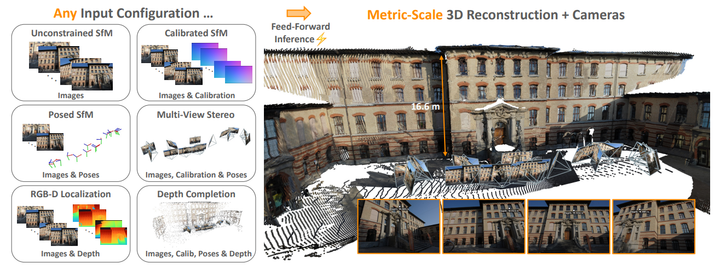
[EN] NeurIPS 2024 Review

Hello, this is Yongjun Cho, Senior Research Scientist on the WoRV team at MAUM AI.
This year has been incredibly eventful in the field of artificial intelligence, and NeurIPS 2024 was full of insights and inspiration. In this post, I would like to share our team’s experience attending NeurIPS—focusing mostly on Agents and Robotics.

NeurIPS 2024 Review
The Future of Agent & Robotics AI
New Trend in AI: Agent
One of the most striking keywords at this year’s NeurIPS was Agent.
Although the concept of an AI Agent is not yet strictly defined, it differs from traditional AI systems in the sense that an agent acts to accomplish a goal.
Traditionally, in reinforcement learning, an agent is defined as an entity that interacts with an environment to maximize a reward. However, with the rise of LLM Agents, the term now extends beyond reinforcement learning environments—
it now includes systems that execute instructions across various domains such as web automation, games, robotics, UI control, and API usage.
This trend was clearly visible throughout NeurIPS 2024, and in this post, I will summarize the research we analyzed at the conference.
From Seeing to Doing by Fei-Fei Li

The first talk I want to introduce is the invited keynote by Fei-Fei Li, which provided a historical perspective on the development of AI and insights into its future direction. It felt remarkable that she could narrate the history of AI purely through the evolution of her own research contributions.
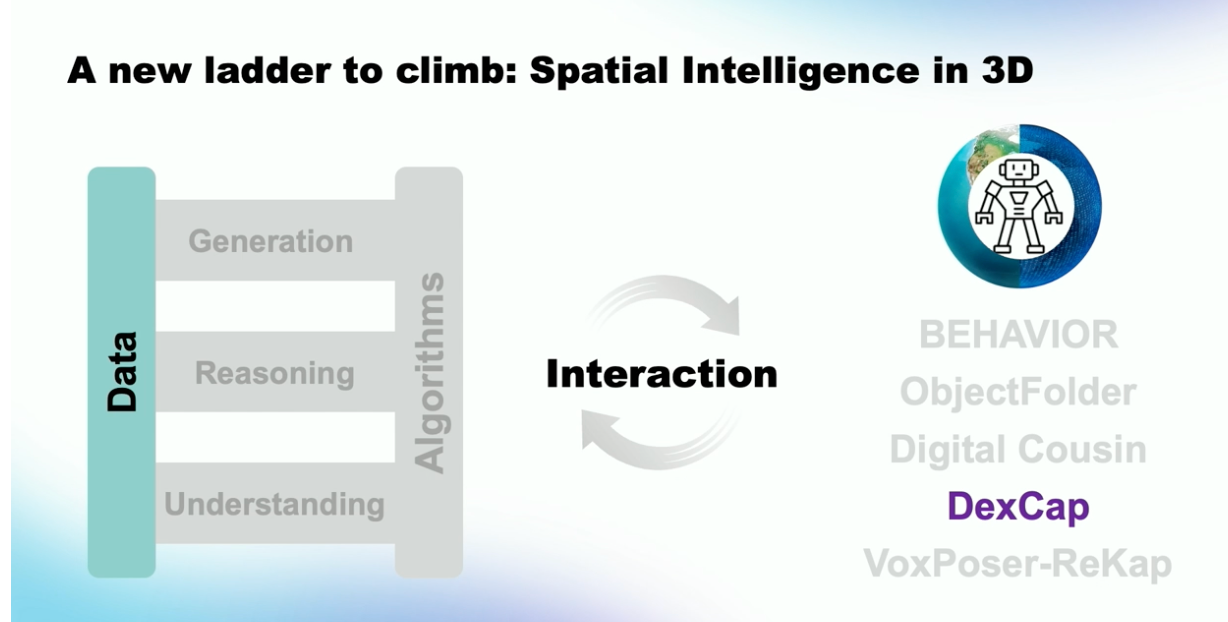
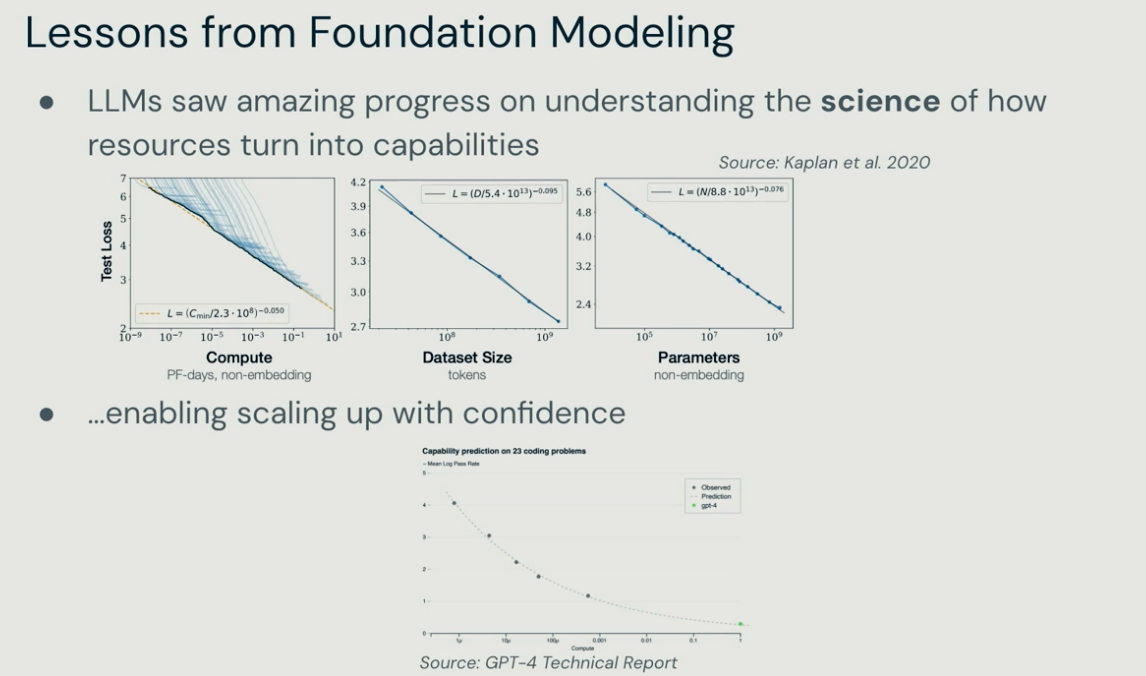
Fei-Fei Li stated that the advancement of artificial intelligence begins with two fundamental pillars: data and algorithms. She explained that current AI research climbs a ladder built upon these pillars through the tasks of understanding, reasoning, and generation. She introduced her own contributions—ranging from ImageNet to Scene Graphs and Diffusion Models—as representative steps along this ladder.
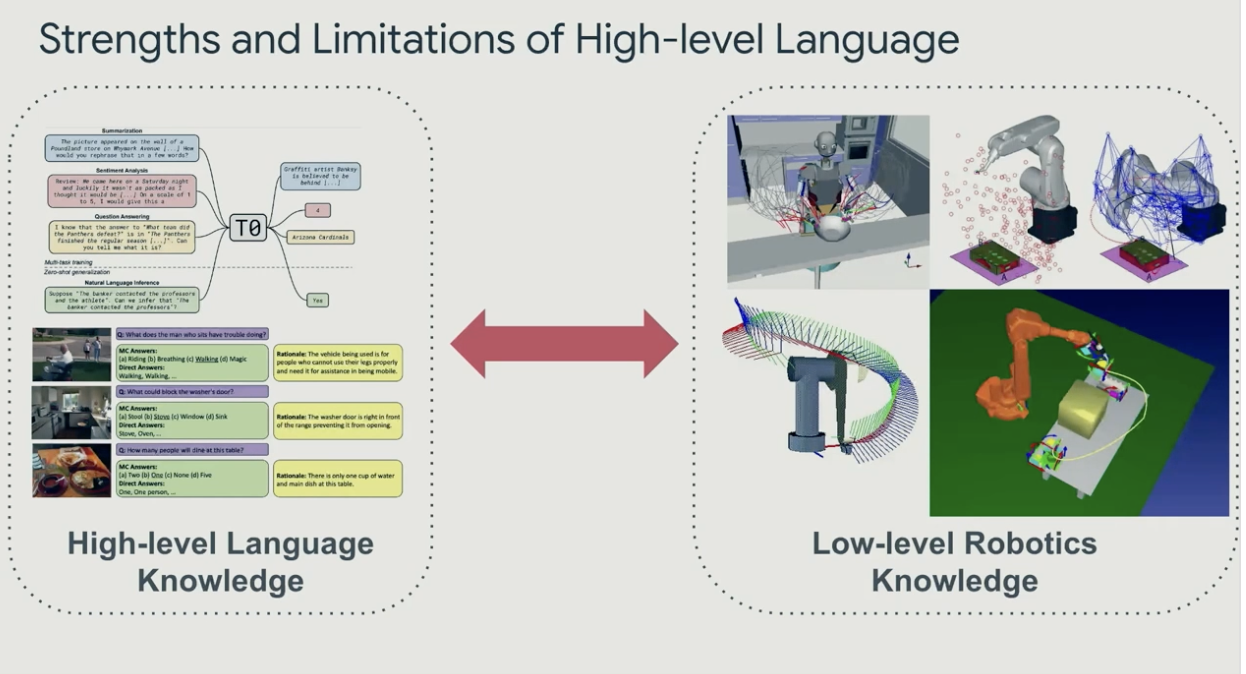
However, she emphasized that AI remains constrained within 2D environments of text and images. To overcome these limitations and achieve truly robust intelligence, she identified interaction with the real world as the next essential stage.
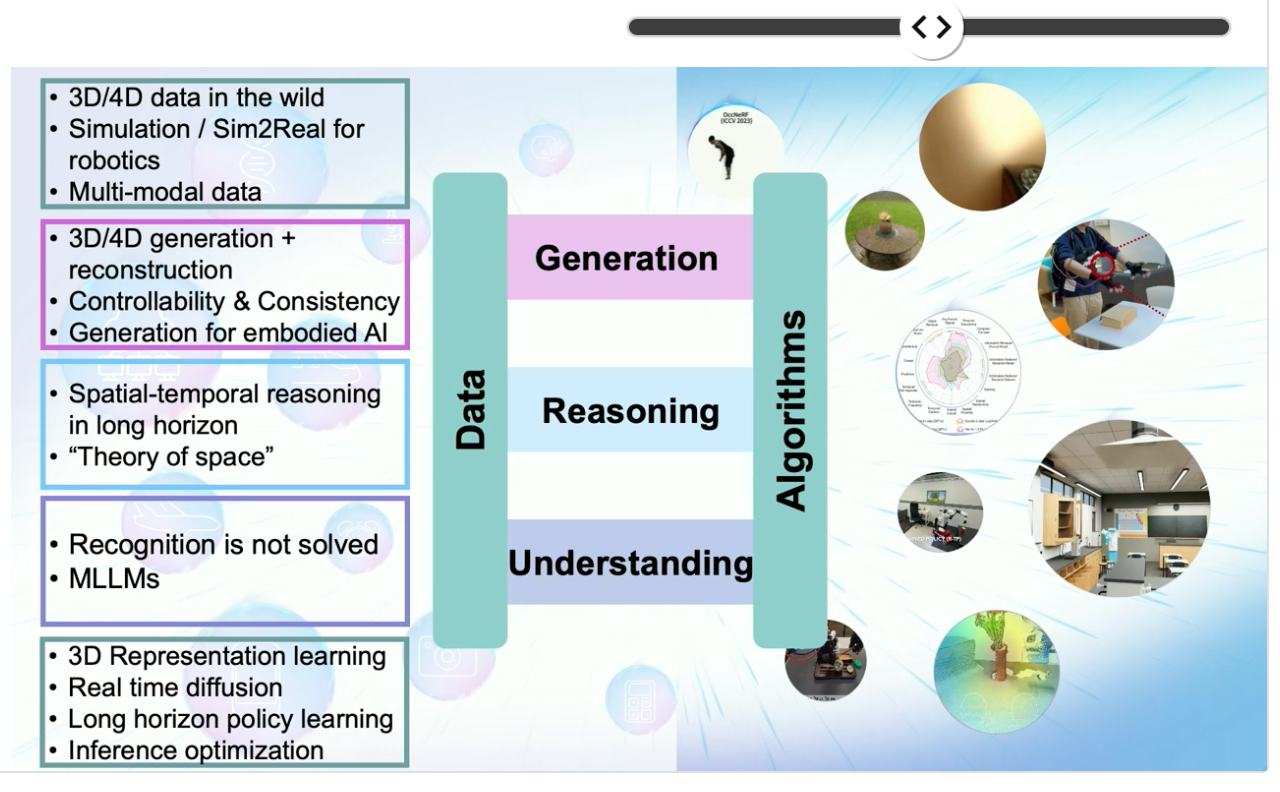

To develop artificial intelligence, she explained that AI must gain a deeper understanding of the real world, and that understanding, reasoning, and generation must all be achieved through interaction with the physical environment. She also noted that her recent research focuses on Robotics, multimodal models, and Embodied AI, asserting that AI will become a technology that augments humans rather than replaces them in the future.

Lastly, she introduced her newly founded company World Labs, presenting and promoting the potential of World Models.
Through this talk, we recognized a shared consensus among researchers around the world: although approaches and perspectives may differ, advancing artificial intelligence ultimately requires interaction data that captures real-world understanding.
AI for Autonomous Driving at Scale by Waymo

Next, there was an Expo Talk Panel by Waymo. Through this presentation, we were able to see how Waymo applies artificial intelligence to autonomous driving. As the title suggests, the talk focused on solving the challenges that arise when deploying AI-based autonomous driving systems at scale.
In reality, unusual events rarely occur while driving. Accidents or dangerous edge cases happen only occasionally. However, if an AI company operates hundreds or thousands of autonomous vehicles, and if they drive continuously for one or two years, these rare events are no longer small problems. At scale, they become issues that must be addressed. Waymo is tackling these challenges using AI—so what approach are they using?
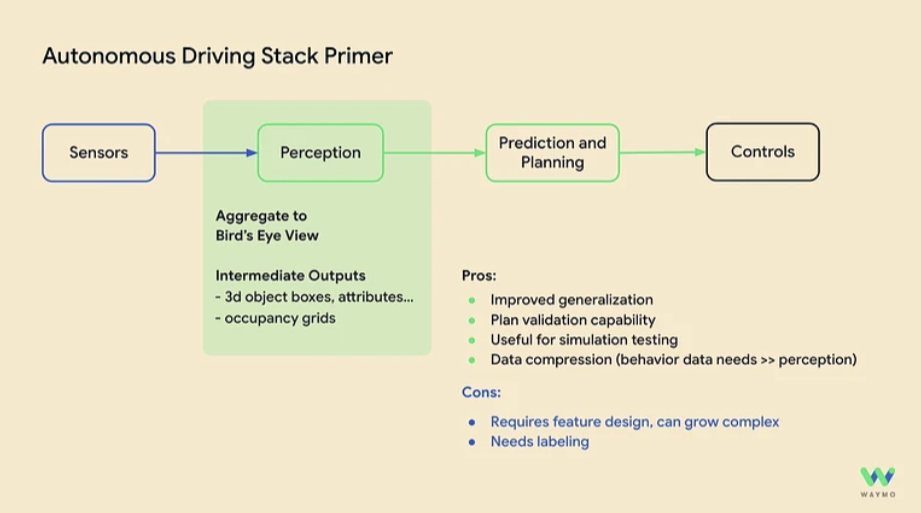
Waymo’s autonomous driving pipeline consists of three major modules:
- Perception
- Prediction & Planning
- Control
Among these, the Control stage does not currently use AI.
In the perception stage, to handle scalability-related challenges, Waymo uses Bird’s Eye View (BEV) representations that combine all sensor information. The advantages and disadvantages of BEV were summarized as follows:
Advantages
- Strong generalization performance
- Easy to evaluate planning quality
- Useful for simulation-based testing
- Enables efficient sensor data compression
Disadvantages
- Requires extensive feature engineering (high complexity)
- Requires large-scale labeled data

To build scalable AI systems on top of BEV, Waymo presented five key components, along with representative research such as Wayformer, MotionLM, SceneDiffuser, MoDAR, and Imitation Is Not Enough.

One topic that particularly interested us was their perspective on VLM/LLM Knowledge. Road environments are fundamentally built for human understanding—and it is impossible to collect training data for every road sign, emergency scenario, and rare event. Therefore, Waymo emphasized the need for reasoning and understanding capabilities derived from internet-scale training of VLMs and LLMs.
Waymo currently uses VLMs in two main ways:

- Data labeling — Expanding object classes using VLM-based label generation (e.g., MoDAR)
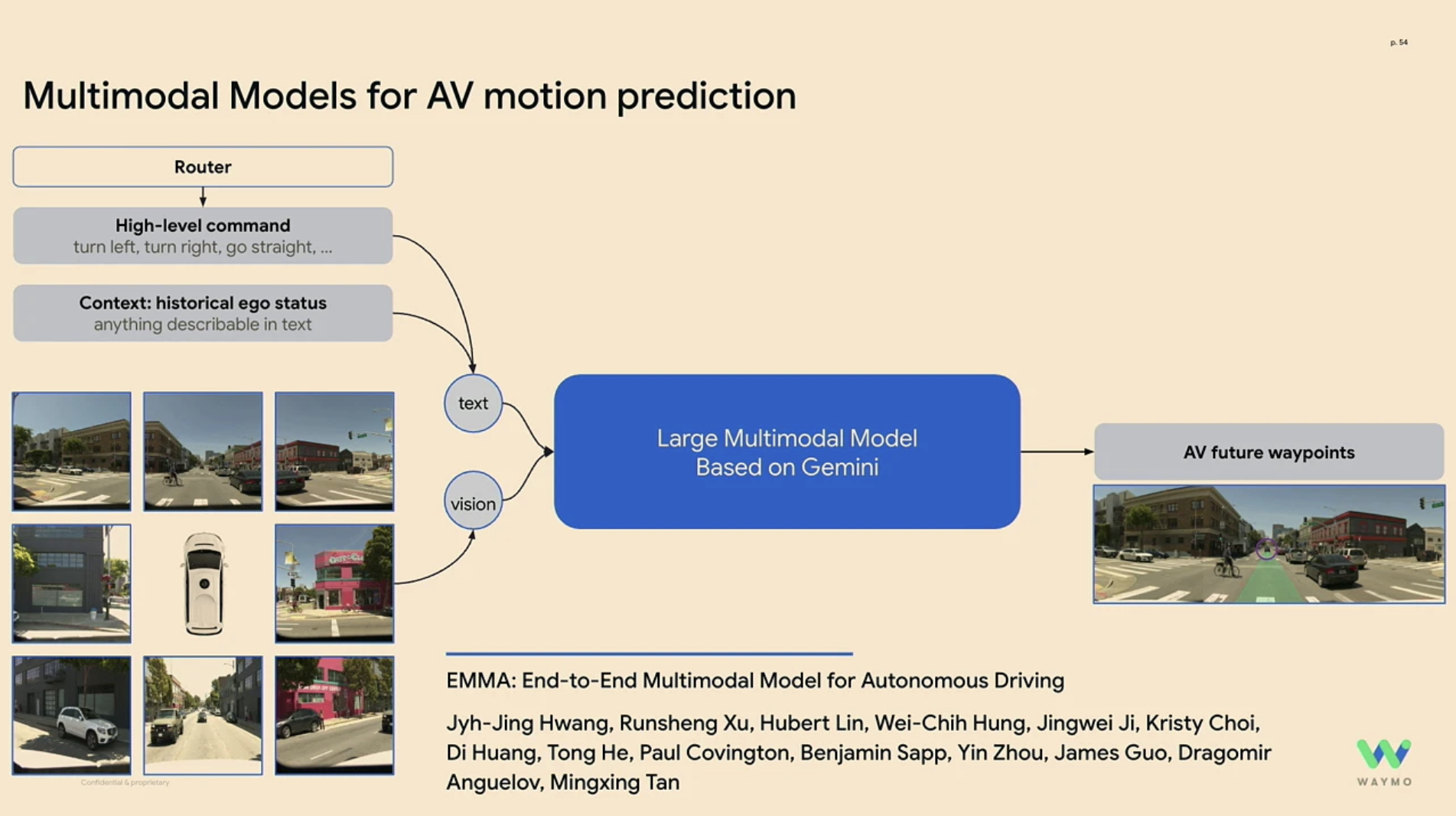
- Trajectory prediction — Using VLM-based forecasting as in EMMA, which uses Google Gemini to predict future motion based on sensor data
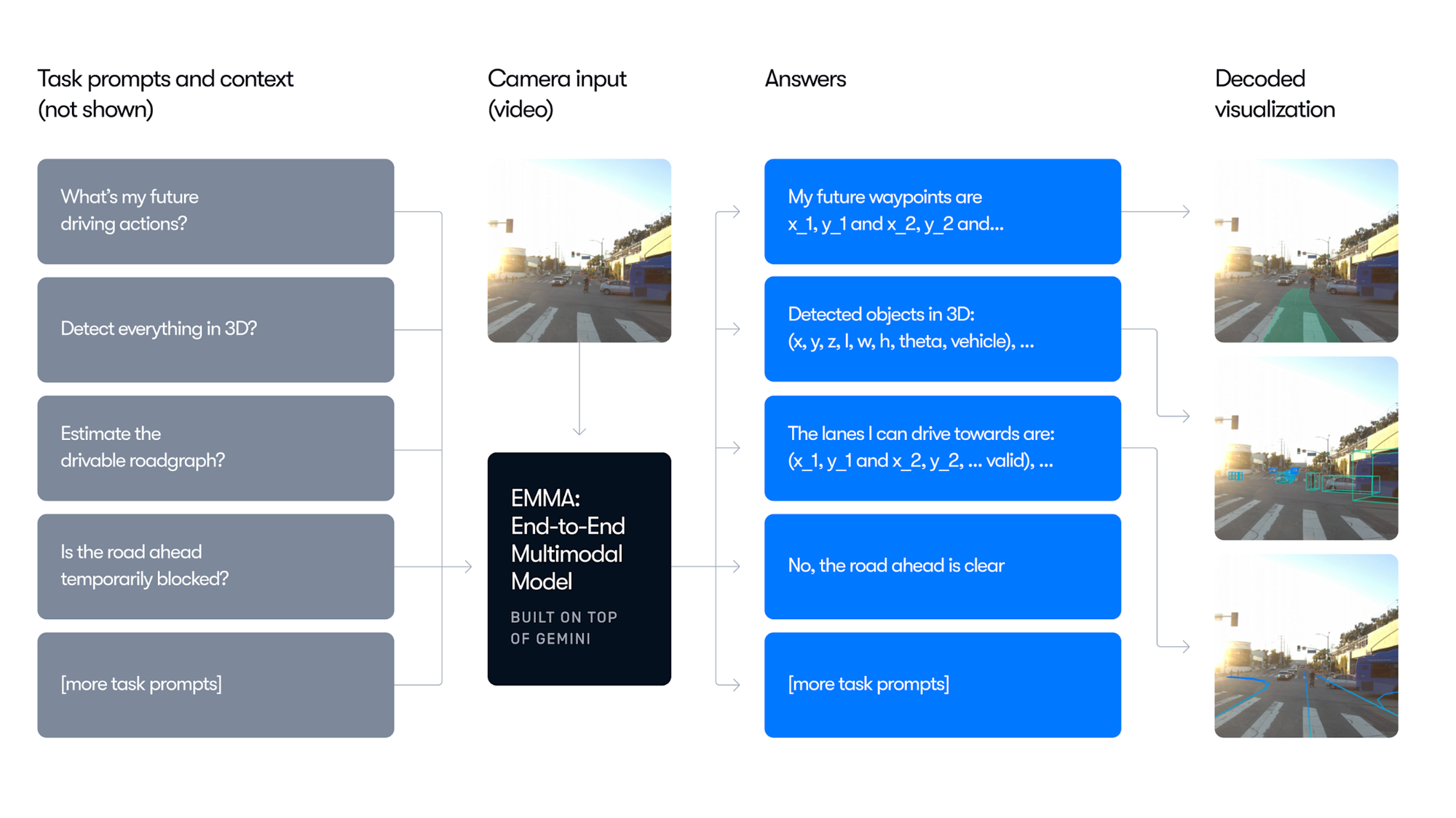
EMMA is trained to perform multiple tasks such as waypoint prediction, object detection, and lane detection, and applies chain-of-thought reasoning to improve end-to-end path planning performance by over 6.7%, while also producing interpretable reasoning traces.

However, based on the experience of a company that is actually operating autonomous vehicles on real roads, Waymo believes that VLMs are assistive tools, and that End-to-End autonomous driving remains a future goal. Their BEV-based system already performs extremely well in real-world deployment.
We believe that the reason we are able to build End-to-End autonomous driving AI is precisely because our situation is fundamentally different from Waymo’s. Waymo stated that the biggest challenges of BEV-based autonomy are the enormous amount of data required and the difficulty of manually engineering effective features. In other words, it demands extensive engineering effort and a scale of research and development that is difficult to match.
However, End-to-End autonomous driving is scalable, does not rely on manually designed features, and can be applied across a wide range of industries.
While researching End-to-End autonomous driving, our team strongly resonated with Waymo’s concerns regarding the limitations of current VLMs:
- Sensor data is far larger than language data and must be efficiently compressed.
- Current VLMs are not trained on 3D data and do not yet understand interaction with the environment.
- They lack human-like long-term memory.
- Training and inference efficiency must be significantly improved.
The WoRV team is actively researching solutions to these challenges. Furthermore, we aim to first solve autonomous driving problems that are particularly suited for VLMs, progress toward commercialization, and continue research with a focus on efficient learning, computation, and scalability.
NeurIPS Expo

At this year’s NeurIPS, interest came not only from academia but also from industry. Major big-tech companies and unicorn startups that everyone recognizes set up booths to attract AI talent, promote their work, and connect with researchers. Naturally, a huge crowd gathered, showing how strong the research community’s interest has become.
We first visited autonomous driving companies and began conversations with them. It was exciting to finally see companies like Waymo, Wayve, and Helm AI in person, rather than only through online information. At Tesla’s booth, we were also able to see the adorable Optimus humanoid robot.

Through conversations with Tesla engineers, we gained valuable insights about strategy in the humanoid robot market, research directions, and technical details.
We also met Unitree Robotics, whose impressive demo videos recently drew major attention. Seeing their quadruped and humanoid robots in person made us eager to purchase hardware and further develop autonomous navigation technologies. We discussed technical specifications and potential purchases directly with the Unitree team.
Beyond robotics companies, we spoke with employees from Meta, Google Research, Microsoft, Sony, and Apple. One surprising takeaway was that far more companies are researching Embodied AI than we expected, and that this shift seems to be happening faster than we had imagined.
NeurIPS Poster & Oral Session
The main event of NeurIPS was the Poster & Oral Sessions. Over the four days, we read a huge number of papers and attended many poster and oral presentations—more than 50 papers, just by rough count. Here, we briefly introduce two robotics-related posters.

The first was Humanoid Locomotion as Next Token Prediction from UC Berkeley. This work demonstrated that tasks like walking can also follow scaling laws, and we learned that training data for locomotion can be obtained not only from robot logs but also from human motion capture and videos.
A follow-up work has since been released: Learning Humanoid Locomotion over Challenging Terrain, which applies RL fine-tuning using the same training paradigm as LLMs—an exciting direction.
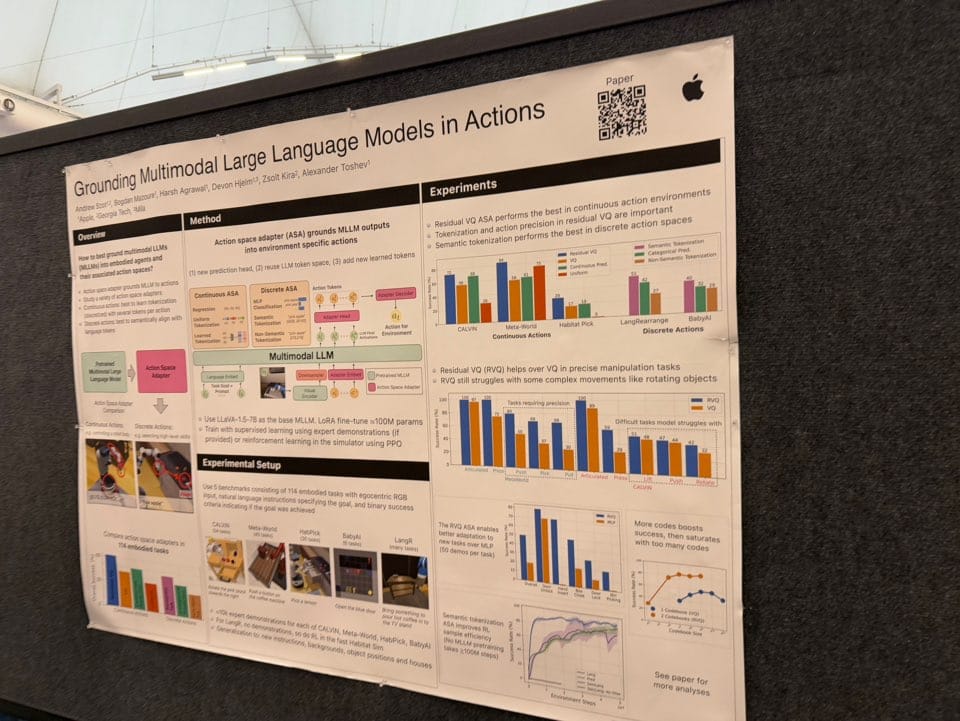
Another paper was Grounding Multimodal Large Language Models in Actions from Apple, which focuses on how to model efficient action embeddings for Vision-Language-Action (VLA) models.
The authors later released From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons, introducing the Generalist Embodied Agent (GEA), trained on action embeddings across robotics, gaming, planning, and UI interactions.
We attended many other presentations as well, and it was unfortunate that we could not cover them all here. We also networked with many Korean researchers and had meaningful conversations. Additionally, we held coffee chats with more than 30 applicants eager to join our team.
NeurIPS Workshop on Open-World Agents (OWA-2024)
On the final day, we participated in the Open-World Agents Workshop. We had the opportunity to present our paper Integrating Visual and Linguistic Instructions for Context-Aware Navigation Agents, which was selected as one of only six oral presentations out of more than 100 poster submissions.
Details of the paper can be found in our blog post introducing the SketchDrive project.
Whats Missing for in RFM? by Google DeepMind, Ted Xiao

One of the most insightful moments of the workshop came from Google DeepMind’s Ted Xiao, who discussed three missing components needed to build true robot foundation models:
- Scaling Laws
- High-bandwidth Contexts
- Scalable Evaluation
First, scaling laws: simply collecting more robot data does not guarantee improvement. We need cleaner, more transferable data and a shared representation for actions equivalent to what language provides for LLMs.
Second, high-bandwidth contexts: robotics requires extremely detailed state information. Recording all joint angles, velocities, and forces is too bandwidth-heavy, yet compressing this into language oversimplifies. Approaches such as affordances and trajectories may offer promising structured compression.

Third, scalable evaluation: unlike LLMs, robotic models must be assessed through interaction. Real-world evaluation is expensive and difficult; simulation allows cheaper approximate testing but cannot replace real deployment.

Recently, many AI models have been developed under the name world models, aiming to reconstruct diverse environments.
However, it is emphasized that simulation and world models can never fully replace real-world evaluation.
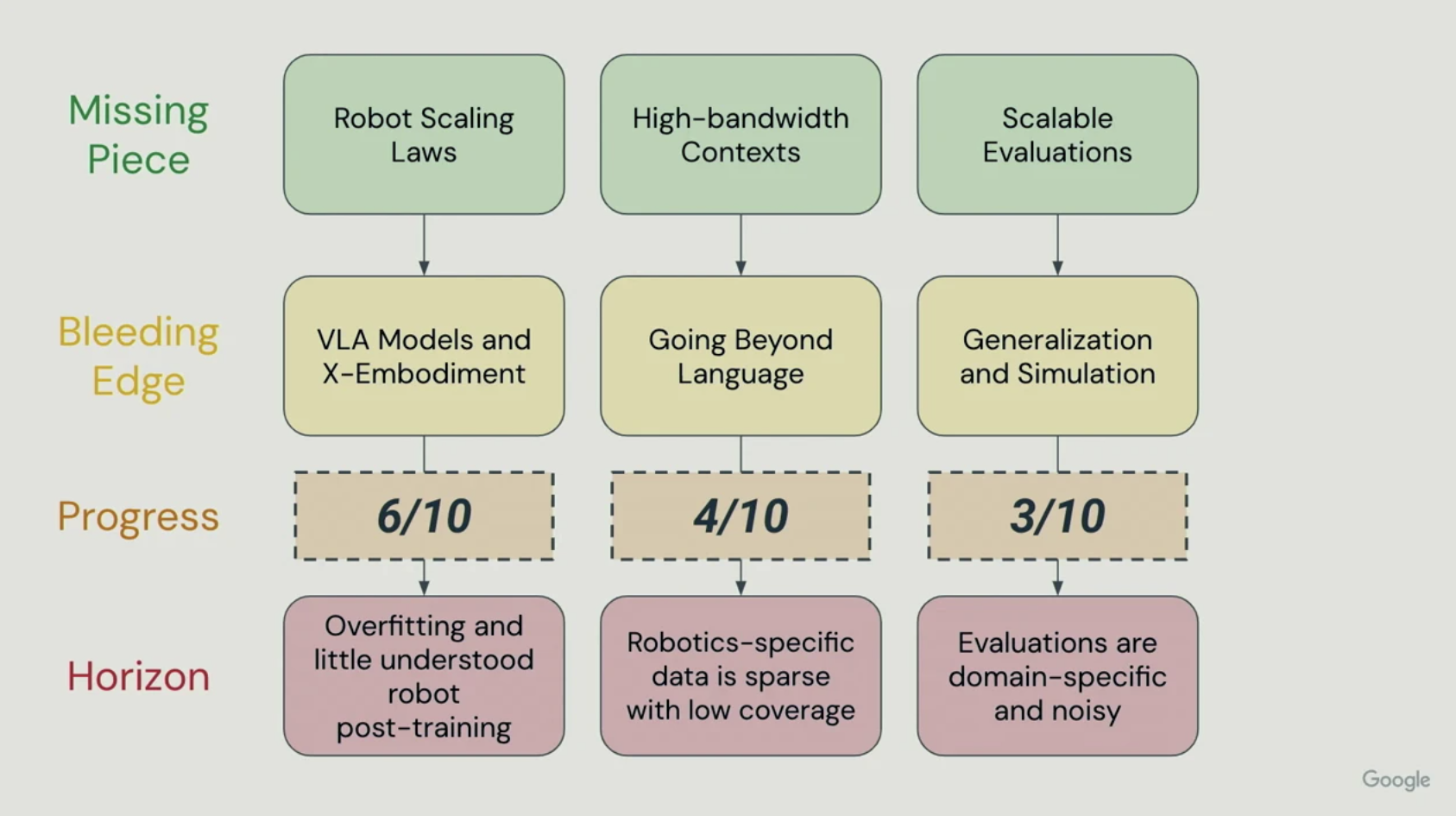
So, how far have we progressed so far?
As shown in the figure, Robot Scaling Laws are estimated to be around 60%, High-bandwidth Contexts around 40%, and Scalable Evaluations around 30%.
We hope to see significant advancements in the near future and eventually witness the emergence of a true robot foundation model.
After the talk, we had a conversation with Ted Xiao and asked about what the future of robot foundation models might look like.
Ted emphasized that future research must move toward natively multimodal models—models that are trained from the pre-training stage directly on robot sensor data and action signals.
However, considering the massive cost of developing large language models, he mentioned that building such models would require even more resources, and for now, leveraging existing LLMs may be the most practical path to achieving reliable performance.
Poster & Oral Presentation
In addition, during the poster session, we were able to explore a wide range of LLM and VLM agent research, starting with Meta’s Meta Motivo.
We also had a coffee chat with the CraftJarvis team, who presented ROCKET-1, and discussed in depth the development of environments for AI research—an area we had been actively thinking about ourselves.
Through this conversation, we were able to exchange valuable insights and lay the foundation for potential future collaboration.

After that, we anxiously waited for our oral presentation. Although we were quite nervous, we were relieved to finish the presentation successfully.
We also listened to presentations from the ShowUI team from NUS and Microsoft, as well as the Automated Design of Agentic Systems team from the University of British Columbia and DeepMind, who were presenting in the same oral session.

We already considered it a valuable opportunity just to present alongside such strong research teams, but after the session, it was announced that our paper had been selected for the Outstanding Paper Award, which made the moment even more rewarding.
It was an incredibly meaningful experience to engage with exceptional researchers and to have our work recognized among them.
I would also like to take this opportunity to express my gratitude to our team members and to Yonsei University MIR Lab, who devoted immense effort to making this research possible.
Closing Thoughts
Participating in NeurIPS 2024 was an invaluable opportunity for growth—both personally and as a team.
For the WoRV team at Mind AI, it was a chance to further elevate our work and share our research with the world.
Interacting with researchers and industry experts from diverse backgrounds, discussing the future direction of AI research, and openly debating the current limitations of AI were experiences that are hard to come by. We will continue pushing forward with research and development to create meaningful impact and earn recognition from the community.
If you are interested in the WoRV team, we’d be happy to chat—feel free to reach out for a coffee chat or apply through our recruitment page.
And if you’d like to stay updated on our research progress and the latest trends in Agent AI, please consider subscribing using the button at the bottom right.
Thank you for reading this long post.