[EN] Monorepo Architecture for Agent Research
Hello, my name is Suhwan Choi, and I am a Machine Learning Engineer at the WoRV team. Currently, our team is building and using a monorepo project called SketchDrive, which contains more than 22,000 lines of Python source code (as of October 2024) for vision-based embodied agent research and development. In this article, I would like to introduce it. If you would like to learn more about SketchDrive, please refer to this link! I believe it serves as a great example for embodied agent research and development, and I highly recommend it to those who are starting agent research.
What's monorepo?
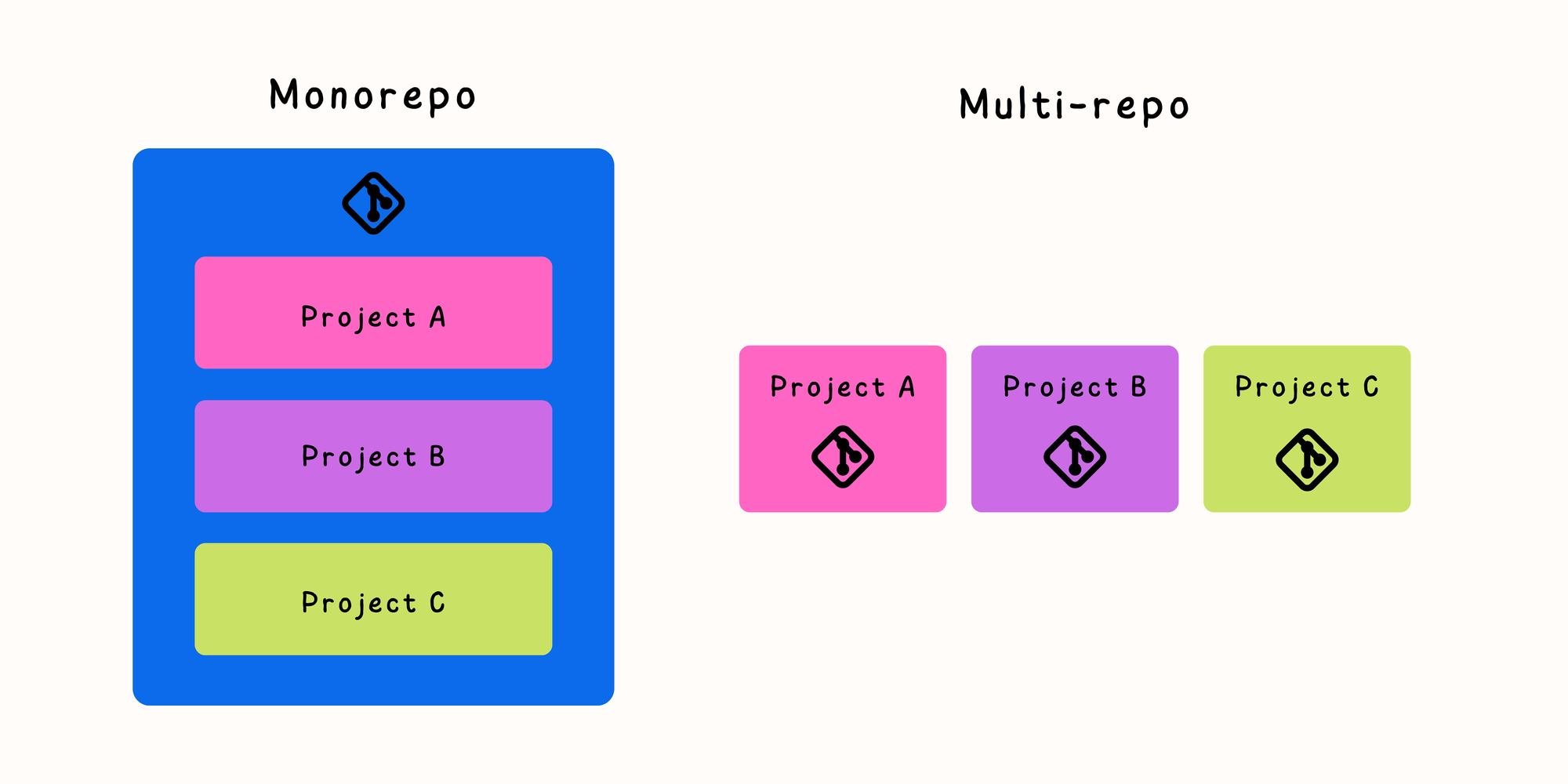
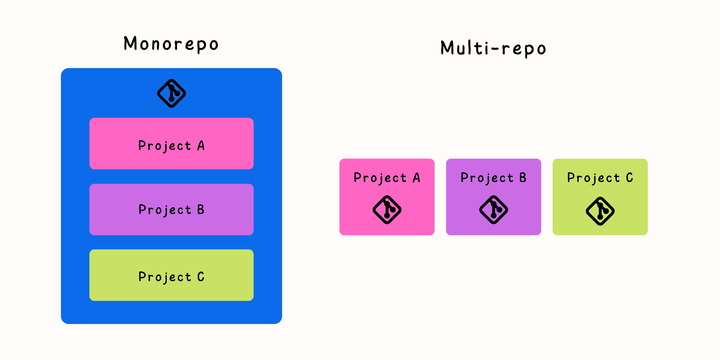
A monorepo is short for Monolithic Repositories, referring to a repository that contains multiple projects in a single repo.
This contrasts with conventional repositories that contain a single project per repository.
As an example, ML researchers may have seen https://github.com/google-research/google-research.
(Although personally, I don’t think it’s a great example ^^;)
In the article Pipeline optimization for 200+ services in a monorepo, building a monorepo system to improve teamwork, we can see that Toss and Mathpresso (QANDA) also use monorepo structures.
Why Does Google Use Monorepo? also states that many Big Tech companies such as Google, Meta, and Uber adopt monorepo structures.
(Technically speaking, according to the definition used in that article, the structure we use is a hybrid of monorepo and microrepo.)
Why monorepo for agent?
Monorepo structures are particularly beneficial in the following cases — and agent research/development falls into all of them.
This is why I recommend adopting a monorepo when beginning agent research.
- When the functionality to develop is divided into multiple components in the pipeline
In agent research, we must build data collection, preprocessing, training, and evaluation, each of which is non-trivial in size. If each were a separate repository, it would require multiple independent repos. - When fast and flexible configuration is required
Agent research has no fixed or established approach yet.
Monorepo development using trunk-based development is very suitable.
All branches merge within two weeks at the latest, and we can flexibly handle modifications that span multiple projects.
Early structure of SketchDrive
Before explaining the reason we decided to adopt a monorepo structure, I will first list the structure of our repository (sketchdrive) and the functionalities we needed.
First, our repository is composed as follows:
- A repository for data collection and preprocessing
- A repository for model training
- A repository containing simulator-related source code
- A repository for evaluating model performance in both simulator and real-world environments through closed-loop evaluation
.
├── agent
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
├── data_processing
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
├── data_collection
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
├── drive_evaluation
│ ├── agent
│ ├── auto_eval
│ └── model_worker
└── isaac_simIn the earliest stages of development, we maintained all of these components as separate repositories, but this led to several issues.
Dependency issues between packages:
As mentioned above, the repositories used for embodied agent training must be executed sequentially in a pipeline. In this structure, developing each repository independently often resulted in interface or functionality conflicts, making full integration of the pipeline difficult.
Development challenges:
For similar reasons, developing multiple repositories that must organically connect to each other required running multiple IDE windows simultaneously, which significantly increased development complexity. Features that spanned multiple repositories were particularly difficult to implement.
Duplicated code:
Because the repositories were strongly separated, we frequently ended up rewriting the same functionality in multiple repositories, leading to unnecessary duplication.
Additionally, several considerations were specific to our use case:
Multiple dependencies:
Different repositories relied on different Python package dependencies.
Multiple environments:
Beyond Python package dependencies, some repositories relied on different system-level dependencies. For example, some components required ROS (Robot Operating System), while others—such as the model training repository—did not. ROS is a collection of software libraries and tools used for robotics research and development. Unlike a traditional OS, it can be installed and run as a system package on top of Ubuntu as a kind of meta-OS. (Further details can be found through additional resources.)
Some repositories were Python packages themselves, while others were not. For example, drive_evaluation is a representative non-package repository.
Monorepo structured SketchDrive
To address the issues mentioned above and to reflect our use case, we began designing and adopting a monorepo structure in July 2024. As of October 2024, the SketchDrive monorepo is organized as follows.
.
├── README.md
├── projects
│ └── agent
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
│ └── common
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
│ └── data_collection
│ └── ...
│ ├── data_processing
│ ├── drive_evaluation
│ ├── isaac_sim
│ └── ros_common
├── ruff.toml
├── third-party
│ └── ...
└── workspace
├── ros_workspace
└── workspace- Under the projects folder, there are first-party projects required for data collection, preprocessing, training, and model evaluation.
- Under the third-party folder, there are third-party projects installed in the form of Git submodules.
- Format/lint is fully managed with ruff, and all Python packages are managed with poetry.
- Content shared across packages is managed in the common package (package name:
sketchdrive_common). - Packages can depend on one another using paths like
../project-name(supported by poetry). - Docker images are managed in the workspace folder, and Docker images related to ROS are managed separately.
By structuring the repository in this way, we were able to resolve all of the issues mentioned above while also reflecting our use case. We resolved the duplicated-code problem through the common package, and thanks to adopting a monorepo structure, dependency management and development (especially for features that require integrated modifications across multiple sub-repositories) became much more convenient. Regarding ROS-related dependencies, we left only the parts that must actually run ROS inside Docker, and handled the remainder using rosbags, a ROS-free, Python-only library.
Additionally, this structure can be extended in various ways.
- Although the project root is not installable by default, required packages can be installed by running a command such as:
poetry install --no-root --withtrain
in the project root using an appropriate poetry configuration. - The project root
pyproject.tomlcan be configured as follows:
[tool.poetry.group.train]
optional = true
[tool.poetry.group.train.dependencies]
agent = {path = "projects/agent", develop = true}
data_processing = {path = "projects/data_processing", develop = true}Convention for monorepo
The structure itself is sufficient at this point. However, what is even more important—actually, far more important—than the structure when building a monorepo is the collaboration conventions and deployment strategy.
For deployment, the article “Optimizing CI/CD Pipelines for 200+ Services in a Monorepo” from Toss may be helpful. In our case, deployment has not been a major concern because our project is still at a stage where extensive deployment is not required.
- Trunk-based development:
All branches must be merged within two weeks at the latest. Features should be developed in small units, and maintaining the integrity of the main branch through periodic CI/CD is ideally also required. However, because research and early-stage PoC have higher priority than development, we have not heavily considered CI/CD yet.
Based on our experience, PRs that remain unmerged for too long incur significant resolution cost due to merge conflicts. - Branching and commit naming conventions:
Branch and commit names must include the name of the primary project affected.
Examples:- Branch name:
feat/drive_evaluation/reset-latency - Commit name:
docs(drive_evaluation): add documentation for real inference
When modifications span multiple projects, we flexibly use the name of the project that represents the primary functionality being implemented. Since rapid development and productivity are our priorities, we intentionally avoid overly strict control.
- Branch name:
auto-eval
As briefly mentioned earlier, the drive_evaluation project within our monorepo includes a folder named auto_eval. It contains source code for automatically evaluating model driving performance over multiple simulation environments.
This is necessary because closed-loop evaluation is essential in agent research.
To explain closed-loop evaluation, it must be contrasted with open-loop evaluation. For more detailed reference, please see refrefref.
- open-loop evaluation: Evaluation conducted in a setup where the model’s output or agent’s action does not alter the state of the world.
Although it has the critical limitation of deviating from actual real-world performance, it has the advantage of requiring no costly execution environment (simulation or real-world robotics).- In autonomous driving research, a common example is feeding sensory input into a model and measuring how different the predicted action is from the actual action.
A representative open-loop evaluation metric is ADE (Average Displacement Error), defined as the average L2 distance between the actual and predicted trajectory.
- In autonomous driving research, a common example is feeding sensory input into a model and measuring how different the predicted action is from the actual action.
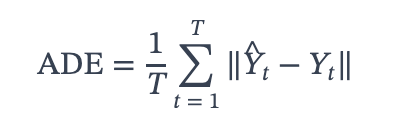
- closed-loop evaluation: Unlike above, this evaluation is performed in a setup where the model’s output changes the world state.
Its advantage is that it provides metrics identical to those obtained in real-world execution.
We consider closed-loop evaluation essential for trustworthy performance evaluation, and thus built a pipeline capable of automatically collecting driving results across various simulation environments (multiple NVIDIA Isaac Sim scenes) and multiple driving scenarios.
Future of SketchDrive monorepo
The following items represent improvements we plan to add to the SketchDrive monorepo:
- Integrated config and entrypoint management:
Configurations are currently distributed across multiple projects, and finding the entrypoint for each is difficult. For example, project A might be run viapython main.py, while project B may be run viabash scripts/abc.sh. - Unified environment and Docker image management:
Similar to above, environments and Docker images are currently managed separately across projects.
We are also considering adopting uv, developed by Astral (creators of Ruff), instead of Poetry.
Unlike Poetry, uv also manages Python versions and adheres to PEP 621.
Several issues related to monorepo and PyTorch are currently open; we plan to adopt uv once those are resolved. - Automated pipeline execution and CI/CD:
Currently, preprocessing, training, and model evaluation are individually automated.
That is, each is automated, but they are not yet linked as a single workflow.
We are considering introducing a tool such as Apache Airflow to orchestrate end-to-end automation.
We also plan to enhance CI/CD and test coverage using GitHub Actions, which currently exist in an initial form.
Closing remarks
In this article, we introduced a monorepo structure suitable for agent research and development.
WoRV completed the first version of the SketchDrive monorepo in September 2024 and used it to conduct the research project CANVAS. More details can be found in the article introducing SketchDrive.
As of now, the SketchDrive monorepo contains 812 commits and over 22,000 lines of Python code. We are continuously exploring how to maintain it cleanly, well-organized, and functionally robust.
The WoRV team is actively hiring for Machine Learning Engineer and Machine Learning Software Engineer roles to maintain, improve, and expand the SketchDrive monorepo.