[KR] Agent 연구를 위한 monorepo 구성
안녕하세요, WoRV팀에서 Machine Learning Engineer로 근무하고 있는 최수환이라고 합니다. 현재 WoRV팀에서는 비전을 활용한 embodied agent 연구 및 개발을 위해 파이썬 소스코드만 22000줄에 달하는(2024.10 기준) 모노레포 프로젝트(sketchdrive)를 구성해 사용하고 있는데, 이에 대해 소개해 드리려고 합니다. SketchDrive에 대한 자세한 정보는 이 링크를 참고하시면 좋습니다!
Embodied agent 연구/개발에 있어 아주 좋은 예시라고 생각하고 agent 연구를 시작하시는 분들께 적극 고려해보라고 추천드리고 싶습니다.
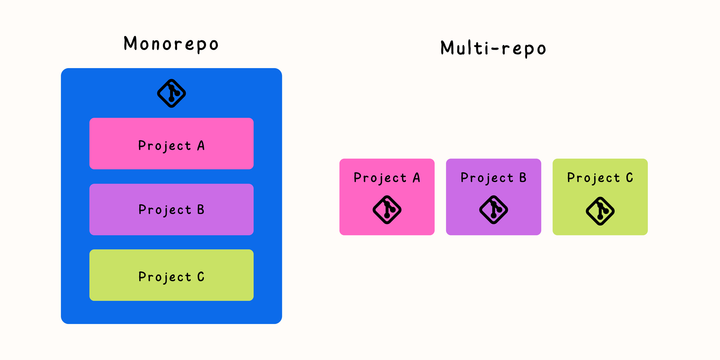
What's monorepo?
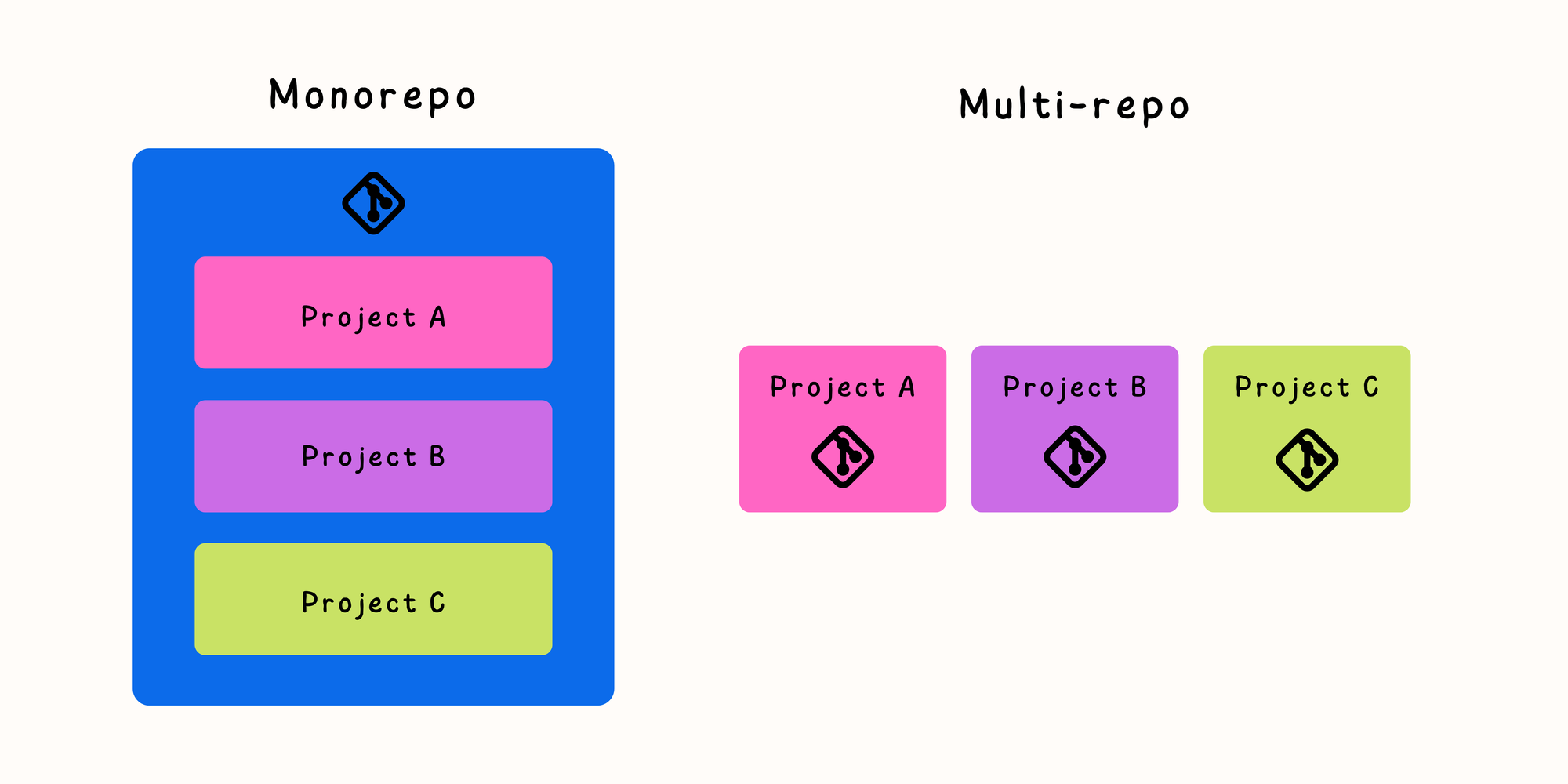
monorepo란 Monolithic Repositories의 약자로, 하나의 리포지토리에 여러 프로젝트가 들어있는 것을 말합니다. 통상적인 리포지토리들이 하나의 리포지토리에 하나의 프로젝트가 들어있는 것에 반하는데요, 이러한 예시로 ML 연구자들이라면 https://github.com/google-research/google-research 를 보셨을 것 같습니다. (좋은 예시는 아니라고 생각합니다 ^^;)
200여개 서비스 모노레포의 파이프라인 최적화, 팀워크 향상을 위한 모노레포(Monorepo) 시스템 구축을 보면 토스와 매스프레소(콴다)에서도 모노레포 구조를 사용하고 있음을 알 수 있습니다. Why Does Google Use Monorepo?에서도 Google, Meta, Uber 등 다양한 빅테크에서 모노레포 구조를 사용하고 있음을 밝힙니다. (사실 이 글에서 사용하는 정의에 따르면 저희가 사용하는 구조는 monorepo와 microrepo의 혼합형입니다.)
Why monorepo for agent?
monorepo 구조가 특히 이득을 보는 경우는 다음과 같으며, 또한 agent 연구/개발은 이 모두에 해당합니다. agent 연구를 시작하시는 분들께 모노레포 구조 도입을 추천드리고 싶은 이유입니다.
- 개발해야 하는 기능이 파이프라인 상의 여러 컴포넌트로 나뉘는 경우: agent 연구의 경우 데이터 수집, 전처리, 학습, 평가를 모두 작성해야 하고 각각의 컴포넌트의 크기도 작지 않기에 각각을 따로 리포지토리로 만들어야 합니다.
- 빠르고 유연한 구성이 필요한 경우: 연구 방식이든 뭐든 아직 정해진 정답이 없는 agent 연구에 있어 트렁크 기반 개발 방식을 사용하는 모노레포 개발은 매우 적합합니다. 늦어도 2주 내로 모든 브랜치를 머지하며, 또한 유연하게 여러 프로젝트에 걸친 변경사항을 개발할 수 있습니다.
Early structure of SketchDrive
저희가 모노레포 구조를 채택하게 된 계기를 설명하기에 앞서, 저희 레포지토리(sketchdrive)의 구성과 필요했던 기능들을 먼저 나열해 보겠습니다.
먼저, 저희 레포지토리는 다음과 같은 구조로 구성되어 있습니다.
- 데이터 수집 및 전처리 리포지토리
- 모델 학습 리포지토리
- 시뮬레이터 관련 소스코드가 담긴 리포지토리
- closed-loop로 simulator와 real(현실) 모두에서 모델의 성능을 평가하기 위한 리포지토리
.
├── agent
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
├── data_processing
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
├── data_collection
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
├── drive_evaluation
│ ├── agent
│ ├── auto_eval
│ └── model_worker
└── isaac_sim가장 초창기의 작업 과정에서는 이들을 모두 따로 구성했었는데요, 여러 가지 문제가 있었습니다.
- 패키지간의 의존성 문제: 위에서 언급한 리포지토리들은 embodied agent 학습에 있어 하나 이후에 다른 하나가 단계적으로 실행되어야 하는 구조입니다. 이러한 구조 하에서, 각각의 리포지토리를 따로 개발하면 서로 인터페이스나 기능상의 충돌이 나기 쉽고 파이프라인의 전반적인 integration이 힘들다는 단점이 있습니다.
- 개발의 어려움: 위에서 언급한 것과 비슷한 맥락인데, 전혀 다른 리포지토리에 유기적으로 이어져야 하는 여러 리포지토리들을 개발하다 보니 IDE만 해도 여러 개를 띄워놓고 개발해야 하는 등 어려움이 있었습니다. 여러 리포지토리에 걸쳐 구현이 필요한 기능의 경우 특히 개발이 어렵습니다.
- 중첩되는 코드: 여러 레포가 크게 분리된 형태로 개발하다보니, 서로 다른 레포끼리 같은 기능을 하는 코드를 여러 번 작성하게 되는 문제가 있었습니다.
또 저희의 usecase에서 고려할 만한 점이 여럿 있었는데,
- multiple dependency: 여러 리포지토리간에 서로 다른 (파이썬) 패키지 의존성을 가집니다.
- multiple environment: 단순히 파이썬 패키지끼리의 의존성을 넘어, 시스템 패키지의 의존성까지 다른 리포지토리가 존재했습니다. ROS(robot os)를 사용하는 부분이 그것인데, 예를 들어 모델 학습 리포지토리는 ROS가 필요치 않고 전처리하는 부분의 일부분은 ROS가 필요했습니다. ROS란 로봇 연구 및 개발을 도와주는 software library와 tool의 모음집인데요, 전통적인 OS와는 다르게 우분투 위에 시스템 패키지로 설치 및 가동이 가능한 Meta OS라고 합니다. 자세한 내용은 추가로 찾아보시면 될 듯 합니다.
- 각 리포지토리는 그 자체로 패키지인 경우도 있으며 아닌 경우도 있습니다. drive_evaluation은 대표적으로 패키지가 아닌 예시입니다.
Monorepo structured SketchDrive
위에서 말한 문제점들을 해결하고 저희의 usecase를 반영하기 위해 저희는 2024년 7월부터 모노레포 구조를 구상하고 사용하고 있습니다. 2024년 10월 기준 SketchDrive는 아래와 같이 구성되어 있습니다.
.
├── README.md
├── projects
│ └── agent
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
│ └── common
│ ├── README.md
│ ├── poetry.lock
│ └── pyproject.toml
│ └── data_collection
│ └── ...
│ ├── data_processing
│ ├── drive_evaluation
│ ├── isaac_sim
│ └── ros_common
├── ruff.toml
├── third-party
│ └── ...
└── workspace
├── ros_workspace
└── workspace- projects 폴더 아래에는 데이터 수집, 전처리, 학습, 모델 평가에 필요한 first-party project들이 들어있습니다.
- third-party 폴더 아래에는 git submodule 형태로 설치하는 third-party 프로젝트들이 들어있습니다.
- format/lint는 모두 ruff로 관리합니다. 파이썬 패키지는 모두 poetry로 관리합니다.
- 패키지간의 공통되는 내용은 common 패키지에 관리합니다. package name은 sketchdrive_common입니다.
- 패키지들끼리는 서로
../project-name과 같은 형태로 서로를 디펜던시로 삼을 수 있습니다. (poetry에서 지원합니다.) - 도커 이미지들은 workspace 폴더에서 관리하며, ROS와 관련된 도커는 따로 관리합니다.
이렇게 구성하며, 위에서 말한 모든 문제를 해결하며 저희의 usecase 역시도 반영할 수 있었습니다. common 패키지를 통해 중복되는 코드 문제를 해결했으며, 모노레포 구조를 사용했기에 의존성 고려나 개발(특히 여러 sub-repository에 걸쳐서 종합적인 변경이 필요한 기능)이 매우 편리했고, ROS와 관련된 디펜던시는 ROS가 실제로 실행이 필요한 부분은 도커로 남겨두고 나머지 부분은 rosbags라는 ros-free한 python only library를 사용하는 것으로 해결했습니다.
또한 이 구조는 여러 방식으로 확장도 가능합니다.
- project root는 기본적으로 설치 가능하지 않지만, poetry 설정을 통해 project root에서
poetry install --no-root --with train와 같은 커맨드를 실행하는 것으로 필요한 패키지들을 설치할 수 있습니다. project root의pyproject.toml을 아래와 같이 구성하면 됩니다.
[tool.poetry.group.train]
optional = true
[tool.poetry.group.train.dependencies]
agent = {path = "projects/agent", develop = true}
data_processing = {path = "projects/data_processing", develop = true}Convention for monorepo
구조는 이 정도로 좋습니다. 다만, 모노레포 구성을 할 때 구조보다 더욱(사실은, 훨씬!) 유의해야 하는 것은 협업 컨벤션과 배포 방식입니다. 배포에 관련해서는 토스의 200여개 서비스 모노레포의 파이프라인 최적화를 참고하시면 도움이 될 것 같고, 다만 저희 프로젝트는 배포가 크게 필요없는 단계다보니 배포를 크게 고려치는 않았습니다.
- 트렁크 기반 개발: 모든 브랜치는 늦어도 2주 이내에 머지되는 것을 원칙으로 합니다. 작은 단위로 feature 개발을 해야 하며 주기적인 CI/CD로 메인 브랜치의 무결성을 지키는 것도 원래는 원칙인데요, 저희는 개발보다는 연구와 초기 PoC가 우선이다 보니 CI/CD는 크게 고려치 못했습니다.
- 실제로 저희의 경험상 지나치게 머지가 늦어진 PR의 경우 상당한 merge conflict에 따른 resolve 비용을 감당해야 했습니다.
- 브랜칭, 커밋 네이밍 컨벤션: 브랜치와 커밋에는 주된 변경 대상인 프로젝트의 이름이 들어가야 합니다.
feat/drive_evaluation/reset-latency같은 것이 브랜치 이름의 예시,docs(drive_evaluation): add documentation for real inference같은 것이 커밋 이름의 예시입니다.- 여러 프로젝트에 걸친 수정사항이 있을 경우, 주된 기능 구현 대상이 되는 프로젝트의 이름을 사용하도록 유연하게 컨벤션을 정했습니다. 저희는 엄격한 관리보다는 빠른 개발과 생산성이 주 목표였기 때문입니다.
auto-eval
위에서 아주 잠깐 언급했지만, 저희 모노레포의 drive_evaluation 프로젝트에는 auto_eval이라는 폴더가 포함되어 있습니다. 여러 시뮬레이션 환경 위에서 자동으로 모델의 주행 성능을 평가하기 위한 소스코드를 담고 있는데요, 이것이 필요한 이유는 agent 연구에는 closed-loop eval이 필수적이기 때문입니다. closed-loop eval이 뭔지 설명하기 위해서는 open-loop eval과 비교해야 하는데요, 자세한 내용은 [ref]를 참고하시면 좋습니다.
- open-loop evaluation: 모델의 출력이나 에이전트의 행동이 세계(world)에 변화를 일으키지 않는 셋업에서 진행한 평가를 말합니다. real-world의 성능과 괴리가 있다는 치명적인 한계가 있으나 실행 자체에 무시할 수 없는 비용이 드는 환경(시뮬레이터 혹은 현실)이 필요가 없다는 장점이 있습니다.
- 자율주행 분야 연구에서 데이터 상의 sensory input을 모델에 넣고 그것을 통해 얻은 predicted action이 실제 action과 얼마나 다른지를 재는 경우가 있는데요, 대표적인 open-loop evaluation의 예시입니다.
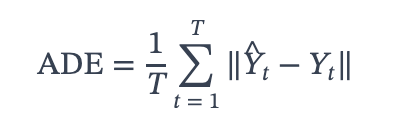
- closed-loop evaluation: 위와 다르게 모델의 출력이나 에이전트의 행동이 세계(world)에 변화를 일으키는 셋업에서 진행한 평가를 말합니다. real-world에서의 agent의 성능과 완전히 동일한 metric을 얻을 수 있다는 장점이 있습니다.
저희는 closed-loop eval이 믿을 수 있는 성능 평가에 필수적이라고 보고 자동으로 여러 시뮬레이션 환경(NVIDIA Isaac Sim 기반의 여러 scene)과 여러 주행 시나리오에서 모델의 주행 결과를 얻어낼 수 있는 파이프라인을 구축했습니다.
Future of SketchDrive monorepo
저희가 sketchdrive monorepo에서 추가적으로 염두에 두고 있는 구현 내용은 다음과 같습니다.
- 통합된 config 및 entrypoint 관리: 여러 프로젝트간 config가 산발적으로 관리되며 또한 각 프로젝트의 entrypoint를 찾기 어려움을 겪었습니다. project A에서는
python main.py로 스크립트를 실행했다면 project B에서는bash scripts/abc.sh와 같은 식으로 스크립트를 실행하는 식입니다. - 통합된 환경 및 도커 이미지 관리: 위와 비슷하게, 여러 프로젝트간 환경과 도커 이미지가 산발적으로 관리되고 있습니다. 비슷한 맥락으로 poetry 대신 ruff를 만든 astral에서 개발하는 uv를 도입하는 것도 염두에 두고 있는데요, 핵심 차이점은 poetry와 다르게 uv는 파이썬의 버전 역시도 관리하며 PEP621을 준수한다는 것입니다. 모노레포와 pytorch 관련된 여러 이슈가 열려있는데, 이들이 닫힐 즈음이 되면 도입을 적극 고려해볼 듯합니다.
- 자동화된 파이프라인 실행과 CI/CD: 지금은 전처리, 학습, 모델 평가에 이르는 파이프라인의 각 구성요소가 "각각" 자동화되어있습니다. 전처리가 한번에 되고, 학습이 한번에 되고, 모델 평가가 자동으로 한번에 되는 구조인데요, Apache Airflow와 같은 툴을 도입해 이들을 모두 이어서 자동화하는 것을 염두에 두고 있습니다. 또한 GitHub Action을 이용한 다양한 CI/CD, 테스트 코드도 현재 작성되어 있으나 고도화 예정입니다.
마무리하며
이번 글에서는 agent 연구/개발에 적합한 모노레포 구조에 대해 소개해봤습니다. WoRV팀에서는 2024년 9월 SketchDrive monorepo의 첫 버전을 완성해 CANVAS라는 연구를 진행하였으며, 더 자세한 내용에 대해서는 SketchDrive를 소개하는 글에서 확인하실 수 있습니다. 현재 SketchDrive monorepo는 812개의 달하는 커밋과 22000줄에 달하는 python 소스코드를 포함하고 있는데요, 어떻게 하면 이 모노레포를 깔끔하고 정돈되면서 기능적으로 충실하게 구현할까 많은 고민을 하고 있습니다.
WoRV팀에서는 SketchDrive monorepo를 유지/보수하고 개선할 Machine Learning Engineer, Machine Learning Software Engineer role을 적극 채용중입니다!


