[KR] SketchDrive 프로젝트 소개
이 글을 읽으면 좋을 것 같은 사람
- rule-based, modular하게 주행 로봇, 차량 자율주행 등을 개발하는 방식에 회의를 느끼시는 분
- 사람과 같은 에이전트(로보틱스, 게임, 데스크탑 제어 등)를 만들기를 원하시는 분
- ML 연구자/엔지니어로서 CV, NLP 등 기존의 메이저한 ML 분야를 넘어 새로 떠오를 분야(multimodal embodied agent)를 탐험하는 것에 관심 있으신 분, 인터넷에서 얻은 데이터는 끝나가고 앞으로 현실에서 얻은 데이터를 사용할 시간이 온다고 생각하시는 분
- 연구 단계에 그치지 않고 상업화까지 되어 실용적인 가치를 만들 수 있는 기술을 원하시는 분
- 이러한 일을 하는 저희와 같이 일하고 싶으신 분!
안녕하세요, 저는 WoRV팀에서 Machine Learning Engineer로 근무중인 최수환이라고 합니다. 이번에는 저희 팀에서 올해 중순부터 연구중인 SketchDrive 프로젝트에 대해 소개해드리려고 합니다.
Intro to SketchDrive
SketchDrive는..
- 사람과 같이, 하나의 모델이 여러 환경에서 지도를 보고 언어 지시를 받으며 시각을 통해 주행합니다.
- 사람과 같이, 상황의 맥락을 통해 사람의 지시에서 사람의 의도를 읽어 주행합니다.
- 기존의 로보틱스 주행 방법론들이 풀지 못한 2가지 문제, instructable과 generalizable를 풉니다.
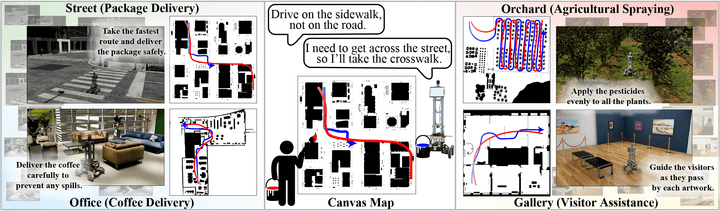
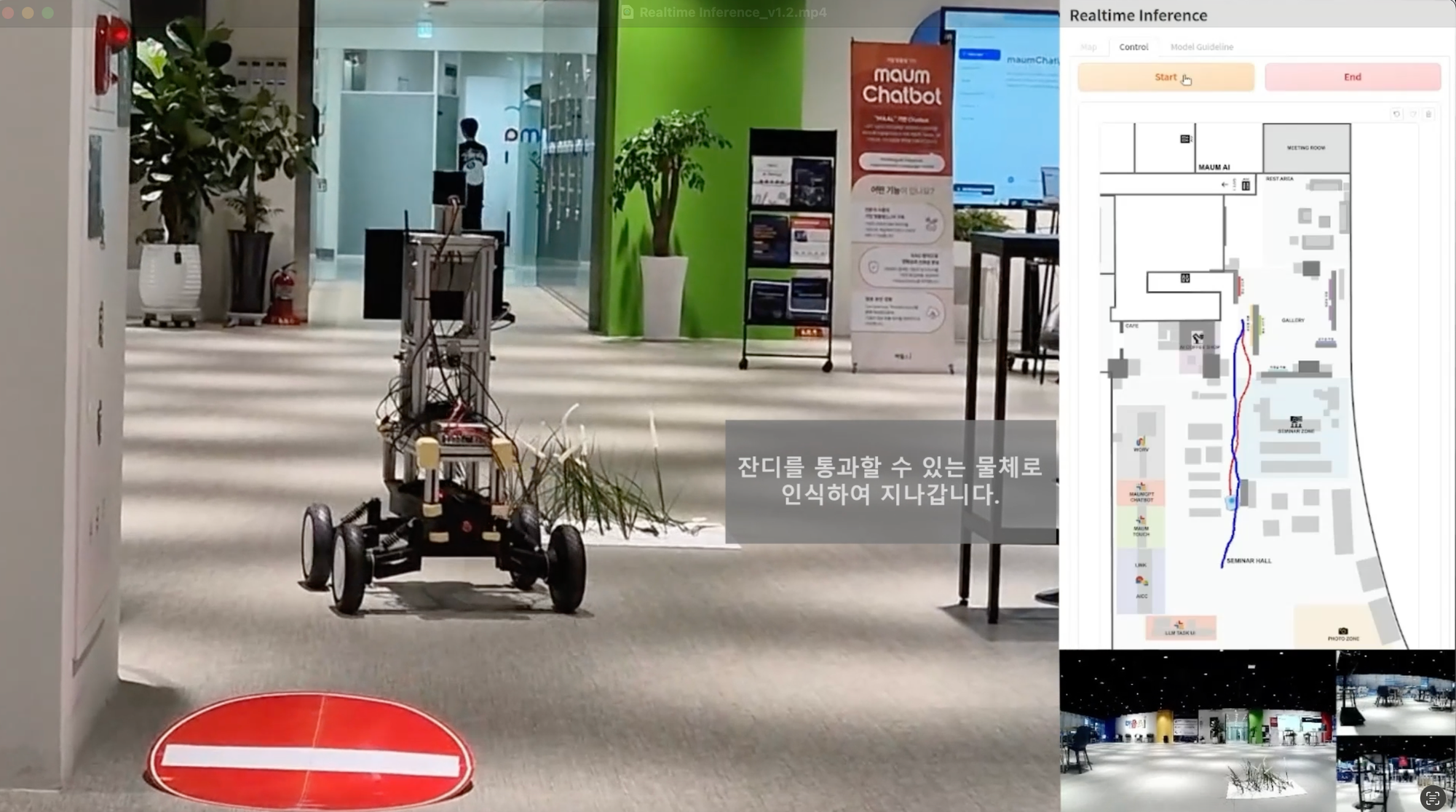
간단한 영상을 보여드리겠습니다.
약도 상에서 파란 선이 인간의 지시, 빨간 선이 로봇의 실제 이동 경로입니다.
- 저희 모델은 자연어와 시각 입력, 약도 입력을 모두 입력으로 받아 지시하는 사람의 의도를 읽어 주행합니다. 기본적으로는 약도 위에 그리면, 로봇이 갑니다. 물론 이뿐만 아니라 사람의 의도를 읽는다는 점에서 저희가 고려한 점도, 증명한 실험도 많은데, 이에 대해서는 차차 소개하겠습니다.
- 일단 전체 파이프라인을 만들어두니, 박스나 인간, stop sign, 수풀(지나가도 괜찮음)을 가르치기 위한 데이터를 수집하고 위 영상을 찍기까지의 모든 과정은 겨우 15일이 걸렸습니다. 기존의 방식에서 하나의 요소를 처리하는 하나의 컴포넌트를 뛰어난 엔지니어가 수개월간 연구해야 하는 것과는 전혀 다릅니다. 자세한 내용은 아래에서 읽어보실 수 있습니다.
- SketchDrive 프로젝트는 올해 6월부터 시작되어 겨우 4개월이 지났습니다. 위 영상은 CANVAS(뒤에 설명합니다)에 이은 겨우 2번째 데모일 뿐입니다. 저희는 저희의 접근을 통해 인간과 거의 동일한 로봇을 만들어 완전 자율주행, 상용화를 이룰 수 있으리라 보고 있습니다.
- 저희 팀은 적극적으로 채용을 진행중입니다. ML Engineer을 포함한 많은 role을 채용하고 있고 커피챗에도 열려있으니 언제든 연락 바랍니다.
Why SketchDrive?
저희 연구팀의 비전은 인간과 같이 행동하는 에이전트를 만드는 것입니다. SketchDrive 프로젝트는 이러한 비전에서 시작한 프로젝트로, 사람에게서 주행을 배우고 사람과 같이 주행합니다.
여기에서, "사람과 같이 주행한다"는 어떤 의미로는 굉장히 의미가 모호한데요, 정확히 무엇을 할 수 있다는 건지 구체적으로 소개해보겠습니다.
- 사람의 일반화 성능(generalizable)
- 사람은 한번도 보지 못한 장소에 가서도 화재대피도와 같이 추상화된 그림만 보고도 길을 찾아갈 수 있습니다. 기존의 로보틱스 연구 맥락에서 일반화라는 주제는 굉장히 오랜 시간 대두되어 왔지만 아직 풀렸다고 할 수 없습니다.
- 사람은 여러 로봇도 시행착오만 겪으면 다룰 수 있습니다.
- 사람의 다양한 지시를 받을 수 있는 능력(instructable)
- 바로 위의 예시를 이어서 예로 들면, 사람은 실제 지도와 완전히 같지도 않은 추상화된 지도를 가지고도 길을 찾을 수 있습니다.
- 더불어, 지도 위에 무언가의 지시를 어떤 형태로 그려주든 맥락에 맞게 이해하고 행동할 수 있습니다. 지시는 선이든 점이든 관계없으며 또한 벽을 지나치는 등 대충 표시가 되어도 사람은 지시자의 의도를 읽고 행동할 수 있습니다.
연구팀에서는 이 2가지 요소, generalizable과 instructable을 연구적으로 가장 중요한 토픽으로 보고 있습니다.
저희는 현재 navigation 문제를 풀고 있으나 사상적인 토대는 오히려 게임 에이전트인 SIMA에서 착안하고 있습니다. 저는 SIMA 연구진이 Scalable과 Instructable 뒤에만 comma(,)를 찍은 이유는 그것들이 그만큼 중요하기 때문이라고 함부로 짐작합니다.
이러한 요소들이 왜 중요할까요? 기존의 연구들은 어떨까요? 그러한 내용에 대해 바로 이어서 서술해보겠습니다.
기존의 접근들은 어떤가?
기존의 접근들에는 다음과 같은 문제들이 있습니다.
- 일반화 성능의 문제(generalizable)
- 이 문제를 해결하지 않고는, 연구 단계를 벗어나 상용화가 불가능합니다.
- 엄격히 통제되지 않은 환경(도심 등)에서 로봇을 가동할 때의 문제점은 인간이 예상치 못한 요소가 많다는 것입니다. 길가의 쓰레기나 장애물, 우천에 의해 생기는 물웅덩이, 다양한 곳의 턱 등 도심 환경의 자유도는 높습니다. 이러한 곳에서 인간이 사전에 그 존재를 고려하고 대응을 설계하지 않은 요소를 맞닥뜨리면 로봇은 주어진 태스크에 실패하며, 또한 위험 요소에 직면해 로봇에 해가 가해지면 안전한 상태로 되돌아오기도 힘듭니다.
- 특히, RL(reinforcement learning)을 사용할 경우 이러한 문제가 더더욱 두드러집니다. 자세한 내용에 관심 있으신 분은 아래 단락을 읽어 보시길 바랍니다.
RL에 대한 추가적인 이야기
RL은 보상(reward)가 잘 정의된 태스크에서 보상을 아주 잘 최대화하는 좋은 방법론을 제시해줍니다. 이는 정말로 효과적이어서 인간 최고의 바둑 기사를 이길 정도입니다. [Alphago] 하지만 "일반화"라는 태스크에 대한 reward는 잘 정의되지 않습니다. "여러 환경에서 적당히 잘 일반화되어 작동할수록 단조증가하는 무언가의 스칼라 값" 같은게 세상에 있을까요? 일반화 문제를 RL로 풀기 위해서는 그러한 스칼라가 존재하며 또한 구현이 가능해야 합니다.
하지만 implicit reward를 human demonstration에서 배워 “사람과 같은 모델을 만들면" 이 모든 문제는 해결이 됩니다.
심지어, 위에서 reward가 있으면 RL이 잘 작동한다고 말하긴 했는데, 사실 생각보다도 더 reward가 잘 정의된 상황은 드뭅니다. 굳이 일반화까지 말할 것도 없이 하나의 태스크에 대해서도 정의하기 어렵습니다. (reward shaping의 어려움)
차량 주행에 충돌에 -10, 충돌하지 않고 단위시간이 지나갈 때 0.1의 보상을 준다고 해봅시다. 뭔가 대충 말이 되는 것처럼 보이지만, 정말로 이 보상을 최대화하도록 모델이 학습했을 때 나오는 그 결과물 A가 당신이 머릿속에서 원하고 있는 모델의 주행인 B와 같다(A=B이다)라고 확신할 수 있나요? (A!=B인 경우가 두드러지는 경우가 유명한 reward hacking입니다.)
잘 모르겠으면, 그냥 그럴 거(A=B일 것이다)라고 가정해 봅시다. 그럼 이제 단순 차량 주행이 아닌 세밀하게 벽에 붙여서 청소를 해야 하는 로봇을 만들어야 한다고 합시다. 이 로봇에도 똑같이 리워드를 줄건가요? 조금 생각하면 그러면 안 된다는 것을 아실겁니다. 새로운 태스크에 맞춘 새로운 보상을 설계한다고 하면, 그럼 다른 100가지 용도의 로봇에 대해서도 계속 새로 보상을 설계할건가요? 아예 용도가 달라지는 것 뿐만 아니라, 사용자의 니즈가 하나라도 추가된다면(물웅덩이는 지나쳐주세요 등) 이러한 접근은 취할 수 없습니다.
더 관심이 있으신 분은 Sergey Levine 교수의 Should I Imitate or Reinforce?, Reinforcement Learning with Large Datasets: Robotics, Image Generation, and LLMs 와 같은 영상들을 보고 고민하시면 도움이 되실 것 같습니다.
또한, generalizable은 곧 scalable과 연결됩니다.
- generalizable <-> scalable
- rule-based algorithm에 크게 의존하는 방식은 뛰어난 엔지니어가 수개월의 연구를 통해 새로운 모듈을 개발하고 divide-and-conquer하는 방식입니다. 그에 반해, 저희와 같은 data-centric approach를 사용한다면 사람이라면 누구나 할 수 있는 행동을 데이터로 수집하여 더 scalable하게 발전할 수 있는 차이가 있습니다.
- 예시로 쉽게 설명해보겠습니다. 장애물은 무조건 피해야 한다가 기존의 로보틱스에서의 상식입니다. 그런데 정말 그럴까요?
- 키가 큰 수풀 환경에서 주행하는 것조차 기존 접근으로는 어렵습니다. 왜냐면 수풀이 지나갈 수 있는 수풀인지, 지나갈 수 없는 장애물인지 판단할 수 없기 때문입니다. point cloud에서 수풀을 지우는 연구[ref]가 따로 있을 정도입니다. 수풀을 지우면 그 다음에 또 다른 장애물은 어떻게 할건가요? 물웅덩이는요? 비닐봉지는요? 지나갈 수 있을수도 아닐수도 있는 임의의 지형지물은요? 이렇게 요소 하나를 처리하는 모듈을 추가하는 접근을 언제까지 반복해야 상용화가 가능할까요?
- 지시의 불편함 문제(instructable)
- 이 문제를 해결하지 않고는, 일반 유저에게 사용하게 할 수가 없습니다.
- 기존의 방식 중 지시로서 정확한 좌표를 받으며 또한 모든 알고리즘을 사람이 직접 설계하는 경우(conventional rule-based algorithm, ref)는 로봇이 “인간의 의도”를 읽어 그 상황에 맞는 주행 특성을 반영한 적절한 주행을 할 수 없습니다.
- 기존의 방식 중 목적지의 사진(goal-based imitation learning, ref), 언어(Vision Language Navigation, ref)와 같은 형태로 사용자의 지시를 기술하는 경우, 그러한 지시는 현실적이지 않고 불편합니다. 전자는 현재 이미지과 미래 이미지(모두 first-person view)가 주어졌을 때 둘 사이에 이어져야 하는 action을 예측하는 방식, 후자는 어디로 간 다음에 뭘 하고 이런 지시를 자연어 형태로 일일이 기술하는 방식입니다.
- 사람에게 처음 가본 건물에서 목적지의 이미지나 언어를 주고 찾아가보라고 했다고 상상하면 이해가 쉽습니다. 정보량 측면에서 푸는 것이 불가능하거나(ill-defined), 불편하거나 둘 중 하나입니다.
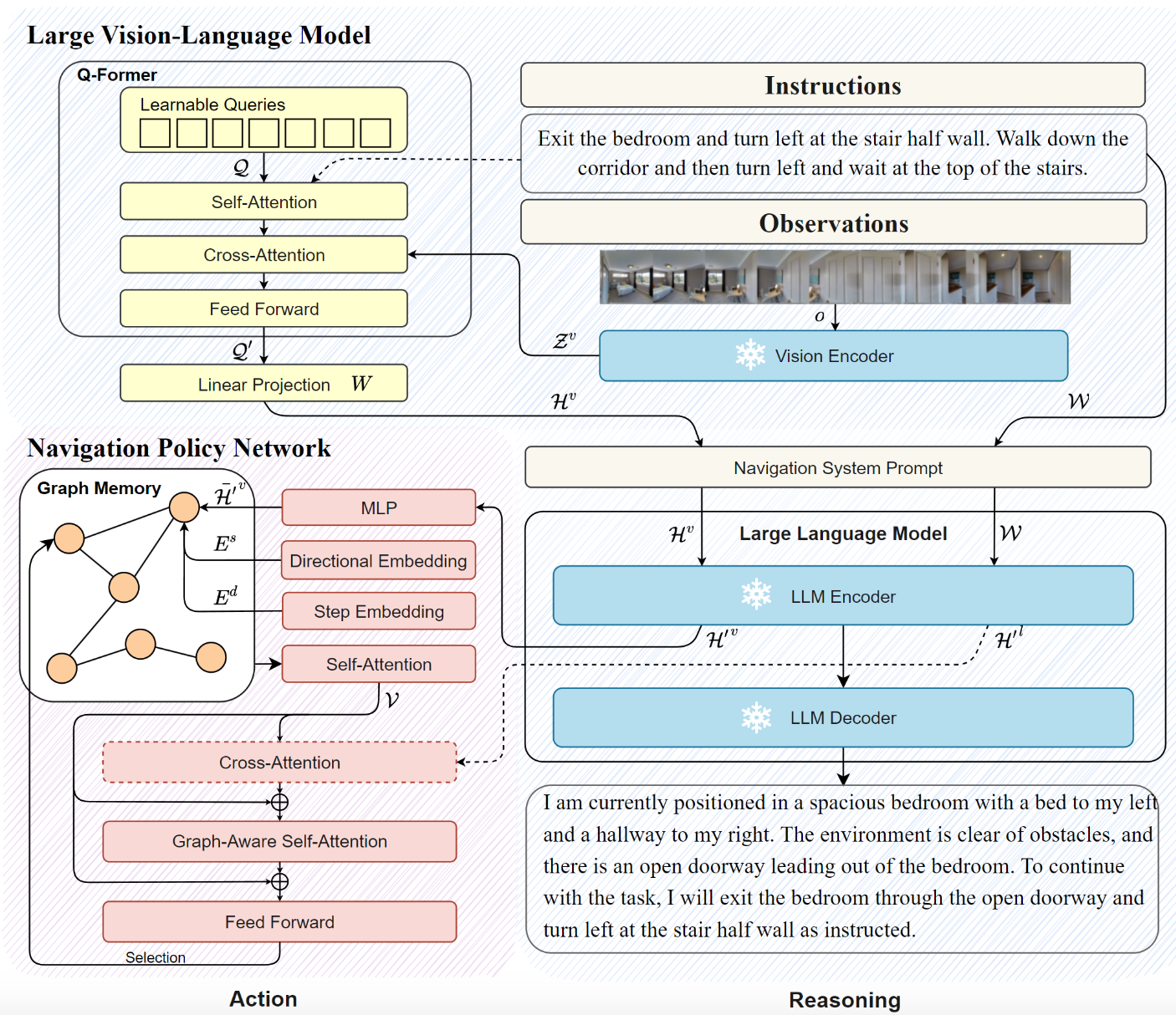
SketchDrive는 어떤가?
그럼, 저희가 진행중인 SketchDrive 프로젝트는 어떨까요?
Instructable
편리한 인터페이스로 sketch를 제안했습니다. 그리면, 로봇이 갑니다. 간단합니다. 자연어나 목적지의 사진 같은 형식의 인터페이스보다 훨씬 편리합니다.

로봇은 사람의 의도를 읽습니다. 주어진 입력이 부정확하거나 오해의 소지가 있어도 주어진 맥락을 기반으로 자의적으로 판단해 사람의 의도를 읽어 적절히 주행합니다.
위 영상에서 보여준 예시는 2가지입니다.
- 사용자가 약도 위의 장애물이나 벽 등을 지나게 지시를 줘도 의도를 읽고 따라갑니다. (00:16~00:21)
- 약도 위에 있는데 실제로는 없는 물체가 약도 위에 없는데 실제로는 있는 물체가 있어도 작동합니다. 사람과 박스와 잔디와 stop sign은 전부 약도 위에 없습니다. (00:00~00:16)
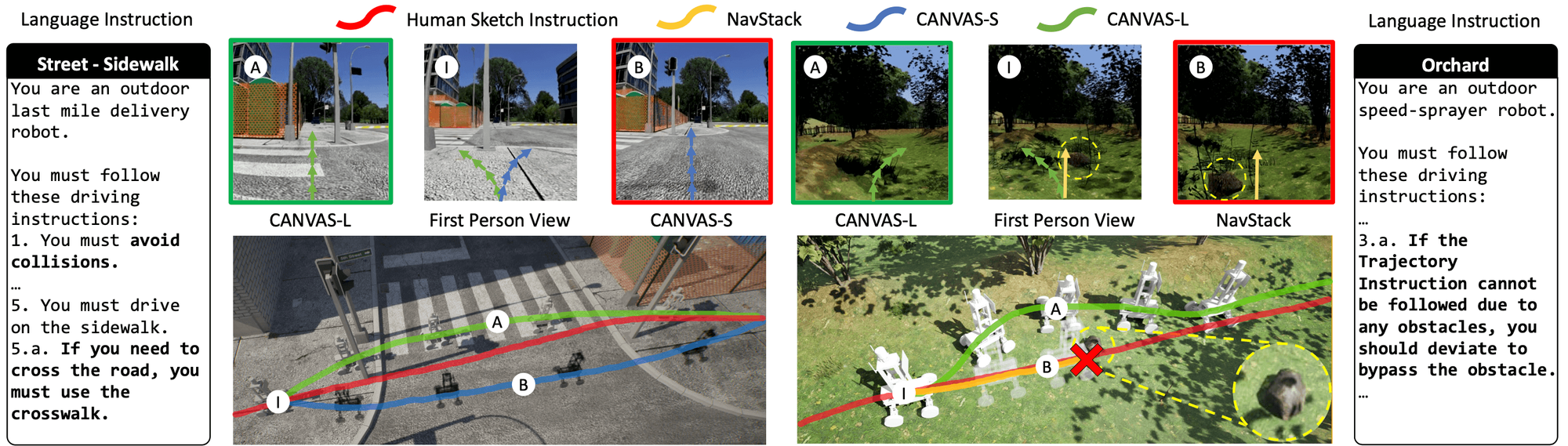
language instruction 역시도 적절히 참고합니다. 이 "적절히"의 선은 인간이 지시를 받을 때와 같다고 생각하면 됩니다. 예컨대, 인간은 sketch instruction과 language instruction 중 어느 하나를 무조건 우선시하는 것이 아니라 주어진 상황과 맥락, 정보에 따라 무엇 하나를 우선시해 행동할 수 있습니다. 저희 모델은 LLM(Large Language Model) 기반으로 만들어졌기에, 로봇 페르소나(robot persona)를 입력받고 그에 맞춰 전혀 다른 주행 특성을 단 하나의 모델로 프롬프트 외에는 아무것도 변경하지 않고 보여줄 수 있습니다. 로봇 페르소나의 예시는 다음과 같습니다.
- 당신은 과수원에 농약을 뿌리는 기계입니다. 인간의 지시를 반영해 최대한 골고루 농약을 살포하도록 주행해야 합니다.
- 당신은 시외 배달 로봇입니다. 당신은 차도(/인도)에서 주행해야 합니다.
- 당신은 청소 로봇입니다. 인간의 지시를 반영해 돌아다니며 쓰레기를 주워야 합니다.
이에 대해서는 CANVAS(SketchDrive의 첫 논문)에서 실험적으로 증명했으며, 그러한 내용이 담긴 Figure을 바로 위에 첨부했습니다. CANVAS에 대한 자세한 내용은 후술합니다.
Generalizable(+ Scalable)
data-centric approach로, human demonstration에서 주행을 배웁니다. 저희 팀의 주 목표 중 하나는 항상 많은 데이터를 효율적으로 얻을 수 있는 방법과 파이프라인을 구축하는 것입니다.
모듈 하나하나를 뛰어난 엔지니어가 수개월에 걸쳐 설계하는 rule-base 방식과 다르게, 저희 방식대로면 데이터만 추가하면 이런 모든 케이스를 처리할 수 있습니다. 실제로, 저희는 주행에 관련된 if문 단 한 줄도 작성하지 않고서 이 영상에서 보여주듯이 사람과 stop sign은 피하고 수풀은 지나가게 만들었습니다. 필요한 건, 그러한 데이터를 효율적으로 얻을 수 있는 파이프라인뿐입니다.
더 놀라운 것은, 원래 박스나 인간, stop sign에 대한 지식이 전혀 없던 모델에 대해 데이터를 모으고 학습시켜 이 영상과 같은 기동을 보여줄 수 있게 하는 데에 겨우 15일이 걸렸다는 사실입니다.
또 저희 접근과 연관이 있는 것은 LLM(Large Language Model), MLLM(Multimodal LLM)입니다. 이들은 internet-scale data를 학습하여 generalization 성능이 좋은데, 대신 embodied scene에 대한 추론 성능은 굉장히 좋지 않음이 알려져 있습니다. [blink 등] 인터넷 밖 현실의 데이터를 접한 적이 없기에 이는 꽤나 직관적으로 당연합니다. 그리고, 로보틱스에서는 데이터가 상대적으로 적고 generalization, scalability가 고질적인 문제가 되어 왔습니다. 이러한 상황 속에서 MLLM을 embodied agent로 튜닝하려고 하는 시도는 지속적으로 있어 왔습니다. [RT-2, OpenVLA 등] MLLM의 embodied scene에서의 성능을 높이며 동시에 로보틱스 태스크에 대한 generalizability를 internet-scale data에서 확보할 수 있기 때문입니다. 저희도 이들과 똑같은 접근을 취하고 있습니다.
large pretrained model 위의 large-scale imitation learning으로 human과 비슷할 정도까지 성능을 끌어올린다.
게다가, 지금이야말로 MLLM에 대한 연구가 활발히 이루어지고 있기 때문에 저희는 그 성능을 action 모델로 쉽게 가져올 수 있습니다.
CANVAS(2024.09)
2024년 9월 저희는 CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction 라는 이름의 연구를 공개했습니다. 이에 대해서는 아래 링크에서 아카이브(논문), 영상 등을 확인하실 수 있습니다.
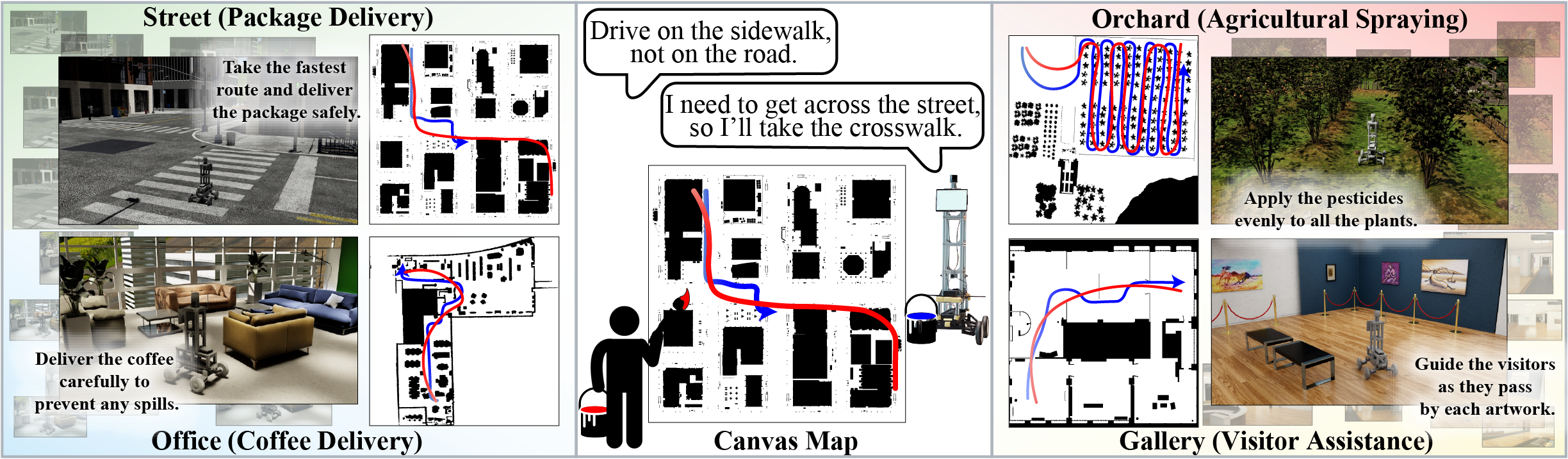
CANVAS의 설명 영상. 주행 데모 영상 역시도 포함되어 있습니다.
주요한 특징들은 다음과 같은데요,
- 기존의 방식들이 불편한 UI를 지닌 것과 달리, 언어와 스케치라는 편리한 UI를 가지고 있습니다. 또한 사람의 의도를 읽어 주행하기에 입력은 어느정도 잘못되거나 오차가 있어도 됩니다.
- 특히, 스케치 지시가 "잘못"된 경우를 "misleading instruction"이라는 용어로 정의하고 이에 대한 실험 역시도 진행했습니다. 벽이나 장애물을 지나게 지시를 그리거나, 인도에서 주행해야 하는데 차도로 지시를 그리는 것이 그 예시입니다.
- 많은 기존의 방식들이 세상에 대한 지식(commonsense)를 가지고 있지 않은 것과 달리, CANVAS은 가지고 있습니다. 사실, 아직은 commonsense 기반 주행이 가능하다를 보여준 것일 뿐이고, 실제로 사람과 같은 사고능력이 있음을 명시적으로 보여준 것은 아닙니다.
- street 맵에서 "인도를 지나는 로봇"이라는 페르소나를 자연어 형태로 모델에 부여했을 때, 스케치 지시가 횡단보도를 지나지 않더라도 로봇은 횡단보도를 지납니다. 즉, 일부 스케치 지시를 어겨서라도 페르소나를 따릅니다.
- 주행 자체도 잘 됩니다. 시뮬레이터 상의 과수원 맵에서 baseline인 NavStack은 0%의 성공률을 달성한 것에 비해, CANVAS은 67%를 달성했습니다. 또한 시뮬레이션 데이터만을 사용해 현실에서 로봇을 돌려봤을 때도 주행 성공률은 69%에 달했습니다.
- SketchDrive 프로젝트의 첫 실험이라는 것을 감안하면 굉장히 고무적인 성과이며 이 기술의 가능성을 엿볼 수 있다고 생각합니다.
- 과수원 환경은 지면이 굉장히 울퉁불퉁하고 돌에 한번이라도 충돌하면 로봇이 넘어지거나 끼이기 때문에 NavStack은 0%의 성공률을 달성했습니다.
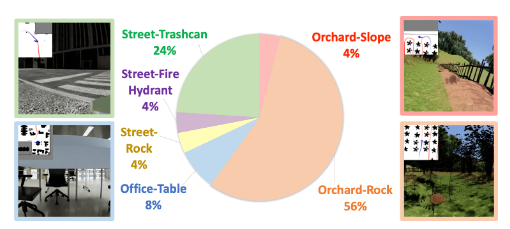
Challenging aspect of SketchDrive
SketchDrive 프로젝트의 첫 연구결과인 CANVAS를 만들면서 느낀 점은, agent 연구에 있어 이론적인 부분보다는 실제로 구현하는 과정에서 어려운 점이 굉장히 많다는 것입니다.
데이터를 다른 누군가가 만들어주는 경우가 많으며 또한 데이터의 형식이 간단한 이전의 ML 연구(CV, NLP 등)에 비해, 단순 학습 이외의 지점에서 고려할 점이 굉장히 많습니다. 데이터 수집과 데이터 정의 부분부터 ML Engineer가 손을 대고 설계해야 하며, 시뮬레이션과 현실에서 모두 사용 가능한 closed-loop evaluation pipeline도 작성해야 합니다. 이는 ML 지식보다는 강한(strong) 소프트웨어 엔지니어링 능력을 요구합니다.
구현 양도 굉장히 많습니다. 아래 글에서 소개했듯 저희 레포는 만들어진 지 3개월도 되지 않았음에도 파이썬 코드 수가 22000줄을 넘습니다.

또 소프트웨어 엔지니어링과 CS(Computer Science) fundamental에 강점이 있지 않으면 대다수의 컴포넌트를 만들기 힘듭니다. Agent 연구를 위한 monorepo 구성에서 소개했듯 여러 sub-repository간의 연계를 고려하며 종합적인 시야를 가지고 코드를 짜야하는데, 소프트웨어 엔지니어링에 강점이 있지 않다면 힘든 일입니다.
실시간으로 영상을 처리해야 하며 real-time agent를 만들어야 한다는 사실에서 오는 burden도 상당합니다. 첫째로, 영상은 너무 무거운 미디어 데이터이며 한 부분이라도 제대로 설계하지 않으면 병목이 생기기 쉽습니다. 실시간 영상처리를 네트워크를 타고 다니며 하는 건 더더욱 어렵습니다. 관련된 대표적인 기술스택(WebRTC)이 따로 있을 정도입니다.
둘째로, 기존 라이브러리들이 실시간 영상처리를 전혀 고려하지 않은 경우가 많기에 직접 개발해야 하는 부분이 많습니다. 예를 들어 컴퓨터비전 라이브러리 중 대표적인 OpenCV는 굉장히 한정적인 video 관련 api를 가지고 있어 제대로 사용하기 어려우며 그 성능이 좋지 않습니다. 특히, Python이라는 언어에 한정하면 사용할 수 있는 라이브러리의 폭이 더욱 좁아집니다. 딥러닝 관련 라이브러리 중에도 일단 영상을 처리하는 라이브러리가 희소하며 영상을 처리한다고 해도 real-time agent를 고려하는 라이브러리는 없다고 해도 무방합니다. 관련된 내용은 기회가 있다면 다음 글로 옮기겠습니다.
Future of SketchDrive
CANVAS는 SketchDrive 프로젝트의 겨우 첫 데모일 뿐입니다. 일단 데이터 수집부터 전처리, 학습, 평가와 배포에 이은 파이프라인까지 구축을 해뒀으니, 이 다음부터 데이터만 바꾸면 모델이 할 수 있는 일도 바로 바꿀 수 있습니다.
이 다음 ML 리서처로서 해볼 수 있는 선택지는 굉장히 많습니다.
- visual agent에 대한 언어적 추론 성능을 강화할 수도 있고[ref]
- long-context aware agent에 대한 연구를 해볼 수도 있고
- localization과 control등 저희가 CANVAS에서 풀지 않은 문제를 풀어볼 수도 있고
- high-frequency action prediction에 유리한 새로운 아키텍처를 탐험해볼 수도 있으며
- 주행 외의 다른 action이 필요한 경우에 대한 연구를 해볼 수도 있습니다.
- large-scale imitation learning 후의 RL finetuning을 추가로 적용한다면 어떨까요? 별로 놀랍진 않은 아이디어입니다. 이미 LLM이 그렇게 훈련되고 있기 때문입니다. (pretraining -> instruction tuning -> alignment tuning) 하지만 embodied agent에서는 아직 거의 시도되지 않은 방법입니다.
이곳에 쓰지 않은 아이디어도 많은데요, WoRV팀에서는 SketchDrive 프로젝트에 참가해 같이 이런 재밌는 연구를 진행하고 SketchDrive 파이프라인을 소프트웨어 엔지니어링적으로도 강건하게 만들 Machine Learning Engineer, Machine Learning Software Engineer role을 적극 채용중입니다!


