[KR] NeurIPS 2024 돌아보기

안녕하세요 저는 마음AI의 WoRV팀에서 Senior Research Scientist로 일하고 있는 조용준입니다.
올해도 인공지능 분야에서는 정말 많은 일이 일어난 것 같습니다. 이번 NeurIPS 2024도 볼거리와 배울 것이 굉장히 많은 학회였는데요. WoRV팀이 이번 NeurIPS에 참가하며 겪었던 경험을 Agent와 Robotics 위주로 여러분에게 공유드리고자 합니다.

NeurIPS 2024 돌아보기
Agent와 Robotics AI의 미래
AI의 새로운 트렌드 Agent
이번 NeurIPS에서는 Agent라는 키워드가 굉장히 인상적이었습니다. AI Agent는 아직 명확하게 정의된 바가 없지만, 어떠한 목적을 수행하는 행동을 한다는 점에서 기존 인공지능과 차이가 있습니다.
전통적인 정의의 agent는 강화학습에서 환경과 상호작용하며 특정 목적을 수행하도록 정의된 개체 입니다. 하지만 LLM agent가 등장하면서 강화학습으로 정의된 문제만 푸는 것이 아니라, 특정한 지시를 수행하는 경우에도 이러한 용어를 사용하게 되었습니다. 이러한 지시에는 Web UI, 게임, 로보틱스, API 사용 등을 포함하게 되었습니다.
이번 NeurIPS 2024에서도 이러한 트렌드를 크게 체감할 수 있었는데요. 이 게시글을 통해 저희가 분석한 NeurIPS 2024의 연구를 소개시켜드리겠습니다.
From Seeing to Doing by Fei-Fei Li

먼저 AI 연구의 방향을 보여준 Fei-Fei Li의 invited talk부터 소개하겠습니다. 이 강의는 그동안의 AI 연구가 어떻게 진행되었는지, 앞으로는 어떻게 진행될 것인지를 이야기하는 AI의 역사 강의라고 볼 수 있습니다. Fei-Fei Li 본인의 연구만을 설명하는데 AI의 역사를 이야기한다는 것이 신기하고 대단한 것 같습니다.
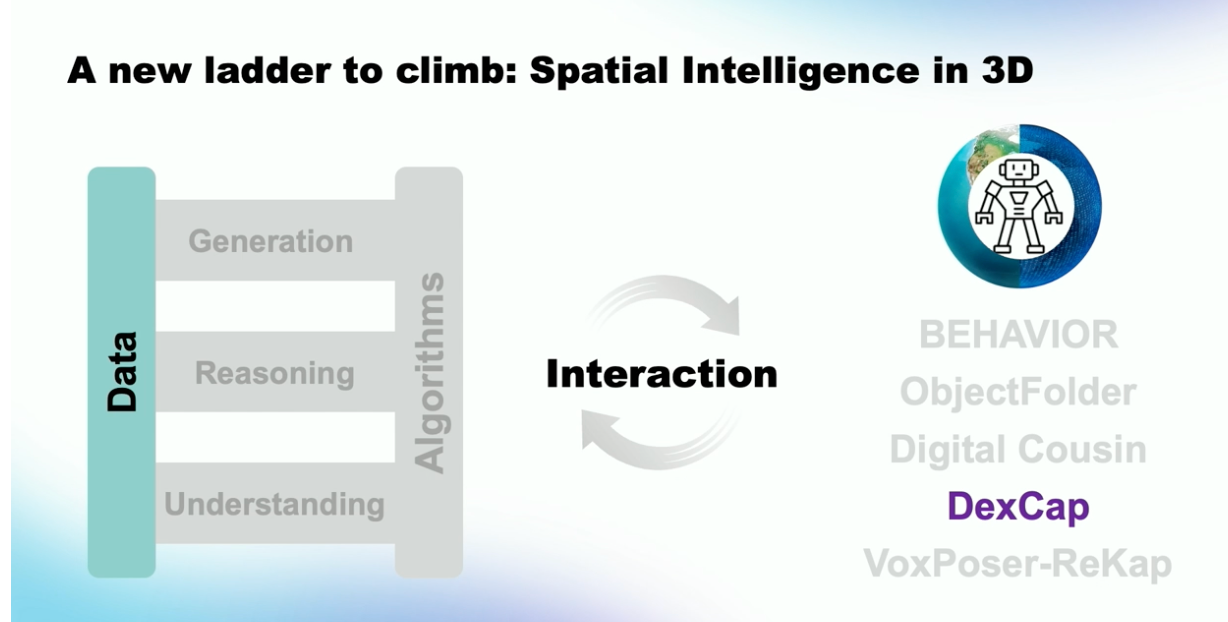
Fei-Fei Li 교수는 인공지능을 발전시키기 위해서 데이터와 알고리즘이라는 기둥에서 시작한다고 하였습니다. 현재 연구는 이 기둥에서 Understanding, Reasoning, Generation이라는 Task를 통해 사다리를 올라가듯이 인공지능을 발전시키고 있습니다. 본인이 진행한 ImageNet부터 Scenegraph, Diffusion model에 대한 연구까지 전부 이러한 사다리를 올라간 연구라고 소개하였습니다. 하지만 아직 인공지능은 텍스트와 이미지의 2D 환경에 머물러 있습니다. 부족한 성능을 해결하기 위해서는 세상과 상호작용하는 Interaction을 다음 단계로 꼽았습니다.
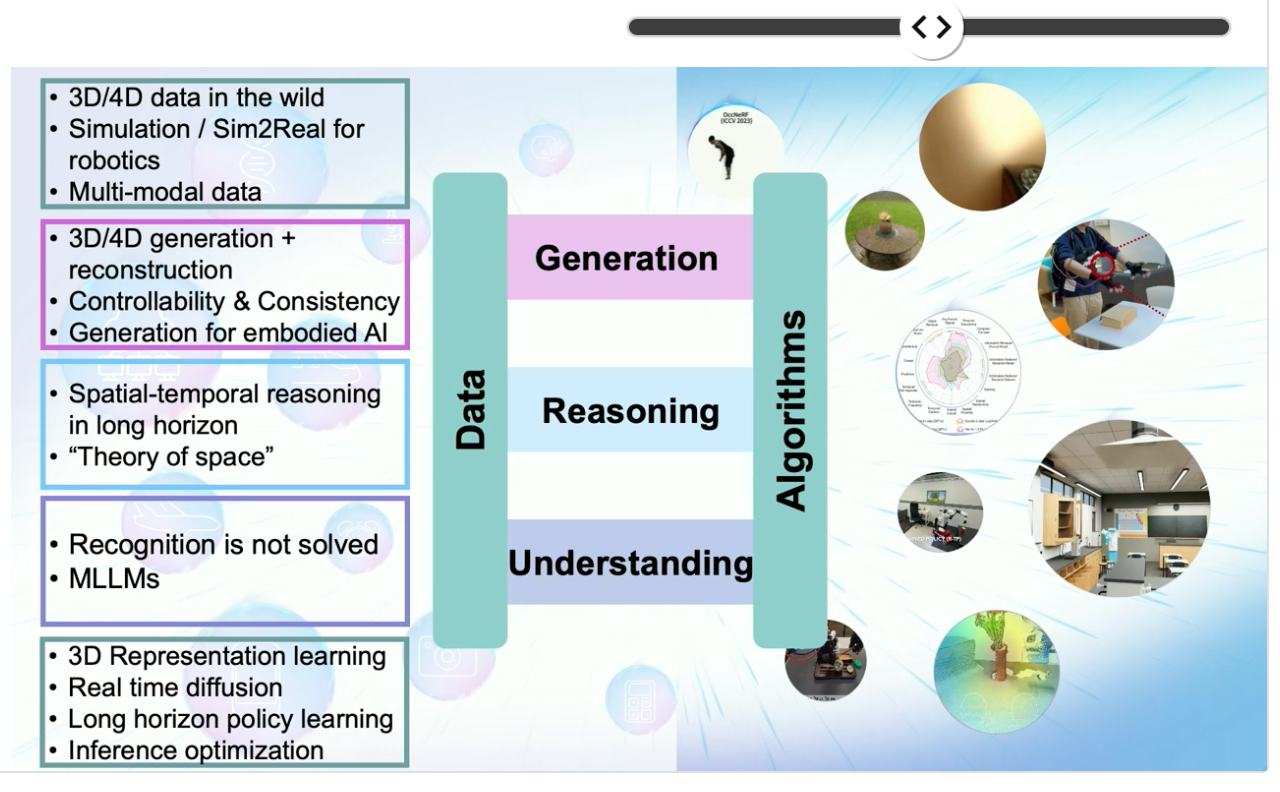

인공지능을 개발하기 위해서는 세상을 더욱 잘 이해하여야하고, 실제 세계와의 interaction을 통해 understanding, reasoning, generation이 모두 필요하다는 것입니다. 자신의 최근 연구 또한 Robotics, Multi-modal model 그리고 Embodied AI에 대한 연구이며 인공지능은 앞으로 인간을 대체(replace)하는 것이 아닌 인간을 강화(augment)하는 존재가 될 것이라고 하였습니다.

마지막으로 자신이 창업한 World Labs을 통해 World model에 대한 가능성을 소개하고 홍보하는 시간도 있었습니다.
이 발표를 통해 저희는 전세계의 연구자들이 각자 생각하는 방향은 다르지만 결국 인공지능을 발전시키기 위해서는 실제 세계를 이해하는 interaction에 대한 데이터가 필요하다는 공통적인 의견이 있었습니다.
AI for Autonomous Driving at Scale by Waymo

다음으로는 Waymo의 Expo Talk Panel이 있었습니다. 이 발표를 통해 Waymo는 어떤 방식으로 인공지능을 자율주행에 사용하고 있는지 확인할 수 있었습니다. 제목과 같이 인공지능을 규모가 있는 자율주행에 적용할 때 생기는 문제를 해결하는 것에 초점이 맞추어져있습니다.
사실 운전중에는 특이한 상황이 잘 일어나지 않습니다. 사고가 발생할만한 문제는 굉장히 가끔 발생합니다. 하지만 인공지능 회사가 자율주행 차량을 수백, 수천대를 운영하게 된다면, 그리고 1년, 2년이라는 긴 시간을 운전하게 된다면 이러한 특이한 상황은 더 이상 작은 문제가 아닙니다. Waymo는 규모가 큰 배포를 하게되면 반드시 해결해야하는 문제가 되는 것입니다. 이를 인공지능으로 해결하기 위해 Waymo는 어떤 방식을 사용했을까요?
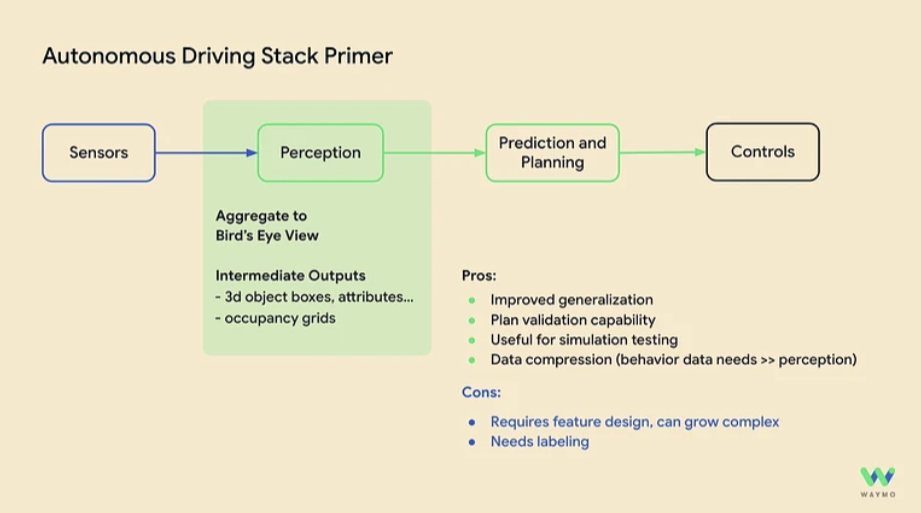
현재 Waymo의 자율주행 기술은 세가지 모듈로 이루어져있습니다.
- 인지(Perception)
- 예측(Prediction)과 계획(Planning)
- 제어(Control)
이중 제어 단계에서는 인공지능을 사용하고 있지 않습니다.
먼저 인지 단계에서는 앞서 말한 규모가 있는 상황에서 문제를 해결하기 위해 모든 센서 정보를 Bird's Eye View (BEV)를 사용합니다. 여기에는 다양한 장단점이 있는데 이미지에 잘 설명되어 있습니다.
- 장점
- 일반화 성능이 좋다.(Generalization)
- 계획에 대한 평가를 하기 좋다.
- 시뮬레이션에서 테스트하기 유용하다.
- 센서 데이터를 손쉽게 압축할 수 있다.
- 단점
- 특징(feature) 디자인이 많이 필요하다. 복잡성이 증가한다.
- 라벨링이 필요하다.

Waymo는 BEV 위에서 확장 가능한(Scalable) 인공지능을 개발하기 위해서 필요한 기술들은 무엇이 있을까요? 여기서는 다음과 같이 다섯가지 재료를 보여주었습니다. 이 다섯가지 재료를 위해 Waymo에서 연구한 Wayformer, MotionLM, SceneDiffuser, MoDAR, Imitation Is Not Enough 등의 연구를 대표적인 예시로 보여주었습니다.

여기서 가장 저희가 관심있는 분야는 VLM/LLM Knowledge에 대한 생각입니다. 도로는 결국 사람이 이해할 수 있게 설계되어있기 때문에 수많은 표지판, 사고 상황 등을 모두 데이터로 학습하는 것이 불가능하고, 이런 관점에서 인터넷 스케일의 데이터로 학습된 LLM과 VLM의 understanding과 reasoning 성능이 필요하다고 하고 있습니다. Waymo에서는 두가지 방식으로 VLM을 사용하였는데요.

첫 번째로, 데이터 라벨링 입니다. MoDAR와 같은 연구에서 더욱 다양한 사물을 이해하기 위해 VLM을 사용하여 더욱 다양한 class의 데이터를 라벨링하여 학습에 사용할 수 있습니다.
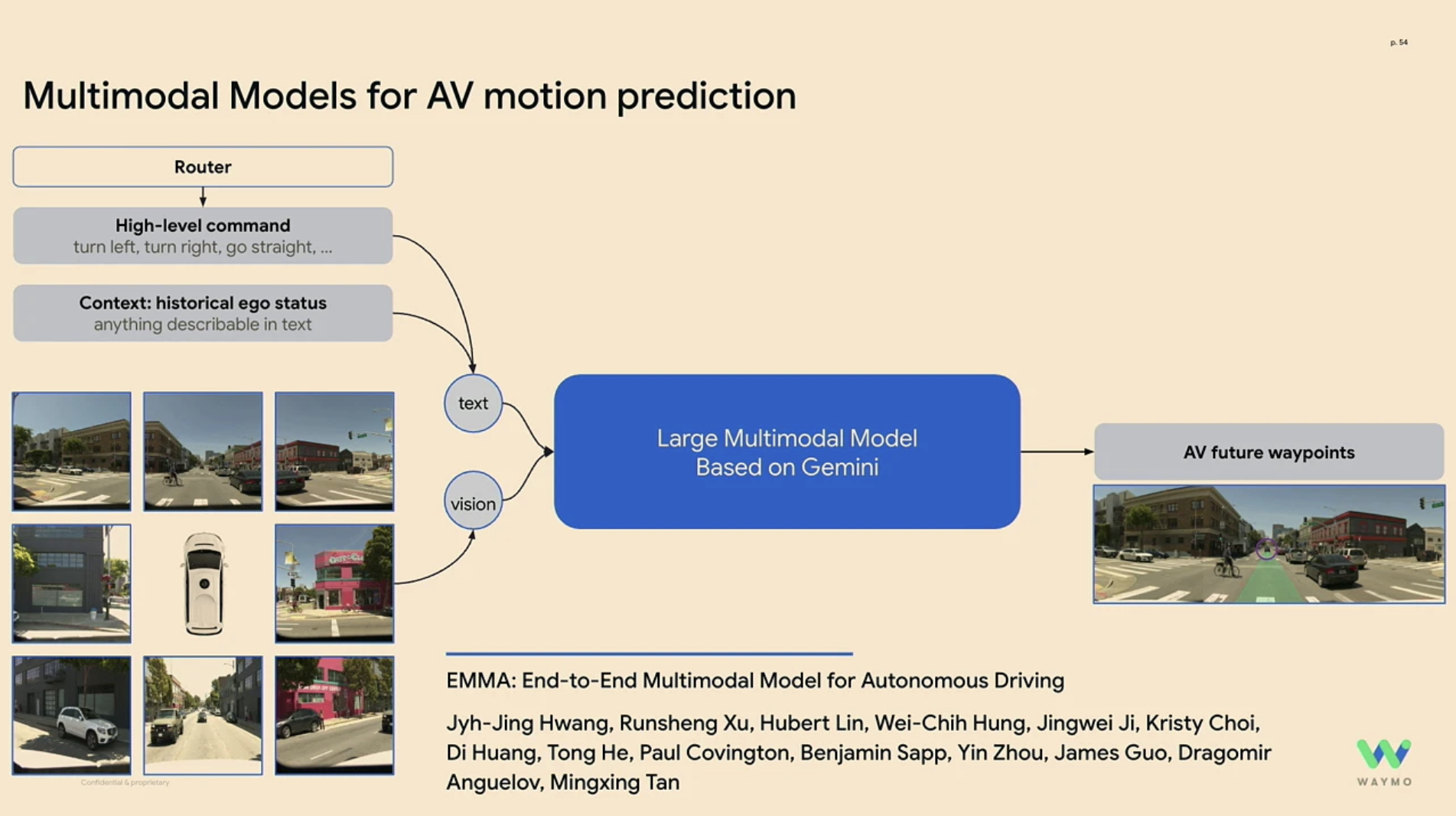
두 번째로, EMMA와 같이 VLM을 통해 이동을 예측하는 것입니다. EMMA는 Google의 Gemini를 사용하여 센서데이터를 활용하여 자율주행 차량의 미래 목적지를 예측하는 모델입니다.
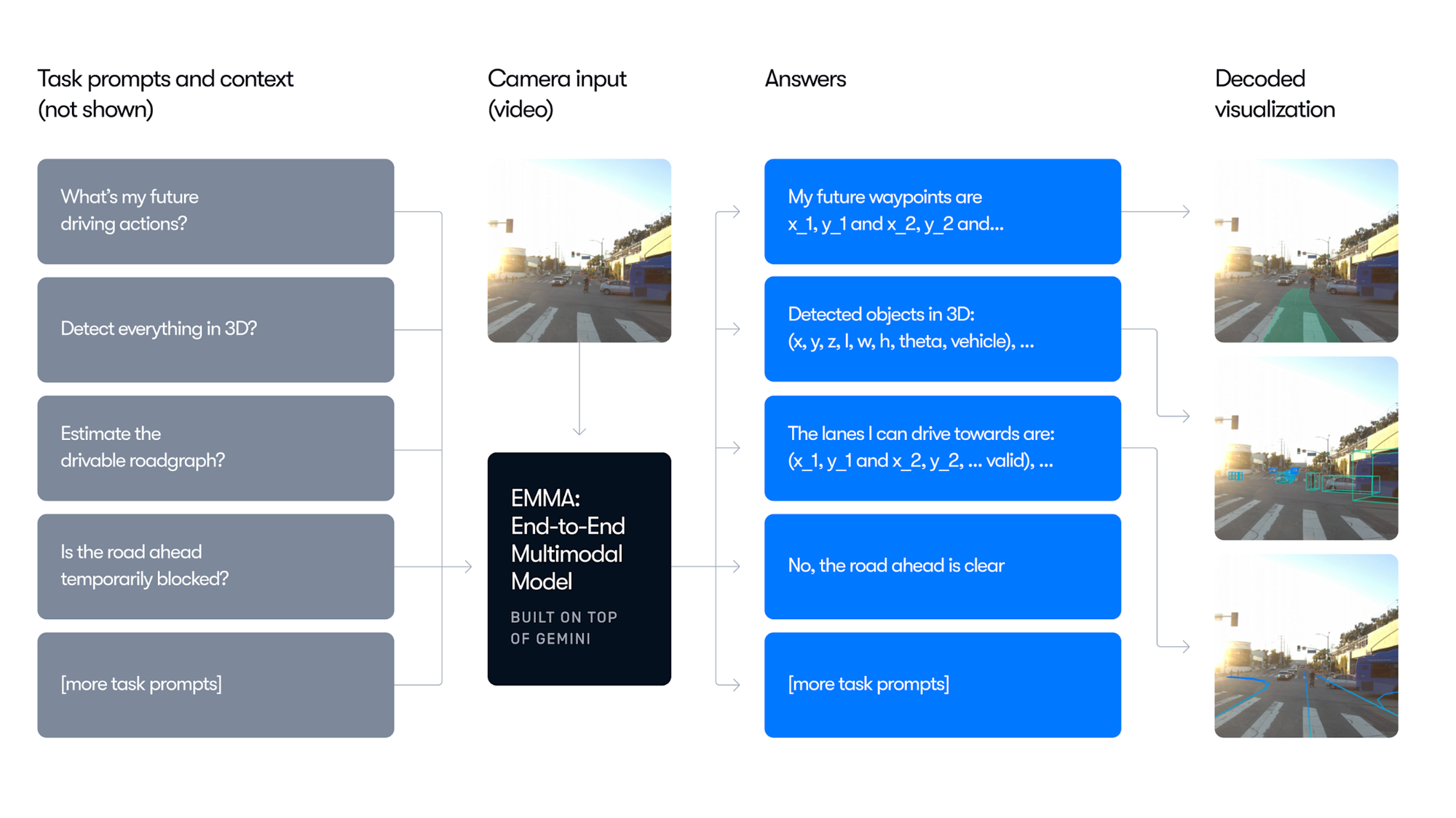
EMMA는 다음과 같이 다양한 task (Waypoint prediction, Object detetion, Lane detection)등을 모두 수행할 수 있도록 학습합니다. 또한, Chain-of-though reasoning을 이용해 end-to-end 경로 계획 성능을 6.7% 이상 향상시키고 이러한 판단에 대해 설명이 가능하도록 하여 더욱 효과적입니다.

하지만 실제 도로에서 자율주행으로 서비스를 하고 있는 회사의 경험에서는 아직 VLM은 자신들의 자율주행을 보조하는 수단일 뿐, End-to-End 주행은 미래의 이야기라고 생각하고 있습니다. Waymo에서는 현재 잘 작동하고 있는 BEV를 이용한 자율주행을 잘 수행하고 있기 때문이라고 생각합니다.
저희가 End-to-End 자율주행 인공지능을 만드는 이유는 이러한 Waymo의 상황과 반대되기 때문에 가능한 것이라고 생각합니다. Waymo에서 밝힌 BEV의 가장 큰 문제점은 데이터가 많이 필요하고, 특징점(feature)을 직접 개발하는 것이 매우 어렵다는 것입니다. 즉, 많은 엔지니어링이 필요하고 연구개발의 규모에서는 따라잡기 어려운 것입니다. 하지만 End-to-End 자율주행은 확장 가능하고 특징점(feature)에 제한되지 않아 다양한 산업에 적용될 수 있다는 점이 있습니다.
End-to-End 자율주행 기술을 연구하며 Waymo에서 고민하는 VLM의 한계에 대해서 저희 팀도 많은 공감을 하고 있습니다.
- 센서 데이터는 언어 데이터에 비해 크기가 크며 이를 효과적으로 압축해야합니다.
- 현재 VLM은 3D 데이터로 학습되지 않았습니다. 아직 환경과의 상호작용을 잘 이해하고 있지 않습니다.
- 사람과 같은 기억력을 가지고 있지 않습니다.
- 모델의 학습, 연산 속도의 효율을 더 높여야합니다.
저희 WoRV팀은 이러한 문제를 효과적으로 해결할 수 있는 방법을 연구중입니다. 또한, VLM이 아니면 해결하기 어려운 자율주행 문제를 먼저 해결하여 상용화를 진행하고 여기서 효율적인 학습과 연산, 그리고 확장 가능성을 고려하여 연구하고 있습니다.
NeurIPS Expo

이번 NeurIPS에서는 학계뿐만 아니라 기업들의 관심도 굉장했던 것 같습니다. 인공지능 인재를 유치하기 위해 정말 누구나 아는 빅테크, 유니콘 스타트업들에서 기업을 홍보하고, 소통할 수 있는 자리였습니다. 그만큼 연구자들의 관심도 상당하여 정말 많은 인파가 몰려있었던 것 같습니다.
저희는 먼저 자율주행 회사부터 찾아가 대화를 나누기 시작했습니다. 인터넷으로만 찾아봤던 Waymo, Wayve, Helm AI 등 다양한 자율주행 회사를 직접 볼 수 있는 기회가 있어 좋았습니다. Tesla의 부스에는 귀여운 Optimus 로봇도 볼 수 있었습니다.

또한 Tesla의 엔지니어 분과의 대화를 통해 휴머노이드 로봇 시장에서의 전략, 연구 방향성, 그리고 기술력에 대해서 많은 정보를 얻을 수 있었습니다.
뿐만 아니라 최근 정말 엄청난 영상을 공개하여 주목받았던 Unitree Robotics도 만날 수 있었습니다. 사족 보행 로봇과 휴머노이드 로봇을 보니 구매하여 자율주행 기술을 더 연구해보고 싶다는 생각이 들었던 것 같습니다. Unitree Robotics와도 대화를 통해 로봇 스펙과 구매 의사를 전달하고 많은 대화를 나누었습니다.
로봇 기업 뿐 아니라 Meta, Google Research, Microsoft, Sony, Apple 등 다양한 기업의 직원들과 이야기하며 인공지능 분야에서 회사들이 어떤 것을 중요하게 생각하는지 알 수 있었습니다. 놀라웠던 점은 생각보다 이런 회사에서도 Embodied AI에 대해 연구하는 회사가 많았고 그 시기가 저의 생각보다 더 빨리 온 것 같다는 생각이 들었습니다.
NeurIPS Poster & Oral Session
대망의 NeurIPS의 메인 행사인 Poster & Oral Session입니다. 저희는 4일이라는 시간동안 정말 많은 논문을 읽고 포스터, oral 발표도 들을 수 있었습니다. 대략 개수만 세어봐도 50개가 넘는 논문을 분석하였습니다. 그 중 Robotics와 관련된 두 가지 포스터 논문에 대해서만 간략하게 소개드리겠습니다.

먼저 UC Berkeley에서 진행한 Humanoid Locomotion as Next Token Prediction입니다. 이 논문을 통해 보행과 같은 행동도 Scaling이 가능하고 특히, 로봇 데이터 뿐 아니라 사람의 모션캡처와 동영상에서도 학습 데이터를 얻어낼 수 있다는 인사이트를 얻을 수 있었습니다.
현재는 후속 논문까지 공개되었으며 Learning Humanoid Locomotion over Challenging Terrain, RL을 이용한 Fine-tuning까지 진행하는 LLM의 학습 방식을 보행에 적용했다는 점이 매우 흥미로운 것 같습니다.
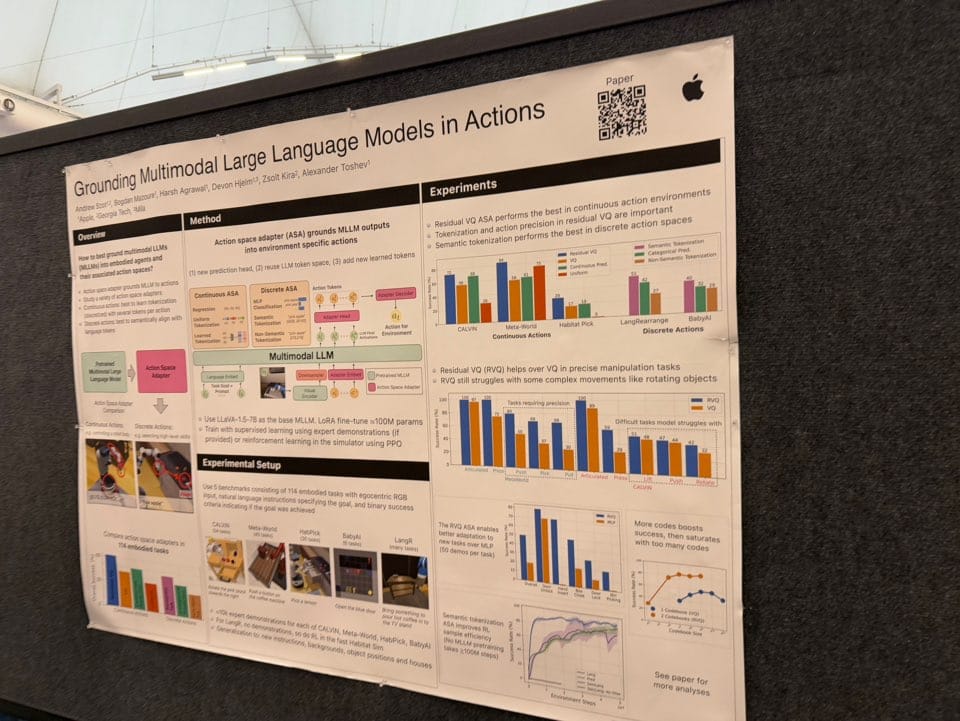
또 다른 논문은 Apple에서 진행한 Grounding Multimodal Large Language Models in Actions입니다. Vision Language Action (VLA) 모델에서 가장 효율적인 action embedding을 찾는 연구입니다. 이 논문을 통해 Action embedding을 어떻게 모델링하는 것이 좋은가에 대한 인사이트를 얻을 수 있었습니다.
이 논문 또한 후속 논문(From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons)이 공개되었습니다. Robotics 데이터 뿐만 아니라 Game, Planning, UI에서의 모든 action embedding을 학습한 Generalist Embodied Agent (GEA)도 공개하였습니다.
Robotics 논문들 외에도 많은 발표를 들을 수 있었으며 모두 소개드릴 수 없어 아쉬운 것 같습니다. 학회에서 만난 다른 한국인 연구자 분들과 교류를 할 수 있어 정말 좋은 시간이었던 것 같습니다. 또한, 저희 회사에 직접 합류하고 싶어하는 서른 명이 넘는 지원자들과 커피챗을 진행하였습니다.
NeurIPS Workshop on Open-World Agents (OWA-2024)
대망의 NeurIPS의 마지막날에는 워크샵(link) 참가가 있었습니다. 이번에 저희 논문 Integrating Visual and Linguistic Instructions for Context-Aware Navigation Agents(link)을 발표할 수 있는 기회가 있었는데요. 약 100개가 넘는 poster session 논문 중 저희 논문은 oral 발표를 할 수 있는 6팀 안에 들게 되었습니다.
논문에 대한 내용은 블로그 SketchDrive 프로젝트 소개를 확인해주세요.
Whats Missing for in RFM? by Google DeepMind, Ted Xiao
워크샵에서는 정말 많은 인사이트를 얻을 수 있었는데요. 먼저, Google Deepmind의 Foundation model을 개발한 Ted Xiao의 강의를 들을 수 있었습니다.

이 강의를 통해 Ted Xiao는 현재 시점의 Robot foundation model을 개발하기 위해 부족한 세가지 요소를 설명하였습니다.
- Scaling Laws
- High-bandwidth Contexts
- Scalable Evaluation
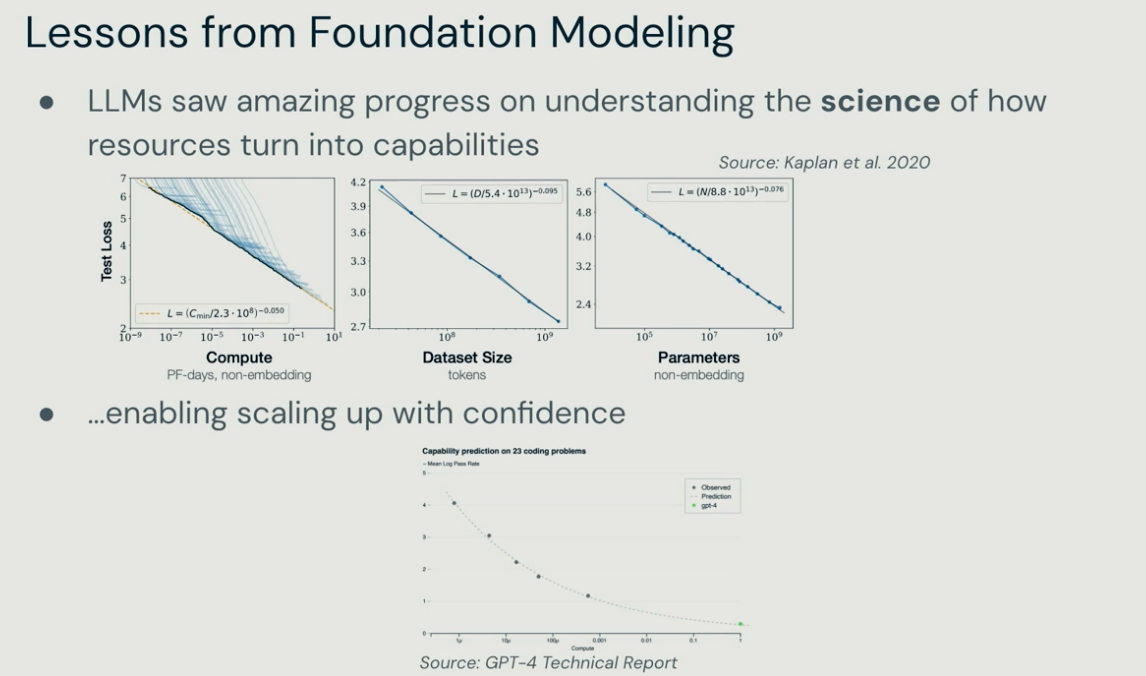
먼저 첫번째로, Scaling law입니다. 단순히 로봇 데이터는 많은 데이터를 학습한다고 좋아지지 않습니다. 더욱 잘 정제된 데이터, 그리고 긍정적 전이(Positive Transfer)가 생길 수 있는 데이터를 넣어야합니다. 아직 LLM에서의 언어와 같은 공통적인 표현(representation)이 없는 상태에서 행동 데이터는 어떻게 표현할 것인가가 가장 중요한 문제입니다.
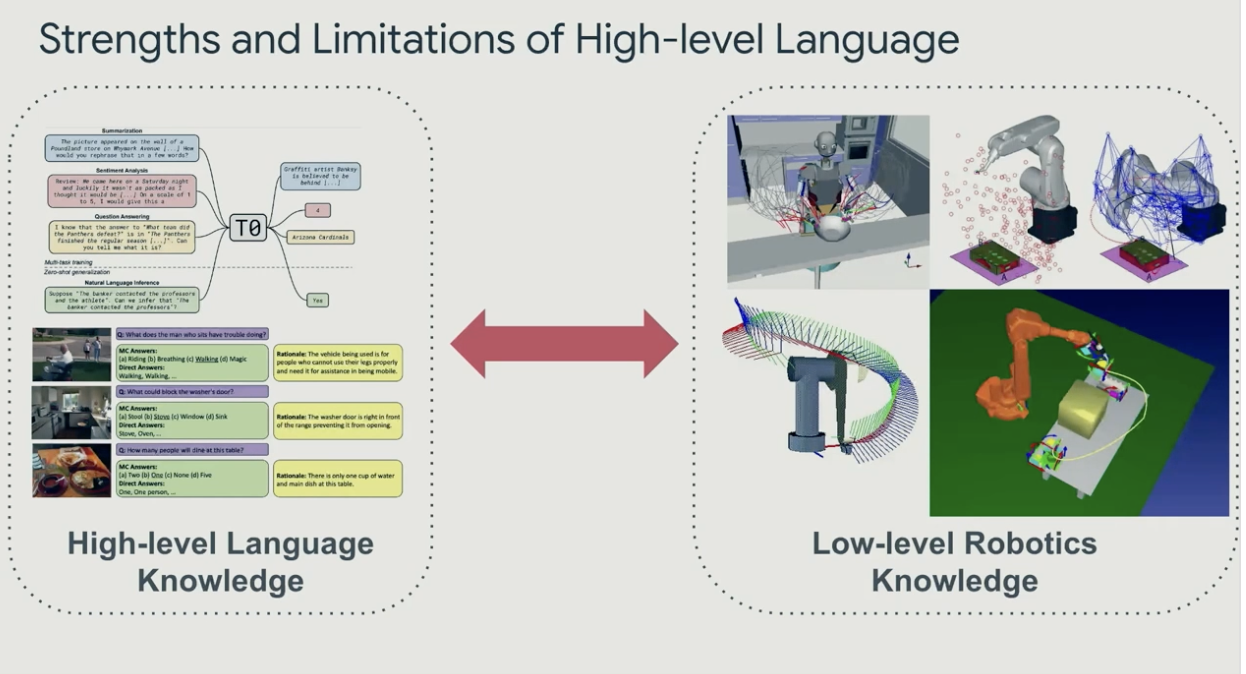
두번째로, High-bandwidth Contexts 문제입니다. 로봇에서는 상태를 나타내기 위해 필요한 정보량이 너무 많습니다. 현재 상태를 정의할 때도 로봇 팔의 각 모터의 각도, 속도, 힘을 모두 기록하는 것은 bandwidth가 문제가 되고, 그렇다고 언어로 너무 압축하면 자세한 것을 표현하기 어렵습니다. 이러한 문제를 해결하기 위해 현재 상태를 affordance, trajectory 등 다양한 정보로 압축하는 것이 가능성이 될 수 있다고 합니다.

마지막으로, Scalable evaluation입니다. LLM과 달리 한정된 데이터셋으로 평가할 수 있는 것이 아니라 환경과 상호작용하며 성능을 평가해야합니다. 이 때 실제 환경에서 평가하는 것은 굉장히 비싸고 어렵습니다. 시뮬레이션에서는 상대적으로 싼 가격으로 대략적인 성능을 확인할 수 있습니다.

최근에는 world model이라는 이름과 함께 다양한 환경을 제현하는 인공지능 모델이 연구되었습니다. 하지만 시뮬레이션과 world model은 절대 현실에서의 평가를 대체할 수 없다고 합니다.
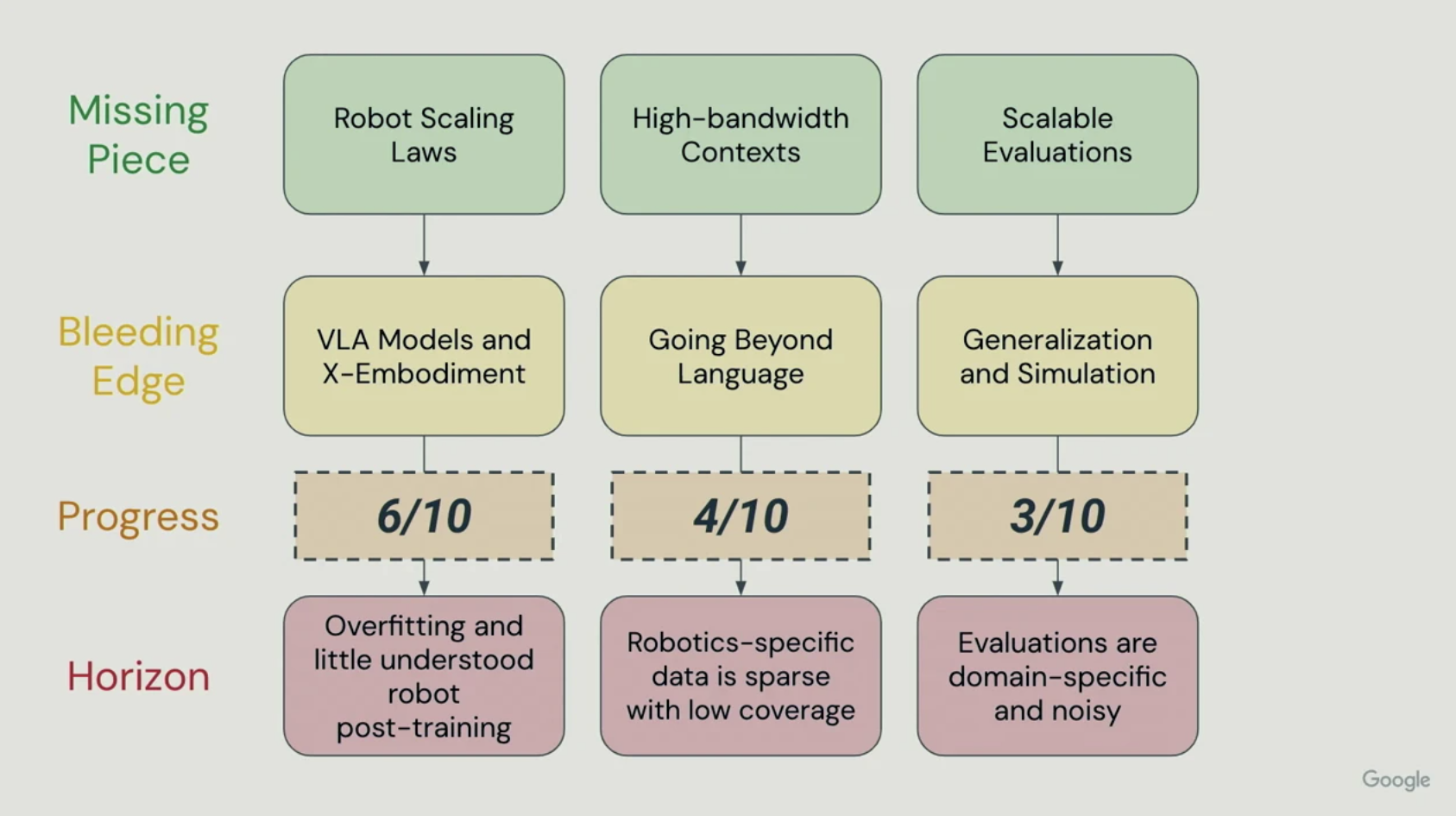
그렇다면 현재 어느정도 진행되었을까요? 그림과 같이 Robot Scaling Laws는 60%, High-bandwidth Contexts는 40% 그리고 Scalable Evaluations는 30% 정도 진행되었다고 보고 있습니다. 앞으로 많은 발전이 일어나 robot foundation model을 볼 수 있으면 좋겠습니다.
강의가 끝나고 난 뒤 Ted Xiao와의 대화를 통해 앞으로의 robot foundation model의 모습을 질문하였습니다. Ted는 앞으로 natively multimodal model이 연구되어야한다고 주장하였습니다. 이 뜻은 로봇의 센서 데이터와 행동을 통해 pre-training단계부터 학습하는 multimodal model이 있어야 한다는 것입니다. 하지만 LLM을 개발하는 것의 비용을 생각해보면 더 많은 비용이 들 것이고, 일단 LLM을 쓰는 것이 성능을 보장할 수 있는 길이라고 생각하였습니다.
Poster & Oral Presentation
또한, 포스터 세션에서 Meta의 Meta Motivo부터 시작하여 다양한 LLM, VLM agent 연구들을 확인할 수 있었습니다. 또한, ROCKET-1을 발표한 Craft jarvis 팀과의 커피챗을 통해 저희가 고민하던 인공지능 연구를 위한 환경 개발에 대해 많은 대화를 하고 협력할 수 있는 기회를 마련하였습니다.

이후, 저희는 떨리는 마음으로 oral 발표를 기다렸는데요, 긴장하였지만 다행히 발표를 잘 끝마칠 수 있었습니다. 또, 같이 oral 발표를 하게 된 NUS와 Microsoft의 ShowUI팀 그리고 British Columbia와 Deepmind의 Automated Design of Agentic Systems팀의 발표도 들을 수 있었습니다.

함께 발표하는 것 만으로도 좋은 기회라고 생각하였는데, 발표가 끝난 후 Outstanding paper awards에 선정되었다는 사실이 발표되어 더욱 기쁜 순간이었습니다. 뛰어난 연구자들과 함께 교류하고 그 성과를 인정받은 것 같아 기분 좋은 경험이었습니다. 이 기회를 빌어 이 연구를 위해 힘써준 저희 팀원과 연세대학교 미르랩에게도 감사를 전하고 싶습니다.
마무리
이번 NeurIPS 2024에 참가하여 개인 입장에서도 회사 입장에서도 굉장히 성장할 수 있는 기회가 된 것 같습니다. 마음AI의 WoRV팀도 더욱 성장하고 세상에 저희의 연구를 알릴 수 있었습니다.
다양한 학계, 업계 사람들과 교류를 하고 인공지능 연구가 어떻게 나아가야하는지, 그리고 현재 인공지능 연구의 한계에 대해 진지한 토론을 하는 경험이 흔치 않을 것 같습니다. 앞으로도 연구와 개발을 진행하여 많은 사람들에게 인정받을 수 있는 기회를 만들도록 하겠습니다.
WoRV팀에 관심이 있으신 분들은 편하게 채용 페이지의 커피챗이나 지원을 해주시면 감사하겠습니다. 또한, 연구 성과와 Agent 연구의 최신 소식을 듣고 싶으시면 우측 하단의 구독도 잊지 말아주세요.


