[EN] “The End of VGGT? Why MapAnything Wins in the Real World.”
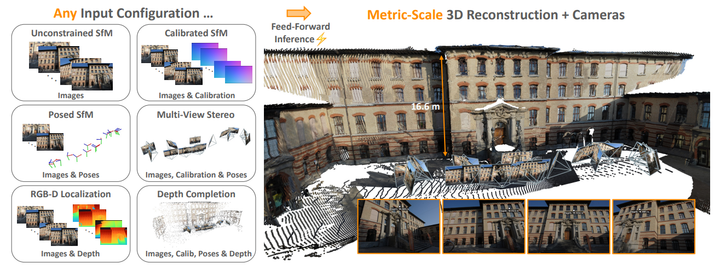
Within Meta, two teams have pursued the same ambition through entirely different philosophies — reconstructing 3D geometry from images.
VGGT, developed by Meta AI, takes a pure transformer-based approach, treating geometry as something that can be learned end-to-end from pixels alone.
MapAnything, from Meta Reality Labs, follows a more structured philosophy: it explicitly models rays, depth, pose, and metric scale to infer the 3D world.
On paper, both aim to “rebuild the world from images.”
But when I tested them in a real orchard — filled with repeating trees, shifting light, and imperfect motion — the difference was impossible to miss.
This wasn’t about benchmarks or leaderboards.
It was a simple, practical question every roboticist eventually faces:
“How well do these vision-based models hold up in the real world?”
1. The Setup — Taking Transformers to the Orchard
The test environment wasn’t some tidy dataset — it was a real orchard in Yeongwol, South Korea, where tree trunks repeat endlessly and sunlight flickers through the leaves.
It’s a nightmare for feature-based methods and a perfect test for models that claim to “understand” geometry.
I equipped the robot with GPS, wheel odometry, and an RGB camera (10 Hz) and asked each model to reproduce the ground-truth trajectory.
No hand-tuning. No filtering. Just raw inference.
2. Two Models, Two Philosophies
| Feature | VGGT | MapAnything |
|---|---|---|
| Inputs | RGB only | RGB + optional intrinsics, wheel odometry, or depth |
| Architecture | Vision-only Transformer | Factored representation: ray + depth + pose + metric scale |
| Scale estimation | Implicit, learned during training | Explicit learnable scale token |
| Strength | Fast, end-to-end inference | Geometrically grounded and sensor-aware |
VGGT tries to do everything at once — estimate camera pose, depth, and even scene scale directly from raw pixels.
It’s elegant and fully self-contained, but also fragile when the visual world becomes repetitive.
MapAnything, on the other hand, takes a more structured path.
It splits the world into four components — rays, depth, pose, and a learnable scale factor — and then rebuilds 3D geometry by combining them.
That separation makes it much easier for the model to stay consistent, even when the scenery gets messy.
In short: VGGT aims for end-to-end magic, while MapAnything builds in physical logic.
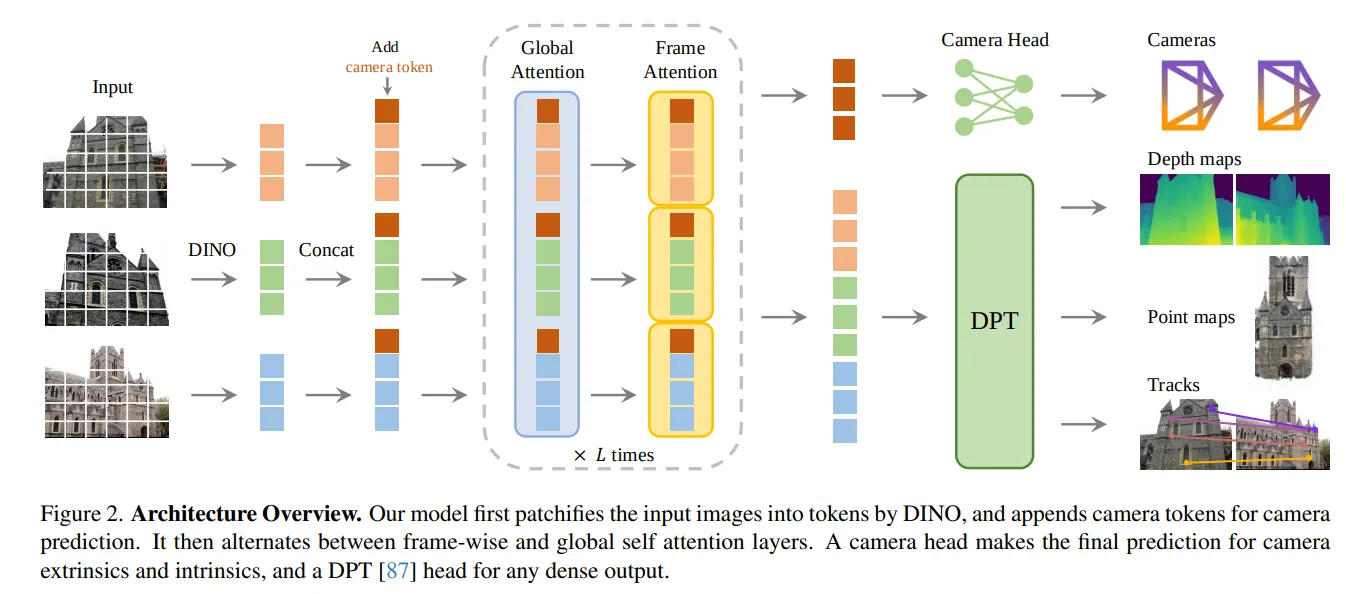
Fig. VGGT Architecture Overview
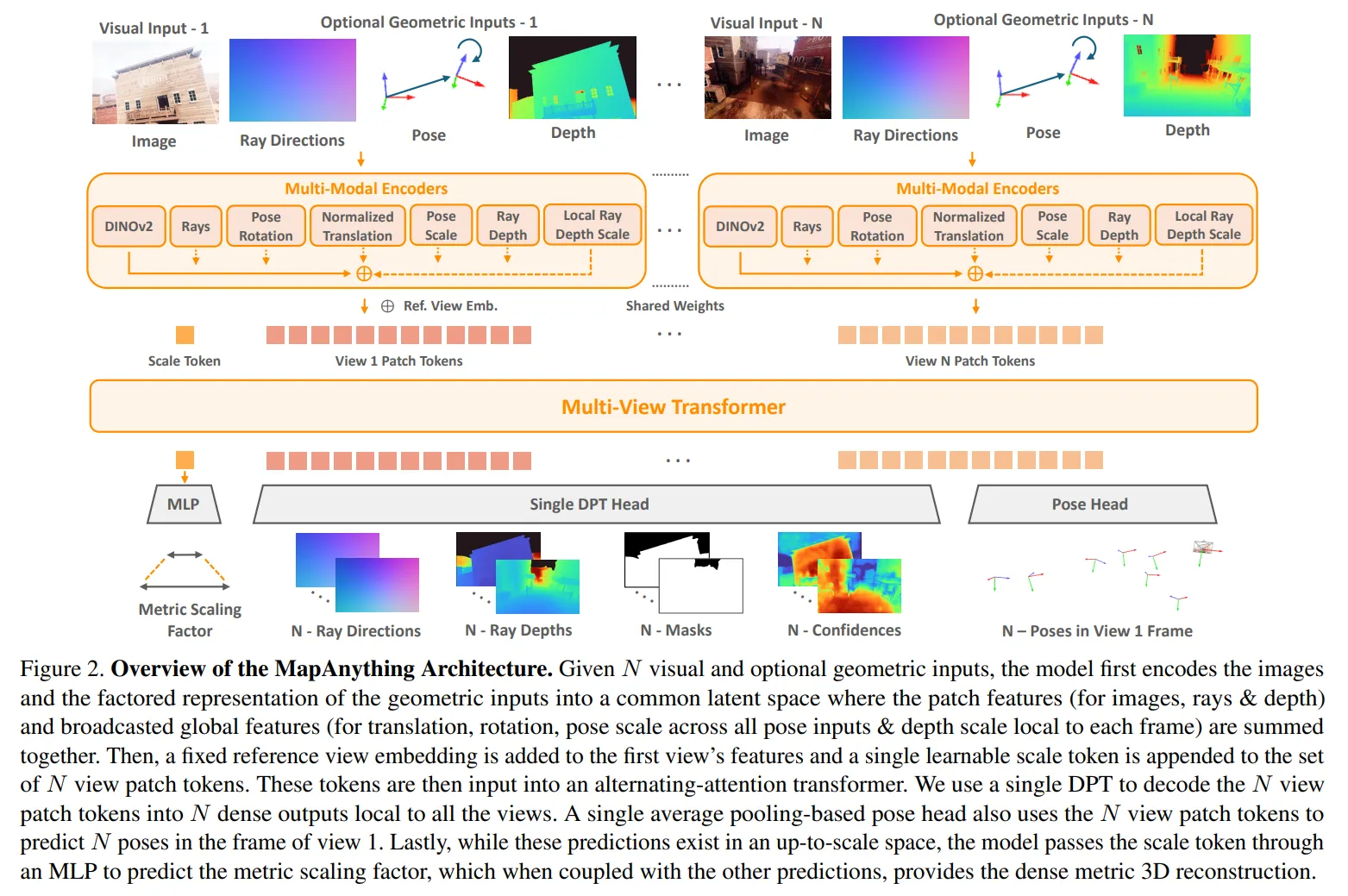
Fig. MapAnything Architecture Overview
3. What Happened in the Field
Each trajectory plot below compares:
- Red → GPS ground truth
- Sky blue → MapAnything + wheel odometry
- Green → Wheel odometry only
- Axes → VGGT
MapAnything: Vision That Grounds the Wheels
The first thing I noticed was how calm MapAnything’s trajectory looked.
The sky-blue curve practically hugged the GPS path. Even when the wheel odometry drifted,[Fig 4] MapAnything gently corrected the heading back on track.[Fig 2]
In sections where odometry alone over-rotated or slipped (green),[Fig 4] the model leaned on its visual cues to restore alignment[Fig 2] — almost like it “saw” that the world wasn’t spinning as much as the wheels thought.
It didn’t just assist odometry — it actively suppressed drift using visual feedback.

VGGT: Struggling Among the Trees
VGGT started strong on straight paths but stumbled the moment rotations came in. [Fig 3]
Turns were under-estimated, and its predicted trajectory gradually peeled away from GPS.
The culprit was clear: the orchard’s repeating tree trunks and shadows tricked VGGT’s feature matcher.
Without odometry or intrinsics to anchor it, tiny misalignments accumulated until the pose simply drifted away.
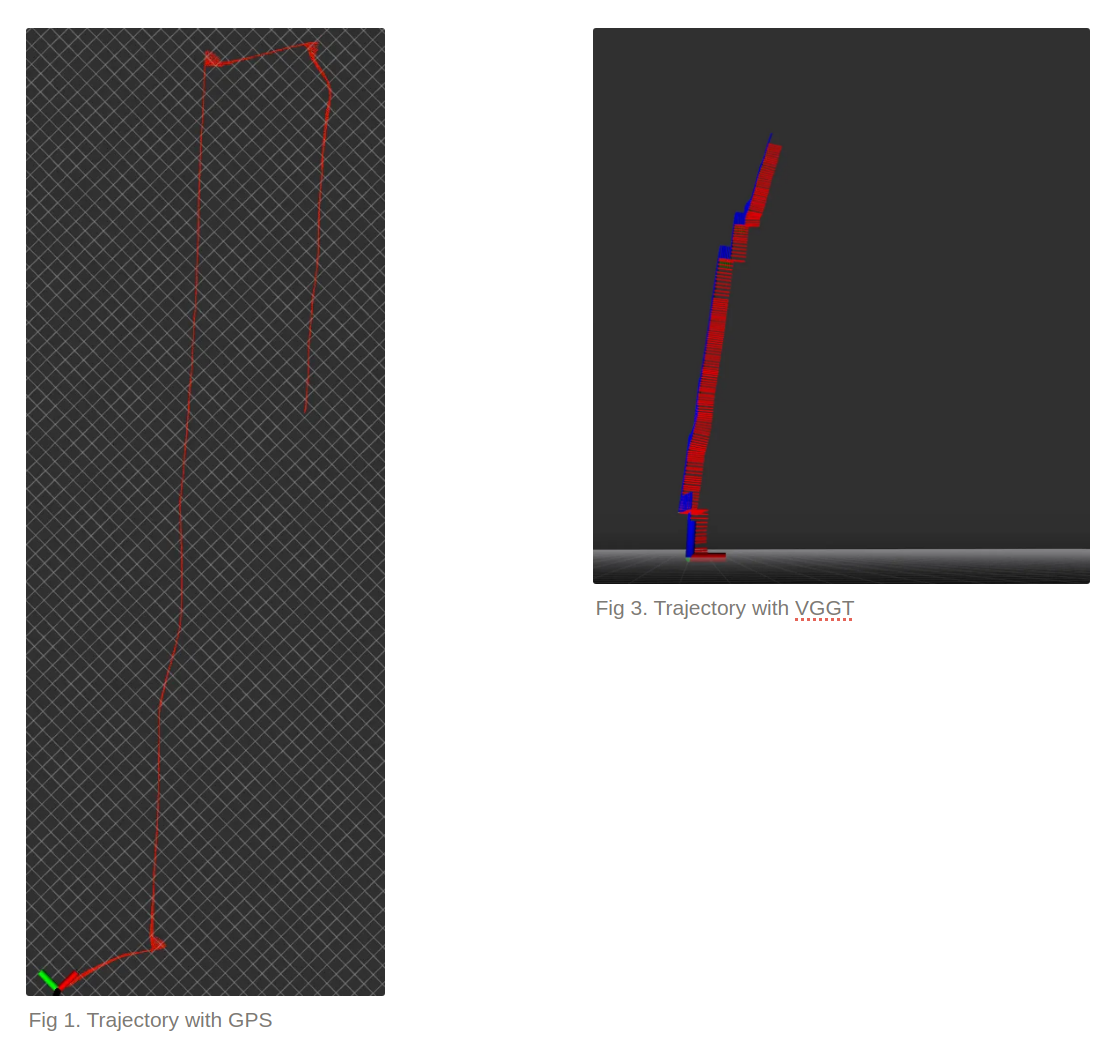
Wheel Odometry Alone
Wheel odometry did what you’d expect — mostly consistent direction, but with slowly growing error. [Fig 4]
Every slip, bump, and uneven patch of ground compounded over time.
Without visual correction, the drift never came back.

Video. Trajectory with MapAnything(left) and VGGT(Right)
4. Why Such a Big Gap?
VGGT: The Fragility of Pure Vision
When the world looks repetitive, a vision-only model can’t tell if it’s moving forward or sideways.
VGGT lacks odometry or intrinsics, so small visual errors snowball quickly.
MapAnything: Geometry with a Sense of Reality
MapAnything embraces other sensors.
It uses wheel odometry as an initial guess and camera intrinsics as geometric anchors.
The result is a trajectory that stays stable in both heading and scale — even over long runs.
The Secret Ingredient — The Learnable Scale Token
This small component gives MapAnything a sense of “how big the world should be.”
By training on thousands of metric-labeled scenes, the model internalizes simple priors like:
a tree is usually 5–10 m tall, or a doorway is about 2 m high.
That built-in intuition lets it estimate real-world scale, even from uncalibrated, wild imagery.
In simpler terms:
- VGGT: tries to guess shape and size at once → unstable.
- MapAnything: gets shape first, then stabilizes scale through learned priors → robust.
4.1. Is VGGT Done? The Hidden Strength of VGGT — Speed and Prototyping
Despite its fragility in repetitive outdoor scenes, VGGT still shines where speed and flexibility matter.
In my tests, the feed-forward inference on an RTX 4090 took only ~0.25 seconds per scene, compared to ~0.3 seconds for MapAnything.
That small gap might sound trivial on paper, but in practice it means a real-time loop running at 4 Hz, fast enough to stream depth and pose updates into a robot’s navigation stack without any optimization overhead.
For researchers and developers, this difference can be decisive.
VGGT’s open-source implementation already includes a working SLAM system (link to be inserted), making it remarkably easy to prototype new ideas or use it as a baseline for geometry-aware transformer studies.
In other words, VGGT trades a bit of stability for speed and simplicity — a trade-off that’s often worth it in research iterations, simulations, and early robot prototyping where time-to-test matters more than per-frame precision.
5. What This Means — and Where to Go Next
Key Takeaways
- MapAnything was noticeably more robust in the wild and integrates smoothly into standard robotics stacks.
- VGGT, though sleek and fast, struggles when textures repeat or lighting changes — both common in real-world navigation.
Future Directions
1. Toward a SLAM-Ready System
MapAnything’s metric-scale estimation could be combined with wheel odometry to build a semi-metric visual-odometry-based SLAM pipeline —
anchored by geometry but guided by learned priors.
2. Loss-Guided Sensor Fusion
MapAnything’s reconstruction loss isn’t just a training signal — it can also act as a live feedback cue.
When the loss rises (meaning the model’s visual consistency drops), the system can lean more on wheel odometry.
When the loss is low, vision takes the lead.
In other words, the robot can continuously rebalance trust between sensors to keep its trajectory both visually consistent and robust to noise.

