[EN] Introduction to SketchDrive Project
Who might benefit from reading this article
- Those who feel skeptical about developing navigation robots or autonomous vehicles using rule-based, modular approaches
- Those who want to build human-like agents (robotics, gaming, desktop control, etc.)
- ML researchers/engineers interested in exploring emerging fields beyond traditional major ML domains such as CV and NLP (multimodal embodied agents), and who believe that Internet-sourced data is reaching its limits and that it is time to use real-world data
- Those who want technology that does not stop at the research stage, but can be commercialized and create real practical value
- Those who wish to work with us on these efforts!
Hello, my name is Suhwan Choi, and I am a Machine Learning Engineer on the WoRV Team.
Today, I would like to introduce the SketchDrive project, which our team has been researching since mid-this year.
Intro to SketchDrive
SketchDrive is…
- Like a human, a single model drives across multiple environments using maps, natural-language instructions, and visual perception.
- Like a human, it interprets user intent through contextual understanding when instructions are given.
- It solves two fundamental problems that existing robotics navigation methods have failed to address: instructable and generalizable.
- First, let me show a short demo video.
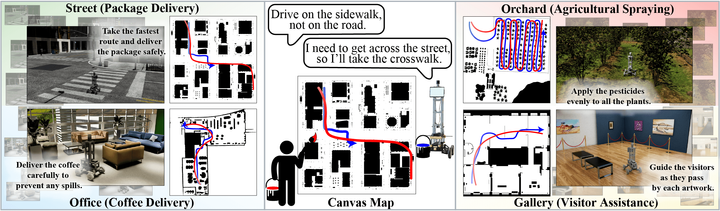
On the map, the blue line is the user’s instruction, and the red line is the robot’s actual trajectory.
Our model receives natural language, visual input, and the route-sketch map together, interprets the intention of the instructing person, and drives accordingly.
Fundamentally, if you draw on the map, the robot goes.
Of course, beyond this simplicity, we considered and experimentally demonstrated many cases where human intent is interpreted, which I will introduce soon.
After having built the full pipeline, collecting data to teach about boxes, humans, stop signs, and bushes (passable), and recording the above video took only 15 days.
This is completely different from traditional approaches requiring an expert engineer to spend several months designing a separate module for each component.
The SketchDrive project started in June 2024, and only four months have passed. The video above is only the second demo following CANVAS (explained later).
We believe that our approach will enable us to build robots that behave nearly like humans, achieve fully autonomous driving, and eventually achieve commercialization.
Our team is actively hiring.
We are recruiting for many roles including Machine Learning Engineer, and we welcome coffee chats at any time.
Why SketchDrive?
Our research team’s vision is to build agents that behave like humans.
SketchDrive is a project that originated from this vision—learning to drive from humans and driving like humans.
Here, the phrase “driving like a human” can sound vague.
So let me concretely explain what it means.
- Human-level generalization performance (generalizable)
- Humans can find their way even in completely unfamiliar places using only abstract diagrams such as fire-evacuation maps.
Although generalization has long been an important topic in robotics research, it is far from solved. - Humans can also operate a variety of robots after just a few trials.
- Humans can find their way even in completely unfamiliar places using only abstract diagrams such as fire-evacuation maps.
- Ability to receive various types of instructions (instructable)
- Continuing the previous example, humans can navigate using abstract maps that do not perfectly match real-world structure.
- Moreover, regardless of how the instruction is drawn on the map—line, dot, roughly sketched—humans can interpret intent from context and act accordingly
Our research team views these two properties—generalizable and instructable—as the most important research topics.
Although we are currently solving the navigation problem, the philosophical foundation actually comes from the game agent SIMA.
Personally, I assume that the SIMA researchers intentionally placed a comma after Scalable and Instructable because these two are so important.
What about existing approaches?
- Generalization issues (generalizable)
Without solving this problem, commercialization beyond the research stage is impossible.
Operating robots in uncontrolled environments (such as city sidewalks) is difficult because of countless unpredictable elements: trash, objects on the road, puddles, sidewalk curbs, etc.
Encountering something not accounted for during design leads to task failure, and if damage occurs, the robot may not be able to safely recover.
This issue becomes even more pronounced when using RL (Reinforcement Learning).
If you are interested, please read the following explanation.
Additional notes on RL
RL provides an effective method for maximizing rewards (reward) when rewards are well-defined.
This approach is extremely powerful—powerful enough to defeat the best human Go players. (AlphaGo)
However, for the task of generalization, rewards cannot be well-defined.
Is there truly such a scalar as “a number that monotonically increases the more an agent generalizes well across diverse environments”?
To solve the generalization problem using RL, such a scalar must exist and must be implementable.
But if an agent learns an implicit reward from human demonstrations and becomes “human-like”, then this entire problem disappears.
In fact, although I mentioned that RL works well when rewards are well-defined, in practice truly well-defined reward settings are extremely rare. Reward definition is difficult even for a single task, without talking about generalization. (difficulty of reward shaping)
For example, imagine giving −10 reward for collision during autonomous driving, and +0.1 for every time step elapsed without collision.
This may seem reasonable, but can you confidently claim that the result A (produced by a model that maximizes this reward) equals the driving behavior B you actually want? When A ≠ B, it is known as reward hacking.
If that’s unclear, let’s proceed with the assumption that A = B.
Now imagine building a robot that must clean tightly along walls. Should it still use the same reward? Clearly not.
Would we design a new reward for each robot use case—100 different ones—and redesign/train every time a new requirement appears?
Even when user needs change slightly (e.g., “please avoid puddles”) this approach falls apart.
For those interested, refer to:
- Sergey Levine — Should I Imitate or Reinforce?
- Reinforcement Learning with Large Datasets: Robotics, Image Generation, and LLMs
Generalization is directly tied to scalability.
generalizable <-> scalable
Generalization is directly tied to scalability.
Rule-based methods rely heavily on expert engineers spending months creating new modules in a divide-and-conquer fashion.
In contrast, a data-centric approach like ours allows scalable improvement simply by adding more data representing what any human can do.
Let me illustrate with a simple example:
Traditional robotics assumes that obstacles must always be avoided.
But is that always true?
Driving through tall bushes is difficult for existing approaches because they cannot determine whether bushes are traversable. There is even research specifically on removing vegetation from point clouds [ref].
If bushes are removed, what about puddles? Plastic bags? Debris? Arbitrary objects that might or might not be passable?
How long must we continue adding individual modules to achieve commercialization?
Instruction convenience problem (instructable)
Without solving this problem, robots cannot be used by everyday users.
In traditional approaches using precise coordinate-based instructions and manually designed algorithms (conventional rule-based algorithm, ref), robots cannot interpret human intent or adapt their behavior contextually.
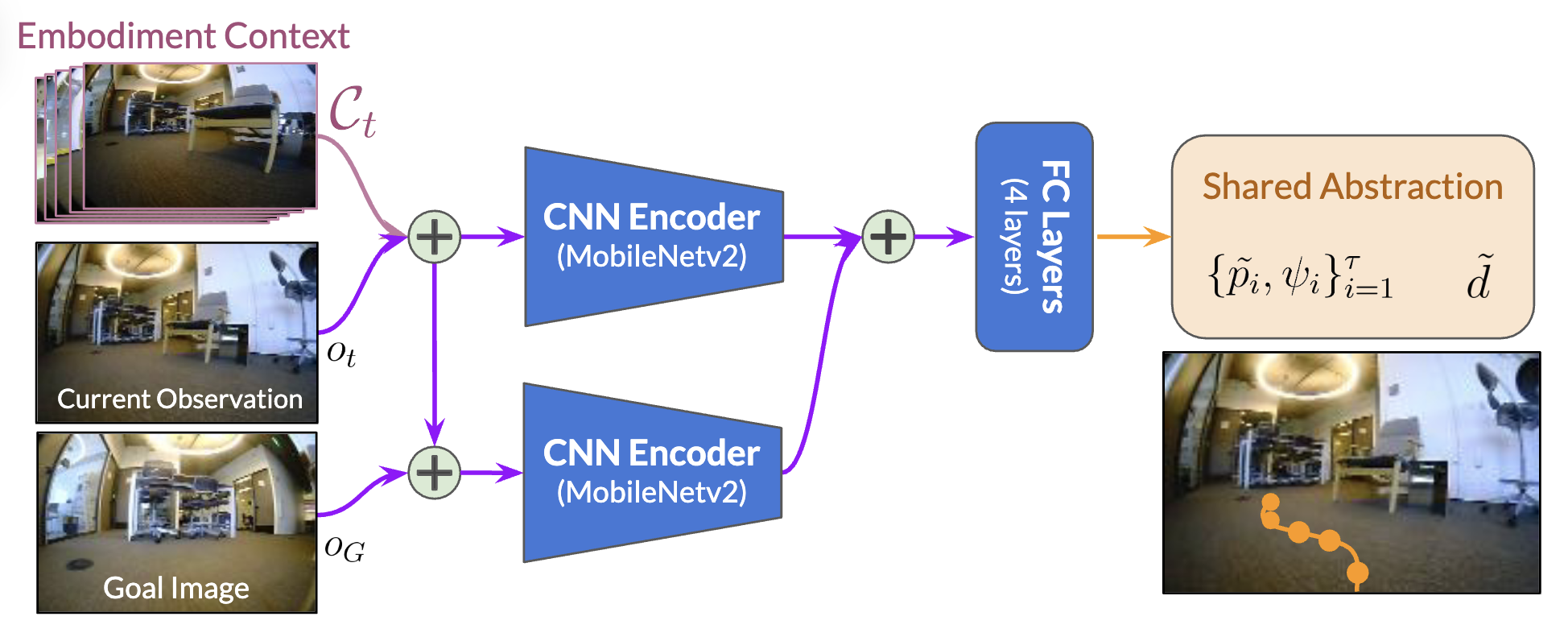
Other approaches use goal images (goal-based imitation learning, ref) or language instructions (Vision Language Navigation, ref), but both are unrealistic and inconvenient.
The former expects the model to predict actions between a current first-person image and a future first-person image.
The latter requires manually describing detailed instructions such as “go here, then turn there, then do X”.
Imagine being in a building for the first time and someone hands you an image or a paragraph of instructions and asks you to locate a destination—it is either ill-defined or extremely inconvenient.
Goal-image based navigation example
source: https://arxiv.org/abs/2210.03370
Language-instruction navigation example
source: https://www.arxiv.org/abs/2407.12366
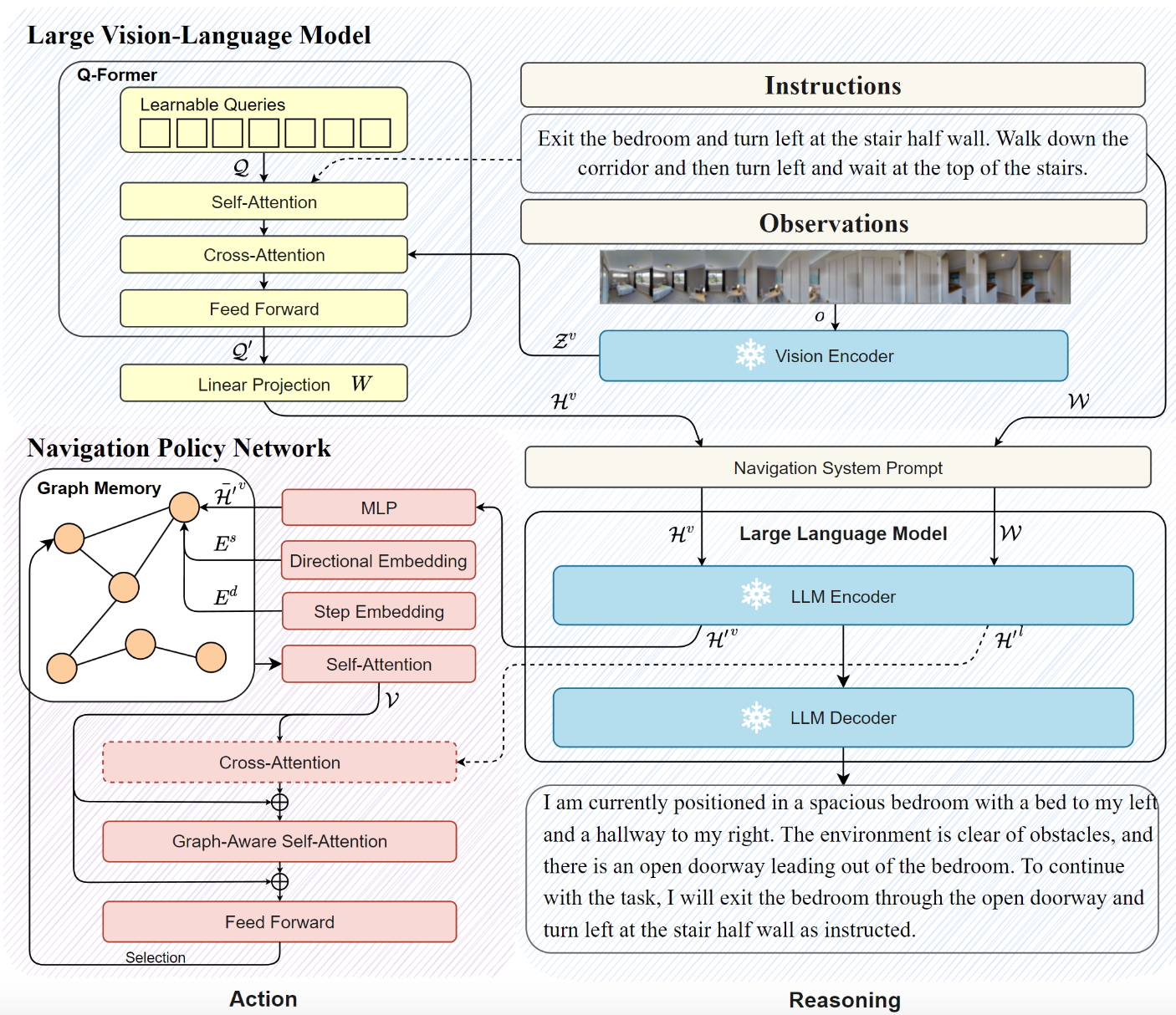
How does SketchDrive compare?
Instructable
We propose a sketch-based interface.
You draw → the robot drives.
It is much more convenient than natural language or goal images.

The robot reads human intent.
Even when instructions are inaccurate or ambiguous, the robot autonomously interprets meaning and drives appropriately based on context.
The demo above shows two examples:
- The robot follows intent even if you draw through walls or obstacles. (00:16–00:21)
- It functions even when objects exist in reality that are not on the map, or objects drawn on the map do not exist in reality. (00:00–00:16)
Language instruction is also referenced appropriately
The meaning of “appropriate” is identical to how humans interpret instructions. Humans do not prioritize sketch vs. language unconditionally; they decide based on context.
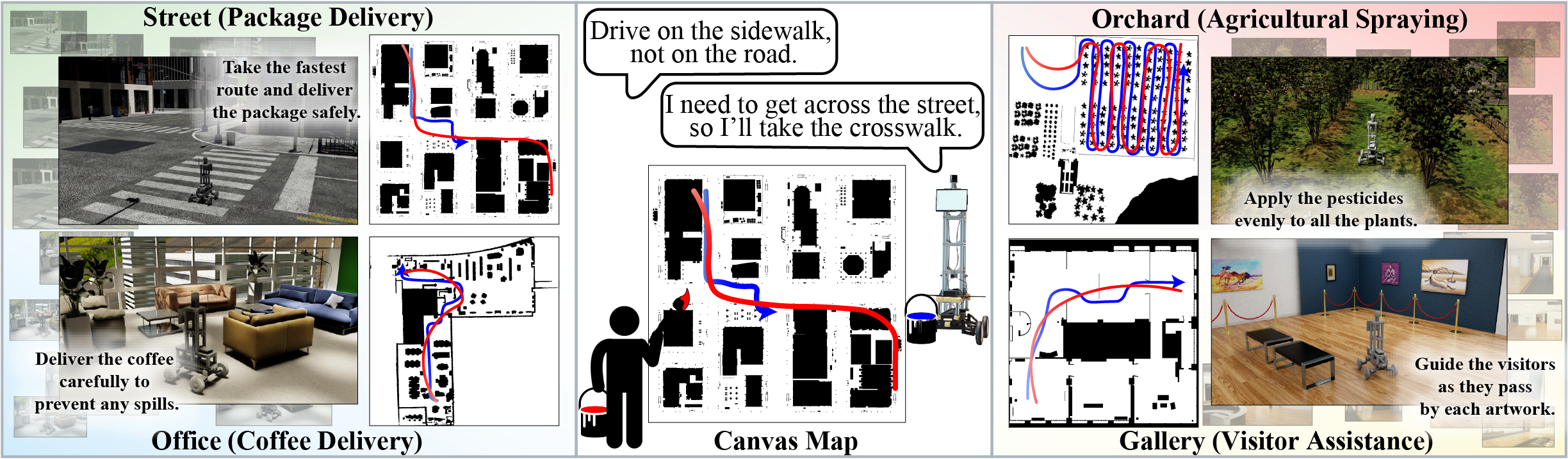
Since our model is LLM-based, it supports robot personas through prompts without modifying the model.
Examples:
- You are a pesticide-spraying robot in an orchard. Drive to maximize coverage over trees.
- You are a delivery robot outside the city. You must drive on the roadway/sidewalk.
- You are a cleaning robot. You must travel and collect trash based on human instructions.
This is demonstrated experimentally in CANVAS (link below), and figures are shown just above.
Generalizable (+ Scalable)
We use a data-centric approach, learning to drive from human demonstrations.
One of our main goals is to build pipelines for efficient large-scale data collection.
Unlike rule-based approaches requiring expert engineers to hand-design modules for months, our approach allows handling new cases simply by adding more data.
In fact, without writing a single if-statement related to driving logic, we collected data and trained a model that avoids humans and stop signs but drives through bushes.
Even more surprising is that it took only 15 days to collect the required data and train the model to perform like in the demo video.
There is strong synergy with LLM / MLLM, which have excellent generalization capacity thanks to internet-scale training—but perform poorly in embodied reasoning (BLINK, etc.). Since robotics has limited data and longstanding generalization issues, research continues to adapt MLLMs for embodied agents (RT-2, OpenVLA, etc.).
We follow the same approach:
- Large-scale imitation learning on top of large pretrained models to raise performance toward human-level
- And we benefit rapidly from progress in MLLM research by applying improvements to action models
CANVAS (2024.09)
In September 2024, we released:
CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction
Paper, video, and demos available here:
CANVAS overview video (includes driving demo).
Key contributions
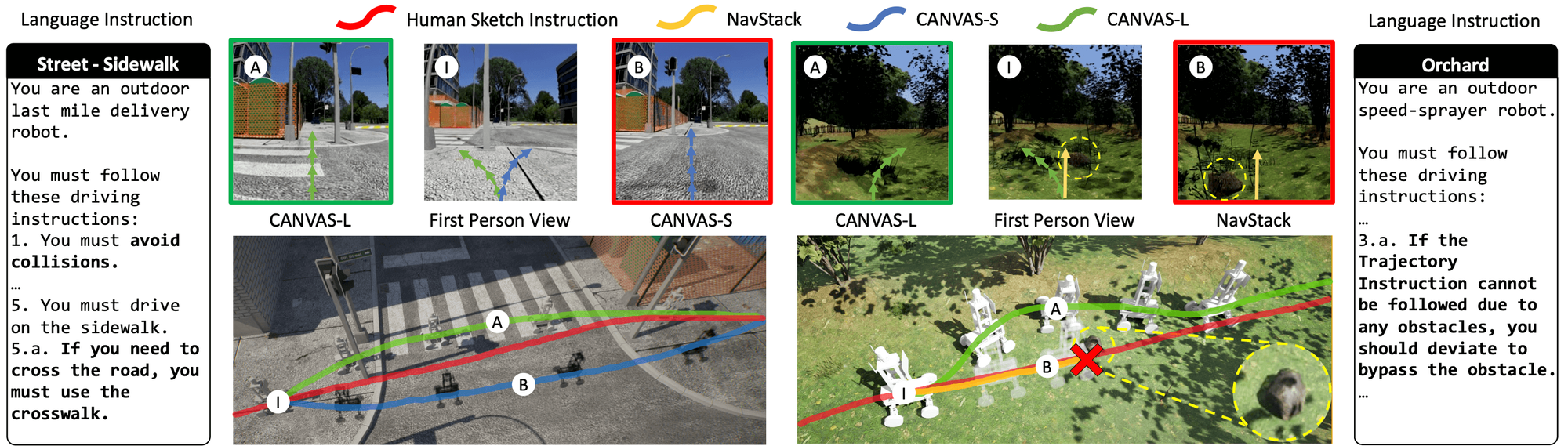
- Unlike previous methods that require inconvenient UIs, CANVAS supports natural language + sketch input, and understands intent even when input is partially incorrect.
- We defined misleading instruction, where instructions purposely lead through walls or obstacles, or direct a sidewalk-driving robot onto the road.
- Unlike methods lacking commonsense knowledge, CANVAS possesses commonsense for navigation.
- With a “sidewalk-driving robot” persona, CANVAS crosses crosswalks even if the sketch does not.
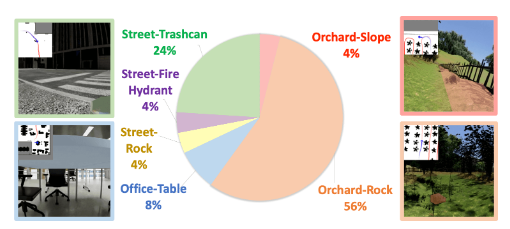
- CANVAS drives effectively. In orchard-map simulation, the baseline NavStack achieved 0% success, whereas CANVAS achieved 67%. When deployed on real hardware using simulation-only training, real-world success was 69%.
Considering that CANVAS is only the first experiment of SketchDrive, these are extremely promising results demonstrating feasibility.
Orchard terrain is highly uneven, where a single collision can cause the robot to fall or get stuck.
Challenging aspect of SketchDrive
From building the first result (CANVAS), we realized that agent research is far more difficult on the engineering side than the theoretical side.
Unlike earlier ML domains (CV, NLP) where dataset formats are simple and often provided by others, we must define and collect the data ourselves.
Additionally, we must implement closed-loop evaluation pipelines that run in both simulation and real environments. This requires strong software engineering, not just ML knowledge.
The implementation load is also massive. As described in the previous article, our repository surpassed 22,000 lines of Python code within three months.

Without strengths in software engineering and CS fundamentals, building interconnected multi-component systems is extremely difficult.
Connecting sub-repositories and designing systems with holistic perspective is difficult without strong engineering ability.
There are also substantial burdens imposed by real-time constraints:
- Video processing is heavy; a single mis-designed component becomes a bottleneck.
- Real-time video across network boundaries is even harder (e.g., WebRTC exists solely to solve this).
- Many libraries are not designed for real-time applications. OpenCV provides limited, inefficient video APIs, especially in Python.
- Even deep-learning libraries rarely support real-time embodied agents, so many components must be written from scratch.
(We plan to write a separate article about real-time video processing in embodied agents.)
Future of SketchDrive
CANVAS is only the first demo of the SketchDrive project.
Since we have already built the full pipeline—from data collection to preprocessing, training, evaluation, and deployment—changing the data immediately enables new capabilities.
Possible research directions:
- Strengthening language reasoning in visual agents [ref]
- Long-context aware agents
- Solving localization & control problems not handled in CANVAS
- Exploring architectures optimized for high-frequency action prediction
- Researching agents requiring actions beyond navigation
- RL finetuning after large-scale imitation learning (unsurprising idea—LLMs are trained similarly: pretrain → instruction tuning → alignment tuning; but rarely done in embodied agents)
There are many ideas not written here.
The WoRV team is actively recruiting Machine Learning Engineers and Machine Learning Software Engineers to work on SketchDrive and strengthen the engineering of the SketchDrive pipeline.