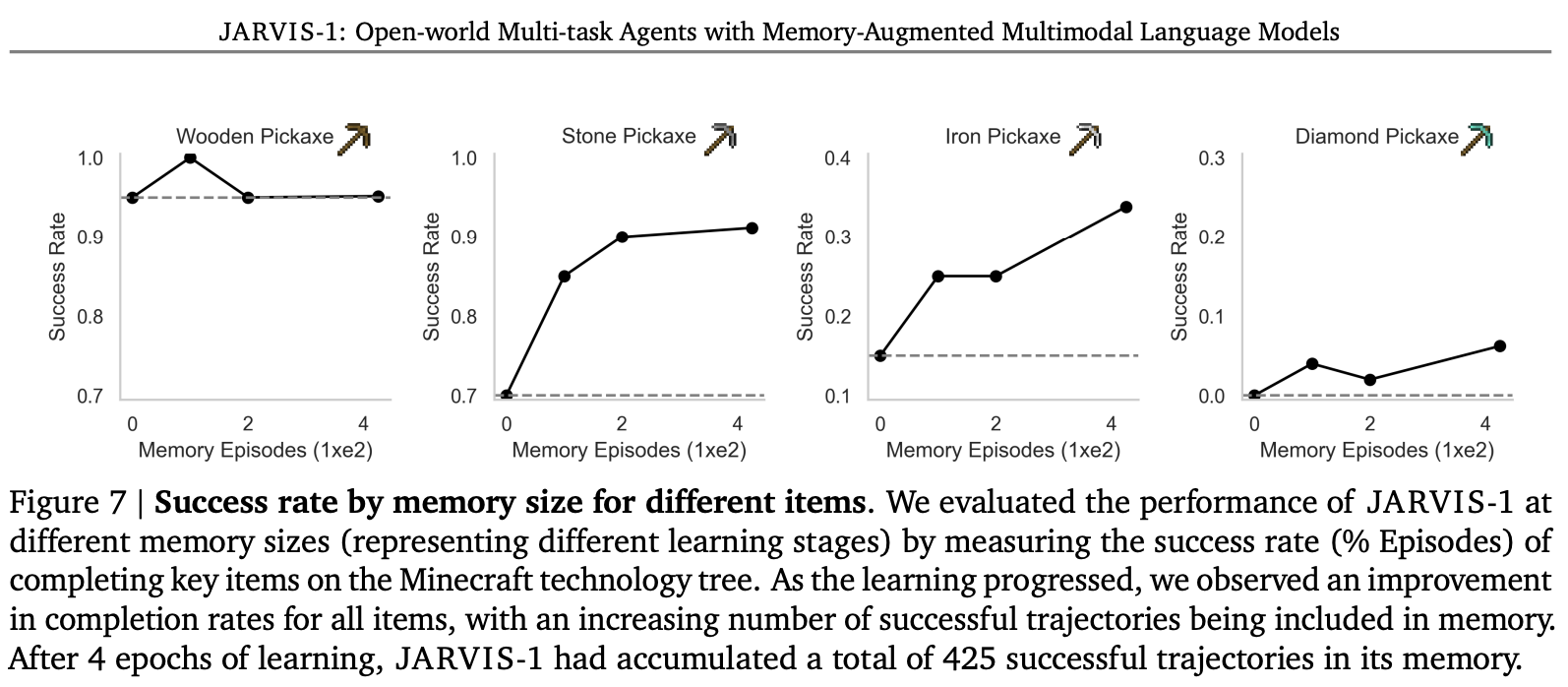
It was also observed that the larger the Multi-Modality Memory—which stores successful experiences—the better the model performs on increasingly challenging tasks.
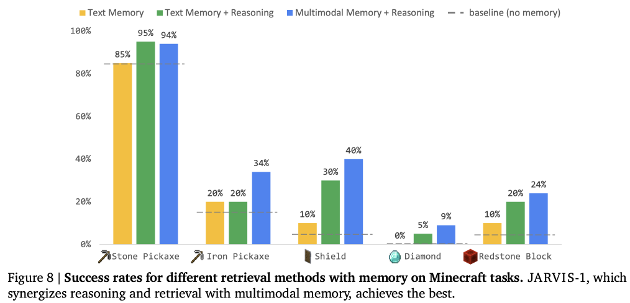
The experiments also show that when retrieving from memory, using both image and text modalities together yields the best performance, outperforming retrieval methods that rely on a single modality.
Independent of the experimental results, we examined the Implementation Details to understand what type of controller JARVIS-1 relies on. For two representative Minecraft tasks—mining and crafting—JARVIS-1 adopts different approaches.
For the mine task, JARVIS-1 utilizes STEVE-1, providing text instructions directly to STEVE-1 to perform the mining operation.
In contrast, for the craft task, the system adopts an approach similar to MineDojo. Rather than performing drag-and-drop actions with crafting materials, the agent simply calls functions such as craft(4 wood plank, crafting table), and the environment automatically completes the crafting process.
Therefore, while JARVIS-1 is capable of executing a wide range of Minecraft tasks and demonstrates higher performance than other agents, it also exhibits a significant bottleneck due to heavy dependence on the controller’s capabilities. Even the paper acknowledges that improving the controller—by providing more detailed instructions or enhancing its instruction-following ability—is necessary for further progress.
Team CraftJarvis: OmniJARVIS
Perhaps recognizing the limitations of JARVIS-1, the CraftJarvis team released OmniJARVIS as their next major system. OmniJARVIS is designed to overcome the shortcomings of JARVIS-1 and provide significantly stronger situational understanding and task execution capabilities. Unlike JARVIS-1, OmniJARVIS addresses not only the Planner component but also the Controller, offering a more comprehensive end-to-end solution.
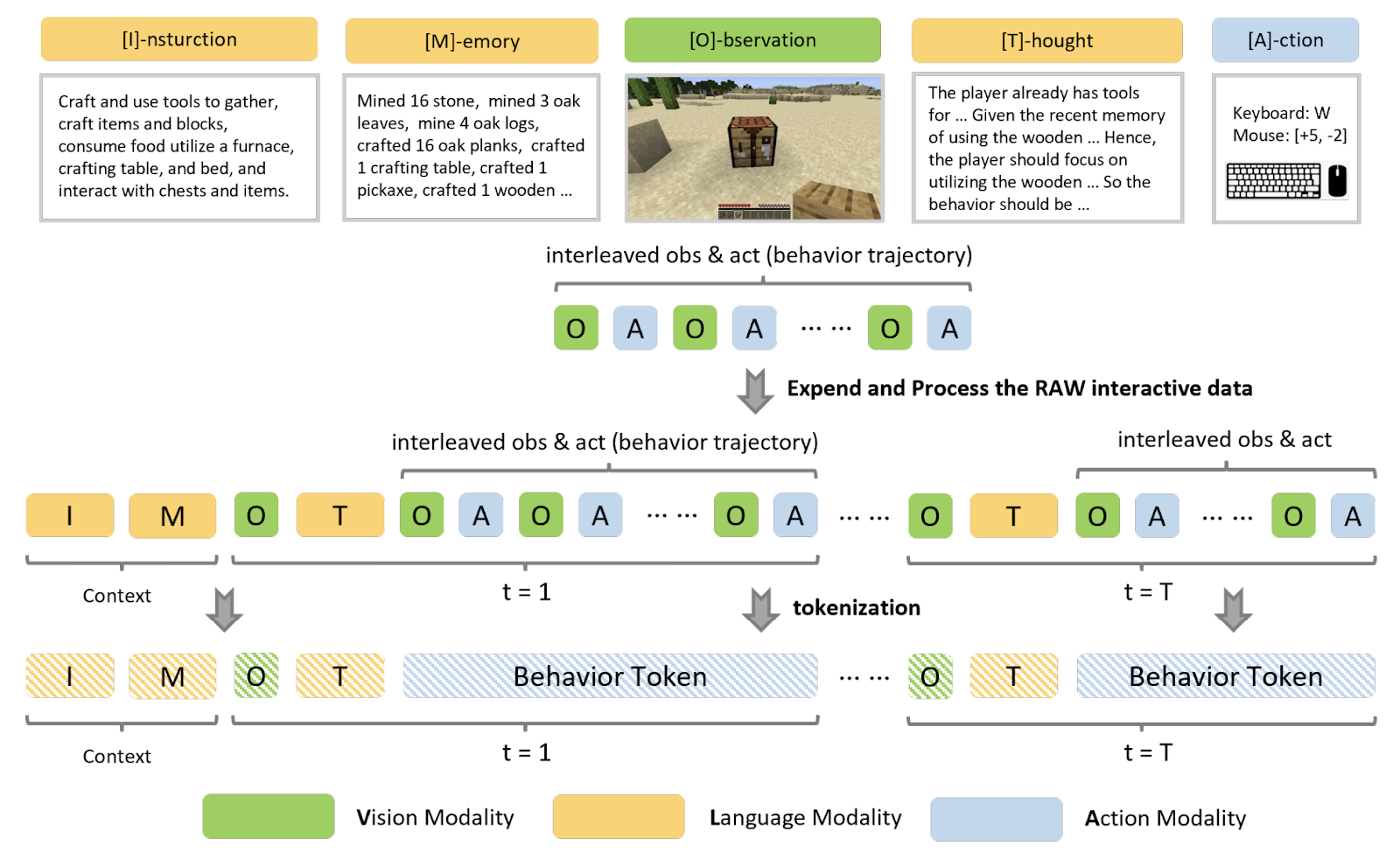
Fundamentally, OmniJARVIS is a VLA (Vision–Language–Action) model, which autoregressively predicts sequences that include vision (observations), language (instructions, memories, thoughts), and actions (behavior trajectories).
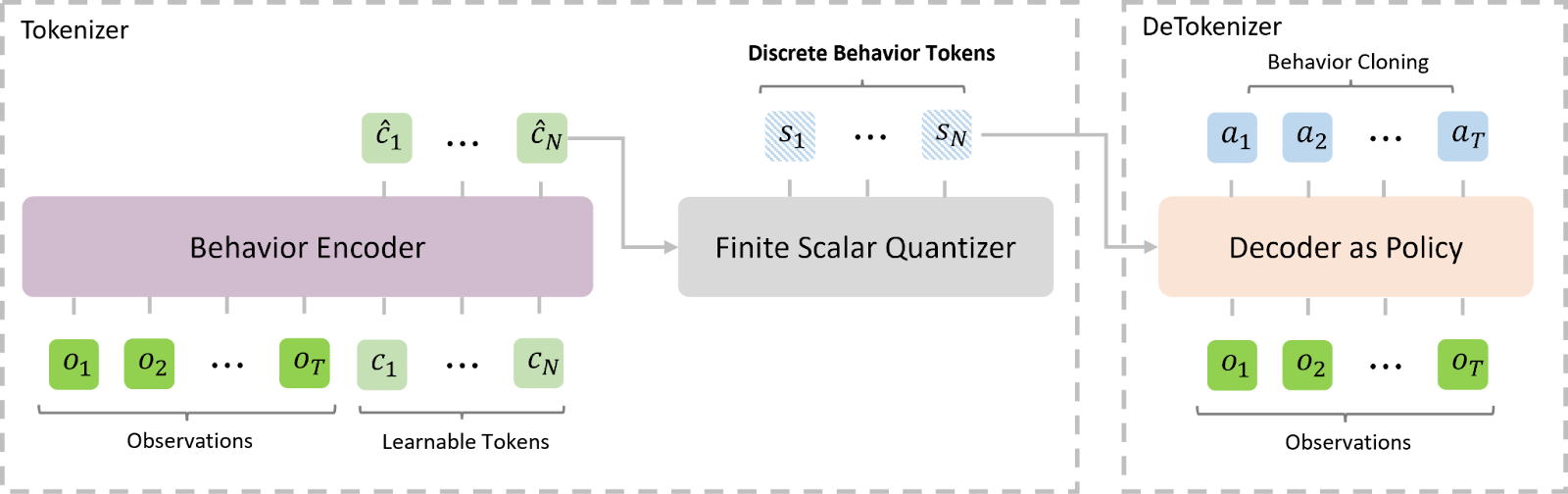
The behavior tokens in OmniJARVIS are designed to more effectively bridge the Planner and Controller. Specifically, the behavior encoder converts the actions required to accomplish a goal into discrete behavior tokens, enabling structured and interpretable action representation.
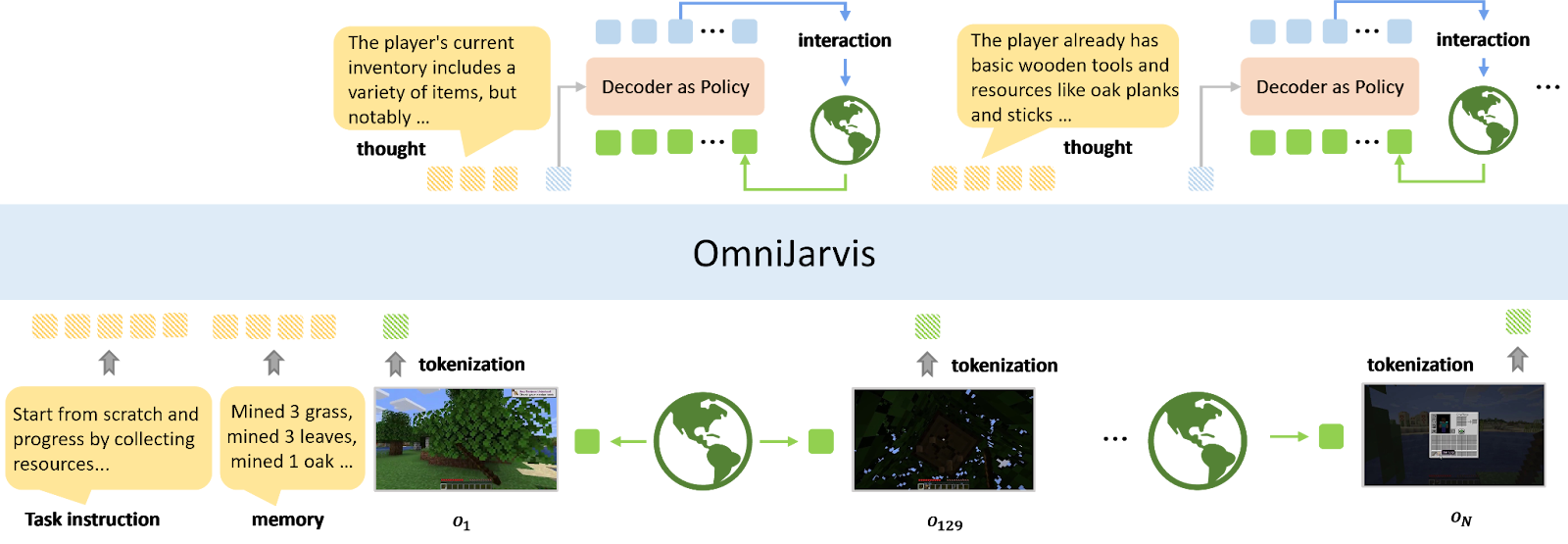
When examining the overall architecture of OmniJARVIS, it can be understood as a multimodal language model enhanced with behavior tokens.
The workflow operates as follows:
- Input — OmniJARVIS receives the task instruction, initial memory, and observation as input.
- Reasoning — Based on these inputs, OmniJARVIS performs chain-of-thought reasoning to generate behavior tokens that determine the agent’s actions.
- Execution — The generated behavior tokens are passed to the Decoder, which interacts with the environment for 128 steps.
- Iterative loop — After 128 steps, OmniJARVIS observes the resulting state and again performs chain-of-thought reasoning to produce new behavior tokens.
This loop repeats, continually updating plans and actions until the task is successfully completed.
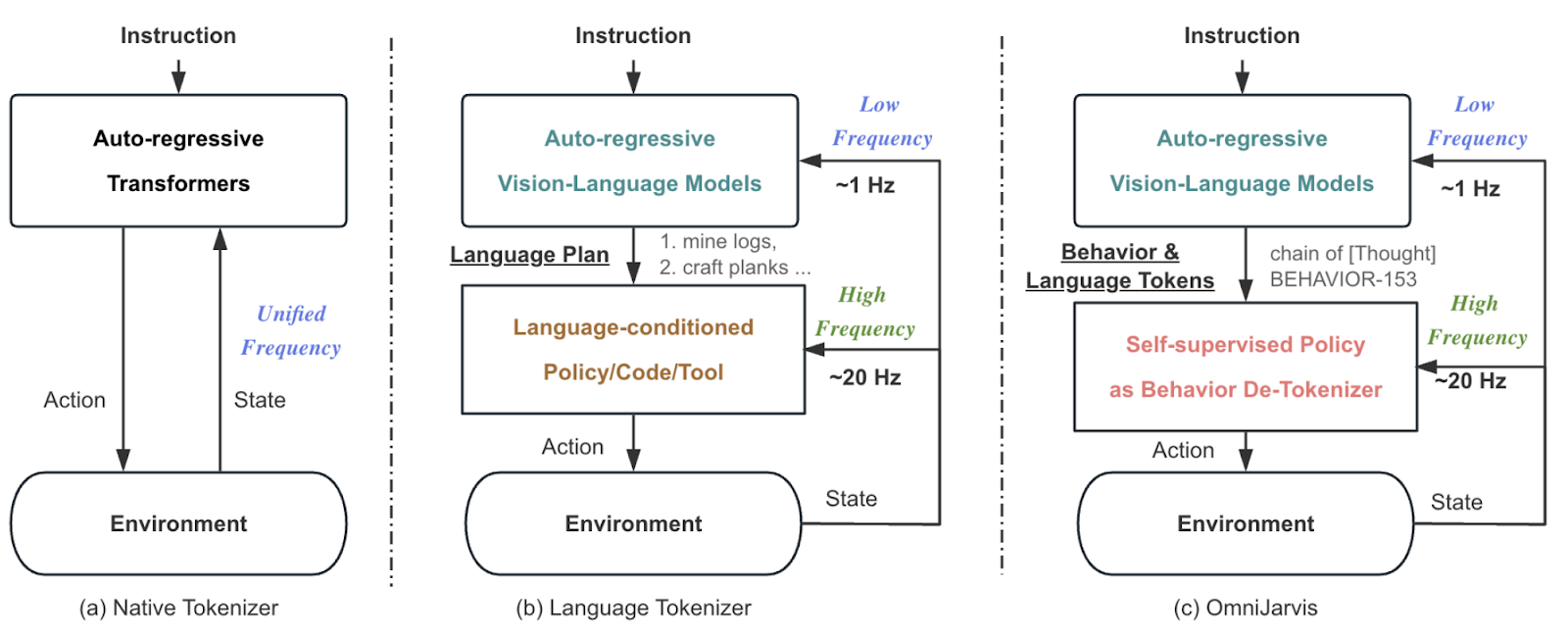
OmniJARVIS outlines the distinctions between existing architectures and its own design as follows:
(a) VPT (small model): weak reasoning ability but fast interaction speed (~20Hz) / RT-2 (large model): strong reasoning ability but slow interaction speed (~2–3Hz)
(b) JARVIS-1: performs planning using vision–language models and outputs language-based goals. A language-conditioned policy then translates these language goals into actions at a real-time rate of 20Hz, while high-level models re-plan at <1Hz. Because the training of high-level VLM planners and language-conditioned controllers are separated, this approach performs poorly on tasks that cannot be easily expressed in language.
(c) OmniJARVIS: follows a similar hierarchical structure to (b), but introduces a self-supervised encoder-decoder policy and FSQ quantization as a behavior tokenizer.
Architectures like (a) rely on autoregressive Transformers that directly interact with the environment. This structure enables fast interaction when using a small model—like VPT—but suffers from weak reasoning capability. Conversely, when using a large model such as RT-2, reasoning becomes much stronger, but interaction speeds become too slow for real-time control.
To alleviate this trade-off, models preceding OmniJARVIS adopted the (b) architecture. In this structure, a large model performs reasoning and planning, while a fast Controller executes low-level interactions in real time. The Controller—similar to STEVE-1—receives plans in language form and converts them into actions. This design strengthens reasoning while maintaining fast interaction, but it has a notable limitation: because the VLM planner and controller are trained separately, the system struggles with tasks that are difficult to express in natural language.
To address these limitations, OmniJARVIS (c) introduces a self-supervised encoder-decoder policy along with an FSQ-quantized behavior tokenizer. The resulting behavior tokens are inserted directly into the training data of the vision–language–action model, enabling end-to-end inference. According to the authors, this approach operates effectively without external language supervision and greatly improves scalability and performance on complex tasks.
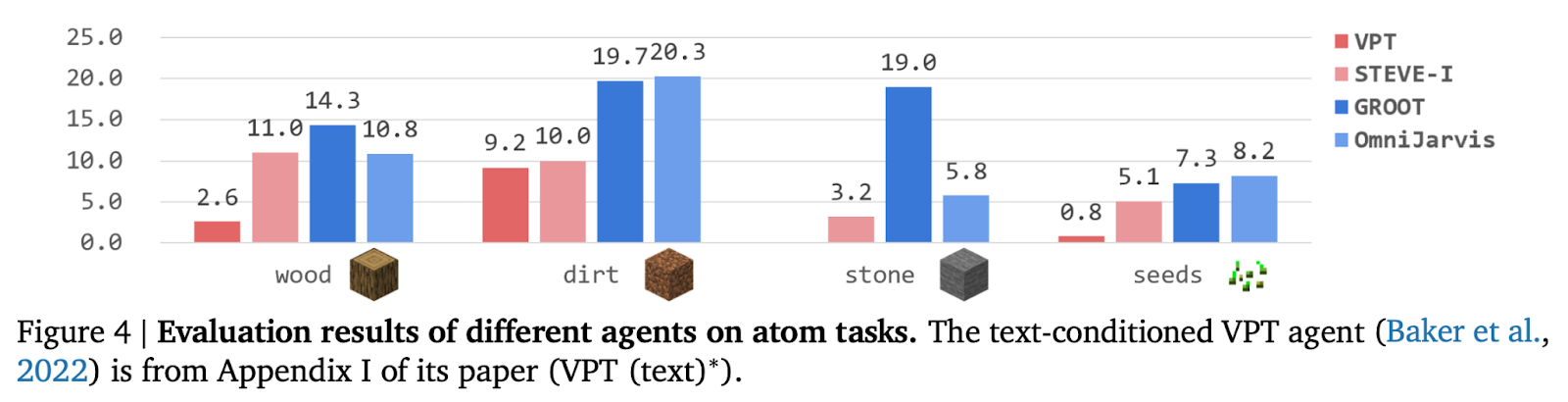
Now, let us examine the performance of OmniJARVIS.
In the Atomic Tasks evaluation, OmniJARVIS demonstrates strong performance by reliably collecting sufficient quantities of required materials. It is important to note that atomic tasks are relatively simple, and therefore the results are reported in terms of the number of items collected, rather than success rate, which would be less meaningful for tasks of this level.
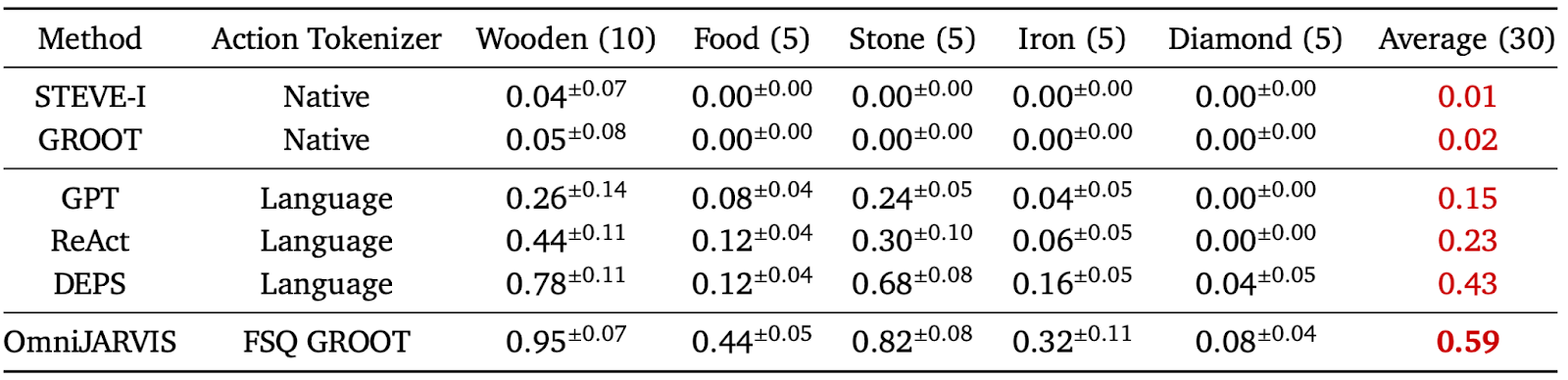
Next, in the Programmatic Task evaluation—which requires longer and more complex execution pipelines—OmniJARVIS again demonstrates significantly higher success rates compared to prior work. These tasks typically require chaining multiple atomic tasks in sequence to acquire the final target item, and the evaluations are grouped into five categories based on difficulty: Wooden, Food, Stone, Iron, and Diamond.
For reference, a task in the Stone category (e.g., crafting a stone pickaxe) involves the following chain:
collect wood → craft wooden pickaxe → mine stone → craft stone pickaxe
—representing a sequence of four atomic tasks.
The relatively lower performance in the Food category may be due to the fact that although the steps required to obtain food are not particularly difficult, food-related tasks are underrepresented in the dataset, resulting in lower success rates.
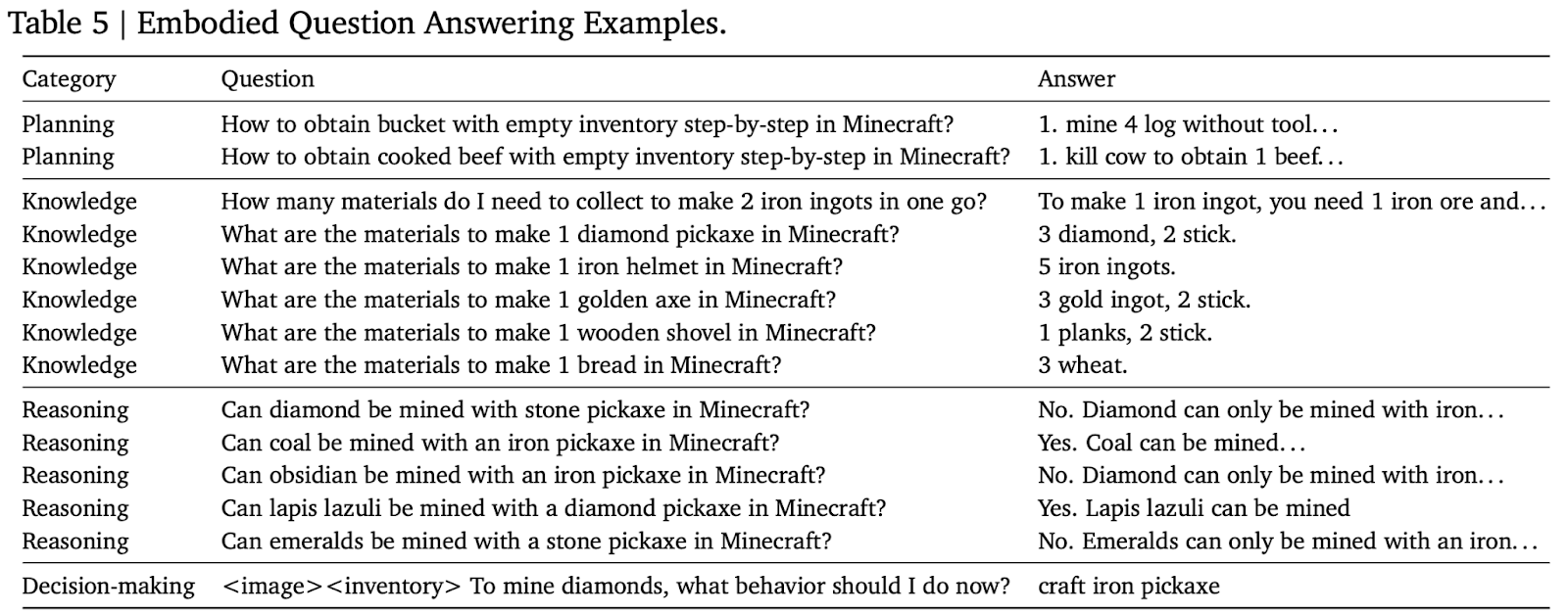

Finally, to evaluate the reasoning capability of OmniJARVIS trained within the Minecraft domain, the authors constructed a Minecraft-specific question–answering (QA) benchmark. As shown in the results, OmniJARVIS achieves superior performance in both instruction following and question answering, outperforming other baseline models.
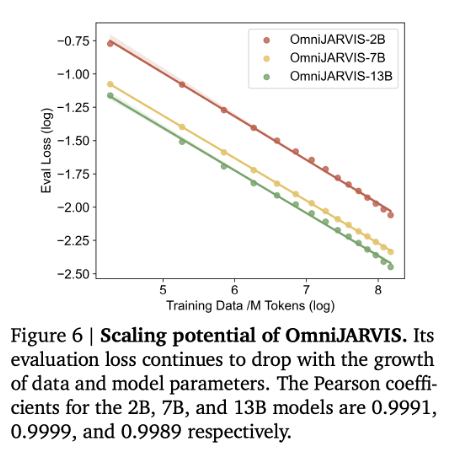
Additionally, OmniJARVIS presents results showing performance improvements as training data scales, experimentally demonstrating that the OmniJARVIS architecture—with its Omni-Tokenizer—follows scaling laws. These findings indicate that OmniJARVIS learns efficiently with increasing data volume and is capable of achieving significantly stronger performance when trained on large-scale datasets.
Team CraftJarvis: ROCKET-1
The final paper from the CraftJarvis team that we will introduce is ROCKET-1, which was orally presented at the NeurIPS 2024 Open World Agent Workshop alongside our CANVAS paper.
In the demo video of ROCKET-1, we can observe that during task execution, the agent periodically asks Molmo to place a point on the screen according to the current plan. Then, SAM (Segment Anything Model) segments the region around the marked point, and based on this segmented region, the ROCKET-1 controller executes the corresponding action.
In the earlier stage of this pipeline, GPT performs reasoning to determine which object to interact with and how to interact with it. In this way, ROCKET-1 integrates GPT for reasoning, Molmo and SAM for visual understanding, and a controller for action execution—enabling the system to perform complex tasks efficiently through this multi-component collaboration.

GPT is responsible not only for generating instructions to be passed to Molmo during planning, but also for specifying the type of interaction to be performed during segmentation. In the figure, the interaction type is visually represented using different segmentation colors for clarity.
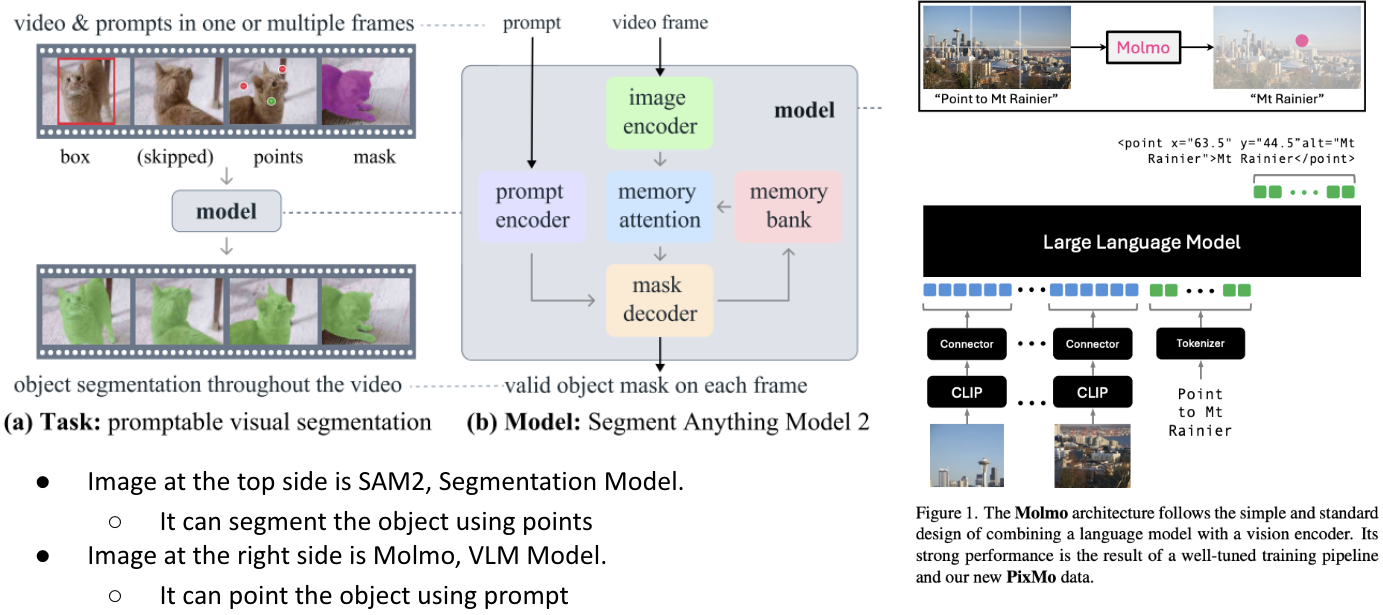
As seen in the example video, the primary modules used in ROCKET-1 are SAM2 and Molmo.
SAM2 is a segmentation model capable of segmenting an object using only a point input, accurately isolating the region associated with the indicated point.
In contrast, Molmo is a vision–language model developed by AI2 and trained on the custom PixMo dataset, and it possesses the ability to point to specific objects based on language instructions.
ROCKET-1 leverages the synergy between these two models: Molmo is used to place a point on the target object, and SAM2 segments the object corresponding to that point. Using this combined capability, ROCKET-1 implements a pipeline where the environment is interacted with in accordance with GPT’s plan.
I suspected that, when Molmo was first released, and the official demo showed SAM2 and Molmo working together, the authors may have taken inspiration directly from that example and started writing the paper. In the Molmo demo video above, we can observe a structure very similar to the key pipeline presented in the paper.
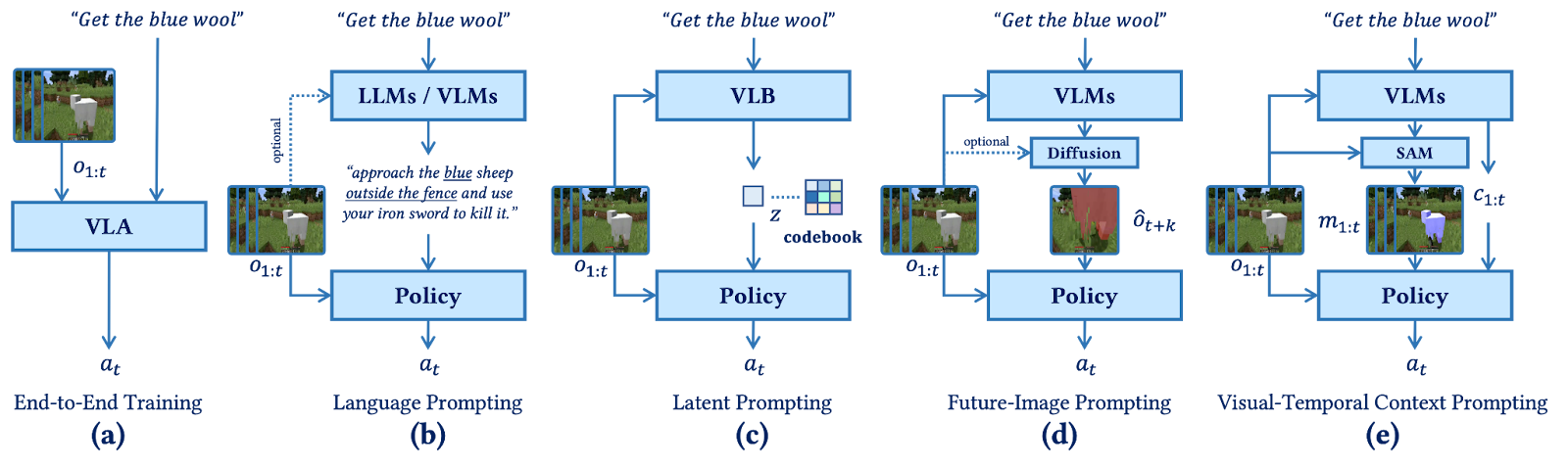
Similar to OmniJARVIS, ROCKET-1 summarizes the pipeline used for embodied decision-making tasks into five categories:
(a) End-to-End pipeline modeling token sequences of language, observations, and actions. (RT-2, OpenVLA)
(b) Language Prompting: VLMs decompose instructions for language-conditioned policy execution. (JARVIS-1)
(c) Latent Prompting: maps discrete behavior tokens to low-level actions. (OmniJARVIS)
(d) Future-Image Prompting: fine-tunes VLMs and diffusion models for image-conditioned control. (MineDreamer)
(e) Visual-Temporal Prompting: VLMs generate segmentations and interaction cues to guide ROCKET-1.
Among these, the pipeline used by ROCKET-1 belongs to category (e) Visual-Temporal Prompting, and performs control using segmentation and interaction cues.
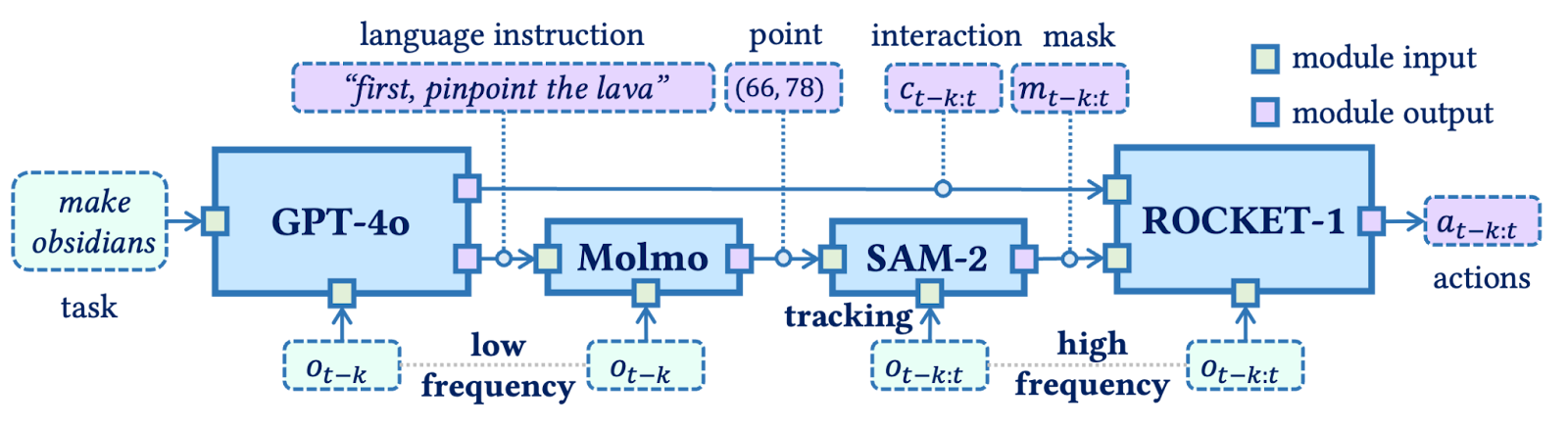
The overall process operates as follows:
Depending on the task, GPT-4o performs planning at a low frequency, generating an interaction type and language instruction and sending a pointing command to Molmo. Afterwards, SAM2 continuously tracks the object that Molmo points to, and passes the resulting object segment information to ROCKET-1.
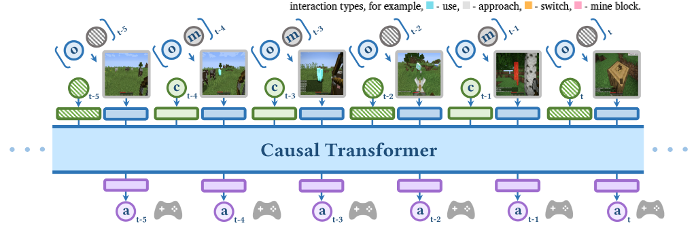
ROCKET-1 then performs low-level actions in the environment based on the provided interaction type, observation, and object segmentation. As such, the structure of ROCKET-1 is a relatively simple pipeline.
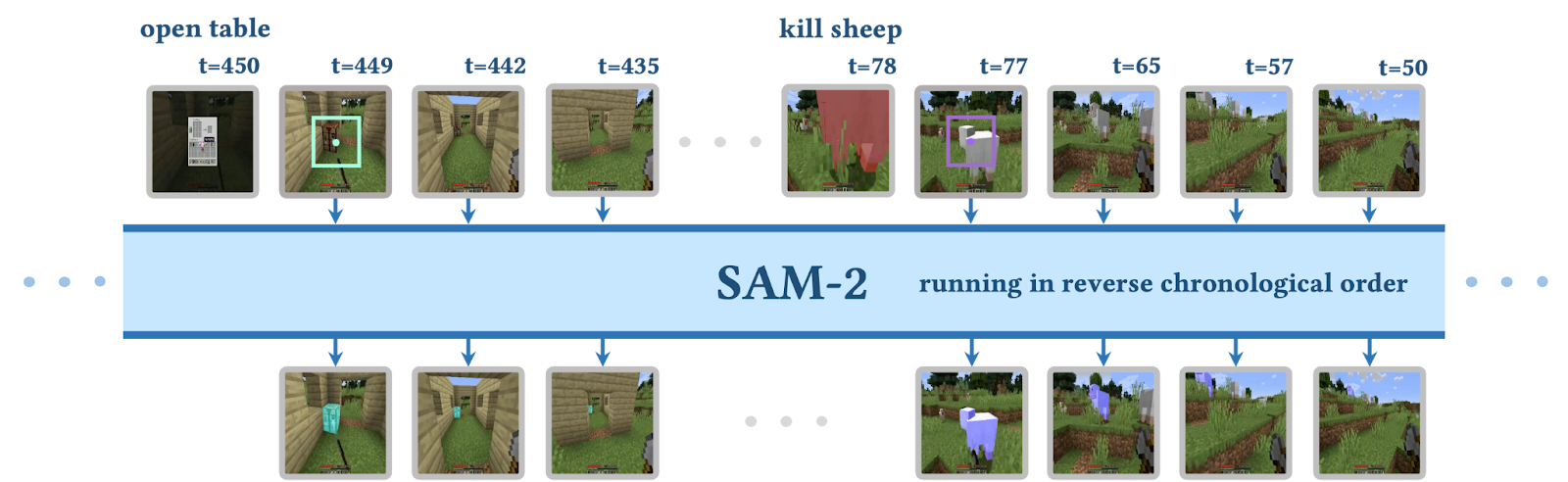
ROCKET-1’s training data is generated using Backward Trajectory Relabeling with SAM2. For example, when given a video of killing a sheep, SAM2 tracks and segments the sheep backward from the moment of death. Using this method, large amounts of training data for the newly defined ROCKET-1 model can be automatically and easily generated.
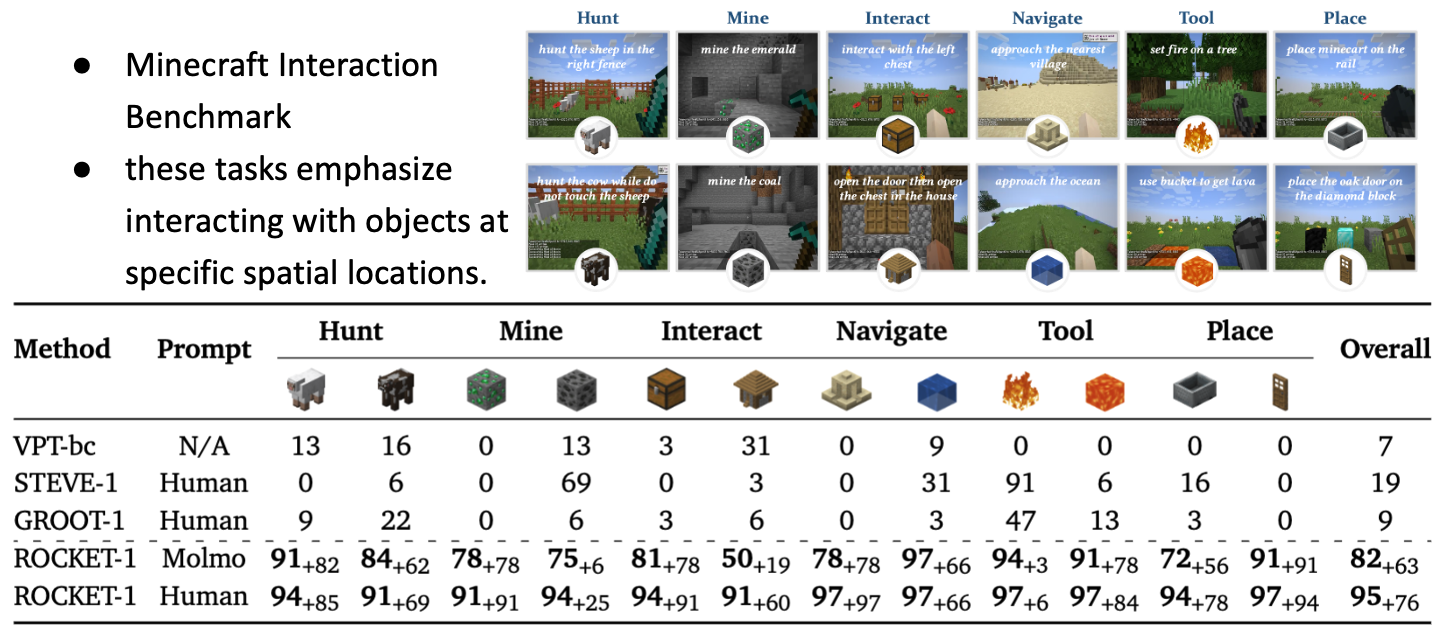
To emphasize the advantages of ROCKET-1, the paper introduces the Minecraft Interaction Benchmark, which evaluates the interaction ability of the model. Through this benchmark, ROCKET-1 is shown to perform complex interactions effectively.

In Long-Horizon Tasks, reasoning performance primarily depends on GPT, so planning is expected to be relatively stable. In fact, because ROCKET-1 excels at complex interaction execution, it demonstrates high success rates when following well-constructed plans.
However, limitations still remain. ROCKET-1 only operates smoothly when the target object is visible or located nearby, and it shows weaknesses in long-context processing. This implies constraints when dealing with long-term planning or distant targets.
Altera
If CraftJarvis is the most well-known group for Minecraft AI research, then Altera is the most well-known company in the same domain.
From Altera’s demonstration videos, the motion appears extremely smooth, suggesting that it is not an end-to-end method. Rather, it appears similar to an LLM agent architecture in which only planning is performed, while low-level control is executed via code—similar to Voyager. This design choice seems likely because Altera’s goal is to build “AI that plays games together with humans”, and therefore low-level control does not need to be solved. In addition, because Altera also executes control through code, if APIs are available, their approach can be easily applied not only to Minecraft but also to other games. From Altera’s perspective, since they are building an agent that will operate only inside a game world, delegating low-level control to an API is reasonable.
(Our company takes the opposite stance: we aim to build agents that operate only in the real physical world, so we must handle low-level control ourselves.)
Altera also recently gained significant attention by conducting a large-scale social experiment in the Minecraft environment called Project Sid, where many agents interacted together. You may have seen this in the news — this project focuses on observing interactions between multiple agents to explore social behavior and collaboration.
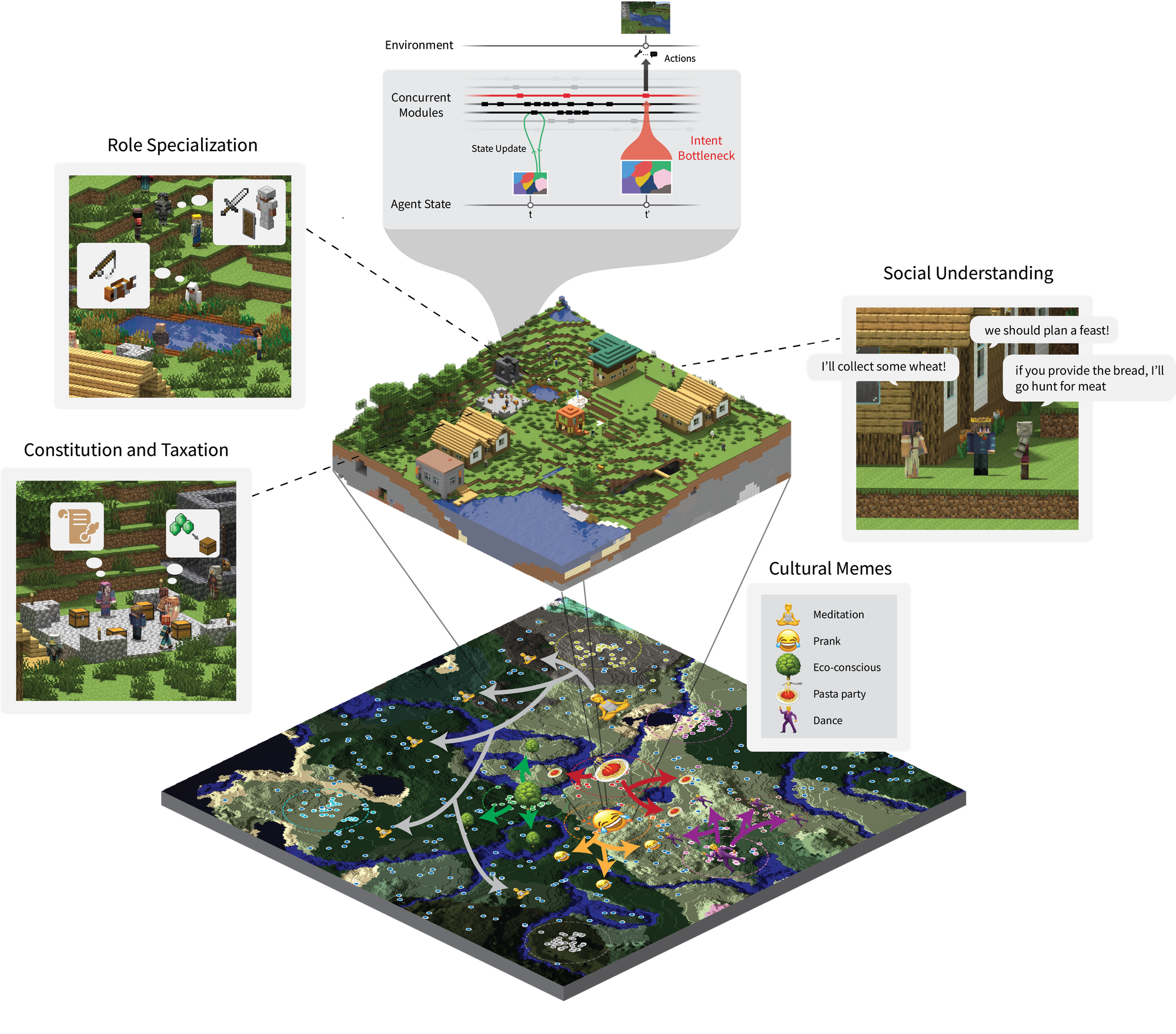

Although I have not read the full paper in detail, it is mentioned that memes spread well within the world (e.g., Church of the Flying Spaghetti Monster).
Conclusion
In this article, we explored Embodied AI research in Minecraft. While reading, some may ask,
“What is the benefit of building an Embodied AI that is good at Minecraft?”
However, the problems and environments that embodied AI must solve in the real world are not significantly different from those in Minecraft. Real-world embodied AI requires interaction, long-term planning, flexible adaptation, which are the same capabilities needed to play Minecraft well.
Through reviewing these research works, we can see that although architectures continue to improve and benchmark performance keeps advancing, fundamental challenges remain—in-context learning, long-context processing, multimodal pretraining, and more. Because of these fundamental issues, it is still difficult to handle complex long-horizon tasks or ensure stable operation in large-scale environments. Solving these challenges remains a major research objective for future embodied AI.
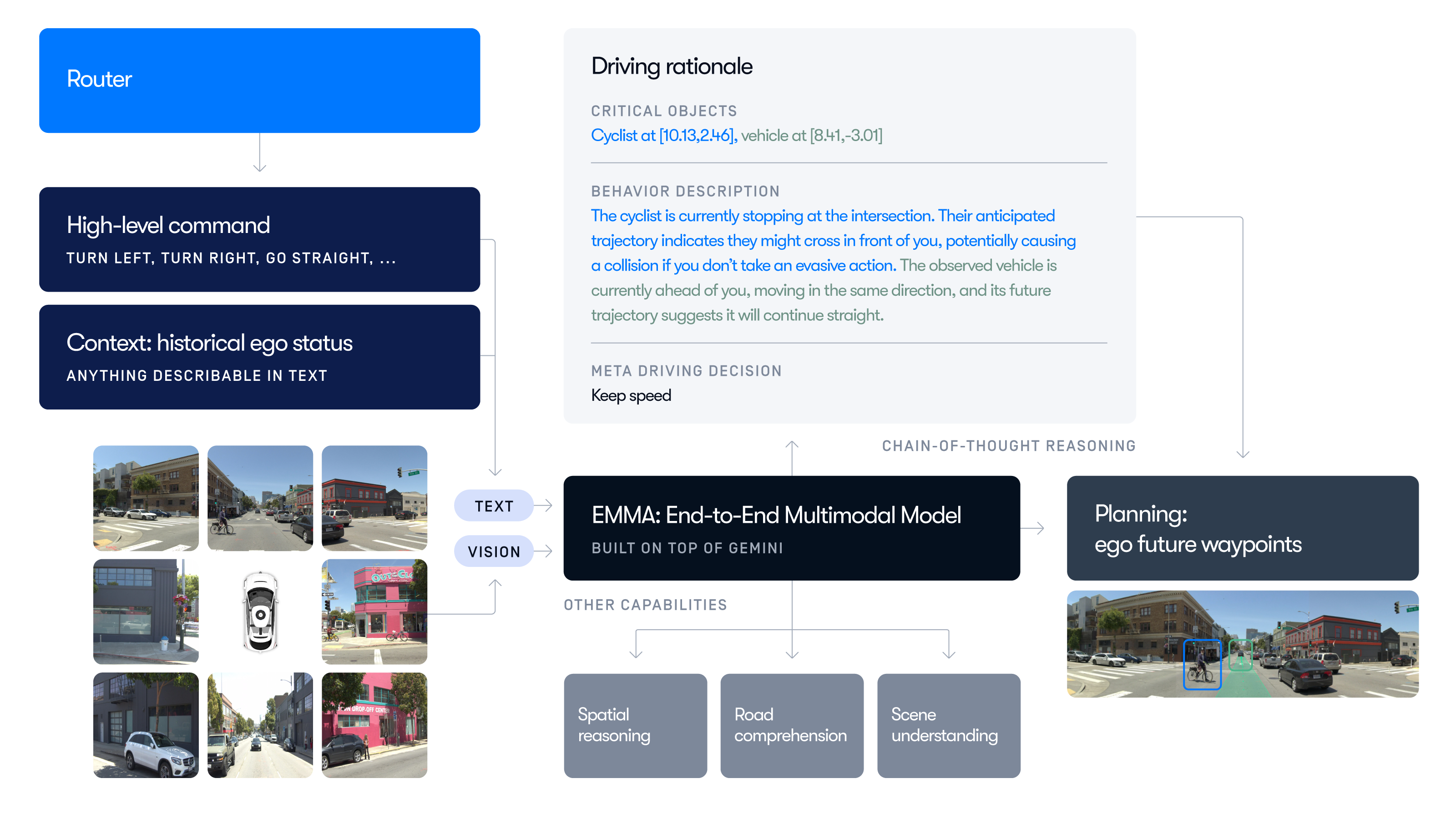
In fact, Waymo is developing EMMA, an LMM that utilizes Gemini’s long-context capability, attempting end-to-end autonomous driving. As noted in the blog post, long-term memory is crucial for solving complex problems:
While EMMA shows great promise, we recognize several of its challenges. EMMA's current limitations in processing long-term video sequences restricts its ability to reason about real-time driving scenarios — long-term memory would be crucial in enabling EMMA to anticipate and respond in complex evolving situations.
Additionally, collecting embodied AI data remains extremely expensive.
Large companies such as NAVER Labs may be able to collect large-scale real-world robot data, but for small companies, simulators like Minecraft are the only realistic way.
For example, our company successfully built realistic sim-to-real data by constructing a real-world-like environment in Unreal Engine and Isaac Sim, then training and deploying the model in an actual environment.
Recently, the Genesis simulator following physical laws has attracted strong interest, as it allows easier experimental data collection.
Our teammate Suhwan Choi leads the open-source project desktop-env, which enables recording screen video and keyboard/mouse inputs simultaneously—similar to VPT dataset creation—making it easy to build training data. It is optimized to store high-frequency data even on low-spec machines.
Contributions are always welcome.
Although the Embodied AI research market has been growing for a long time, it feels like the demand has been increasing even more rapidly recently. For example, rumors suggest that GPT-5 used an enormous amount of resources and data but reportedly failed twice internally, raising questions such as whether we are reaching the limits of scaling due to data constraints.

One of the companies in Korea that I believe is developing foundation models properly is the LG AI Research team, led by Director Kyung-Hoon Bae. Director Bae has stated that they are now working on Large Action Models (although in this context, “action” is not specifically referring to embodied actions). It makes me wonder—will this eventually lead to robotics as well?

Meanwhile, new models such as o1, o3, and qwq are emerging, and people say we are entering an era where performance is improved through Test-Time Compute, increasing inference time rather than model size. At NeurIPS 2024, Sutskever announced that the era of scaling LLMs is over, and Fei-Fei Li emphasized that we now need data that interacts with the environment, aligning with the current trend of building World Models. Because of this, I strongly feel that a major Embodied AI boom is coming.
Even unusual world models are becoming mainstream—much like diffusion models once did—so everyone seems to be building them rapidly.
As I am writing this, NVIDIA has unveiled AI robots at CES, Jensen Huang is actively promoting them on stage, and they have released world-model systems such as NVIDIA Cosmos. Meanwhile, OpenAI has officially revived its robotics division, which was previously shut down in 2020. (This clearly shows that the field is gaining tremendous attention while also becoming increasingly competitive.)
Going forward, the WoRV Team will continue conducting research on Embodied AI. Even if you do not directly participate in the currently trending research fields of Embodied AI or Embodied Agents, I hope this encourages you to at least follow and stay interested in these developments.
If you would like to discuss related research or potential collaboration, coffee chats are always welcome. Also, I would greatly appreciate it if you could press the Subscribe button in the lower right corner.
Thank you for reading this long article.