[EN] What is Embodied AI?

Who should read this post
- Those interested in research or development of agents (robotics, games, desktop control, etc.)
- ML researchers/engineers looking to explore emerging areas beyond traditional major fields like CV and NLP
- Those who believe the time has come to utilize data collected from real-world interactions
Hello, I’m Soohwan Choi, a Machine Learning Engineer at the WoRV team. Today, I would like to briefly introduce the field of Embodied AI. This post reflects only my limited perspective compared to the depth and breadth of the topic, so if anything seems incorrect or unclear, I would appreciate your generous understanding and proactive feedback. Coffee chats or emails are always welcome.
What is Embodied AI?
There isn’t a single universally agreed-upon definition of Embodied AI. However, simply put, we can describe Embodied AI as:
“Artificial intelligence that has a physical presence and interacts with the environment.”
The term is often used interchangeably with Embodied Agent.
A definition I personally prefer is:
“An agent that can behave and live within an environment.”
The key idea is the ability to act within an environment.
Examples of embodied agents include:
game-playing agents, robots, agents controlling desktop/web/UI environments, or Android device controllers. Under this definition, physical form is not essential—and this perspective is widely accepted across many research contexts.
Our WoRV team’s project CANVAS is also an embodied AI research project.
Some of the content I will discuss below is based on the following two excellent talks:
- Stanford CS25: V3 | Low-level Embodied Intelligence w/ Foundation Models
(Fei Xia, Google DeepMind, Dec 2023)
Introduces Google’s research on robotics foundation models. - Stanford CS25: V3 | Generalist Agents in Open-Ended Worlds
(Jim Fan, NVIDIA AI, Dec 2023)
Presents NVIDIA’s vision for generalist agents and Minecraft-based research.
From Internet AI to Embodied AI
A phrase that strongly resonated with me from Fei Xia’s lecture is:
“We are moving from the Internet AI era to the Embodied AI era—an era where models learn through interacting with the environment rather than relying solely on internet-scale data.”
What does this mean?
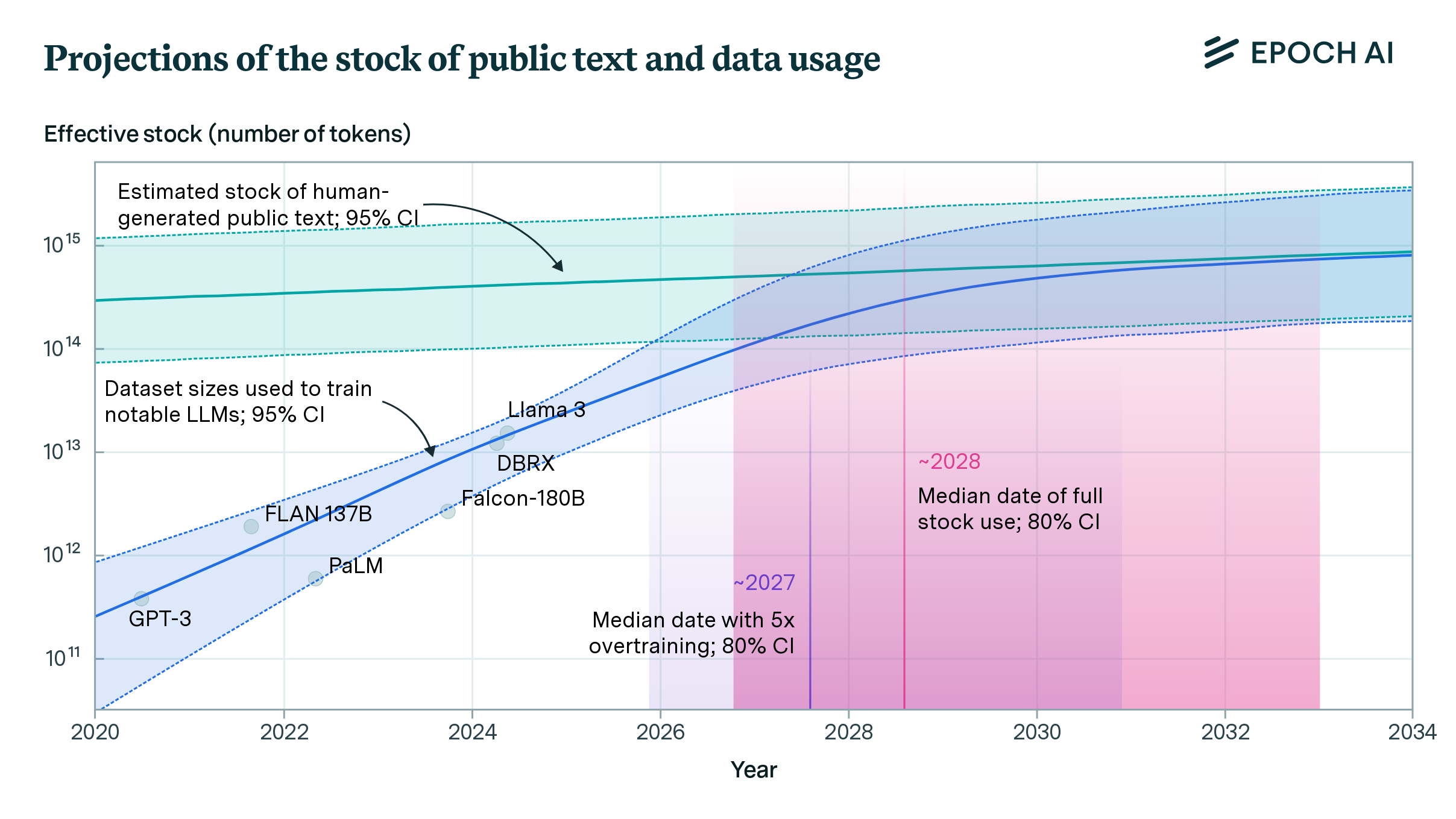
Today’s AI systems heavily rely on datasets scraped from the internet. This is simply because scaling datasets is only practically possible through internet collection. A research paper estimates that human-generated text available publicly on the internet will be exhausted for LLM training sometime between 2026–2032:
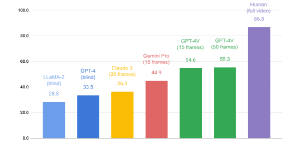
In addition, because current AI depends so heavily on internet data, the type of tasks it can solve is fundamentally limited. Although modern LLMs and MLLMs sometimes appear omnipotent, benchmarks like OpenEQA have shown that even the most advanced models perform far below humans in tasks requiring real spatial understanding and environmental interaction.
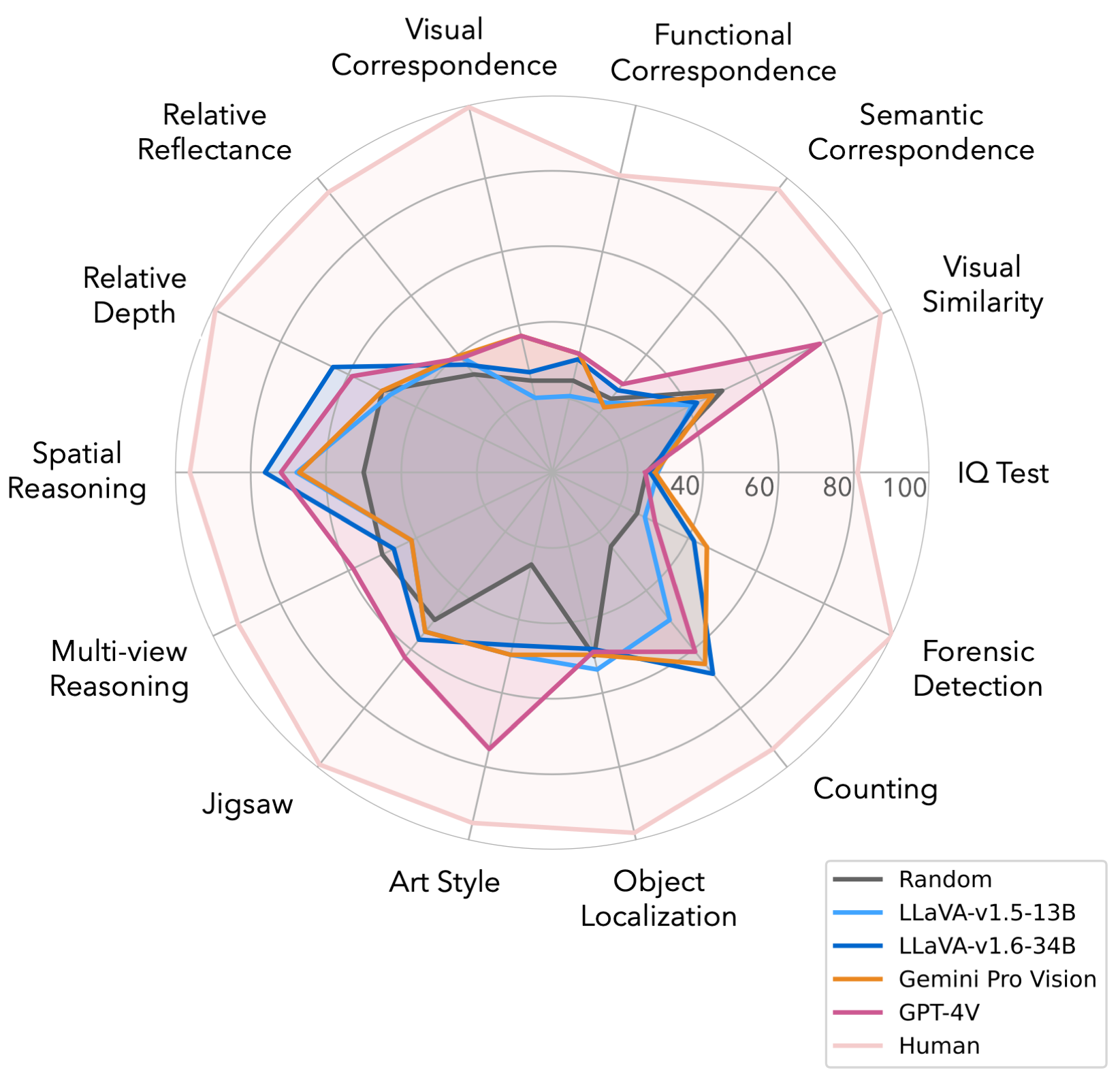
Similarly, BLINK demonstrated that state-of-the-art MLLMs fail dramatically at tasks humans solve “in the blink of an eye,” such as relative depth estimation and spatial reasoning.
Under this context, building embodied agents dramatically expands the range of achievable tasks.
Most importantly, allowing AI to act and influence the real world creates enormous practical value:
- Replacing human labor in factories, restaurants, or manufacturing through robotic arms
- Delivery, serving, agricultural spraying through mobile robots
- Autonomous vehicle driving
- Desktop control for automating computer workflows
- Entertainment (e.g., game-playing agents)
Compared to the Internet AI era—where models mainly perform classification, detection, captioning, segmentation—the possibilities are exponentially larger.
Today's topic: generalist agent
Today, the main topic I would like to cover is the generalist agent.
This is the field I personally pay the most attention to and am highly interested in, and it also significantly influences the research direction of the WoRV team.
So, what exactly is a generalist agent?
Although the term “generalist agent” does not yet have a universally established research definition, I will describe it based on the definition mentioned by Jim Fan in his lecture combined with my own perspective.
Specialist agents to Generalist agent
Previous research has primarily focused not on generalist agents, but on specialist agents.
Many readers are likely familiar with AlphaGo, which defeated humans in Go, and AlphaStar, which defeated humans in StarCraft.
These models were trained based on Reinforcement Learning (RL), where:
- They learn a single task (winning),
- And the reward is very clearly defined (reward is given if and only if they win).
They have a single objective and perform it very well, but the flip side is that they can do nothing else.
In contrast, a generalist agent, like a human, is capable of performing multiple tasks, and can learn new tasks through a few iterations of trial and error, rather than thousands or millions of repetitions.
SIMA: A generalist AI agent for 3D virtual environments
There is one research project that I always mention when discussing embodied agents: SIMA, released by DeepMind in March 2024.
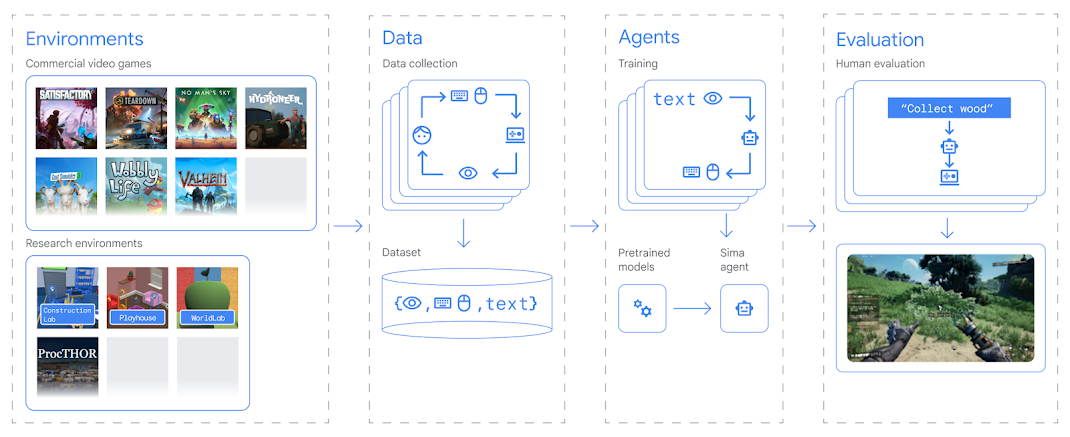
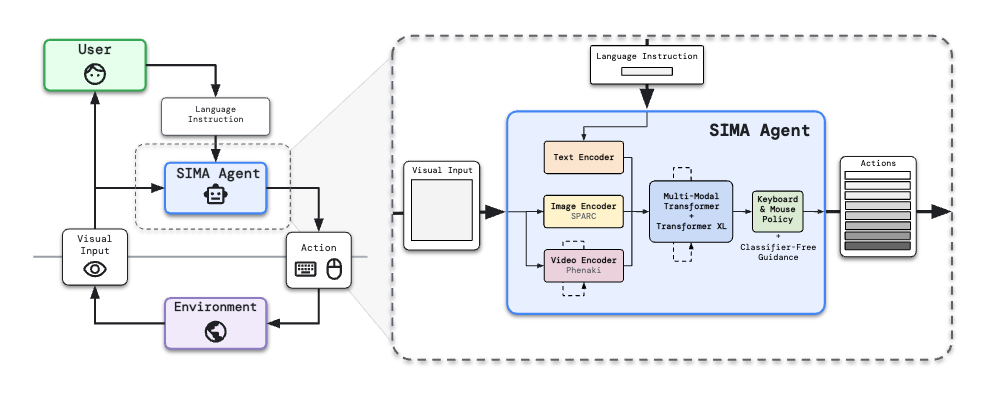
In this work, the researchers collected keyboard/mouse and monitor data across a wide range of commercial video games and research environments, and trained an agent (SIMA) that predicts keyboard/mouse actions from monitor input. In addition, they labeled language prompts to guide the agent’s behavior in natural language.
This agent can control a character chopping wood, or pilot a spaceship to destroy asteroids.
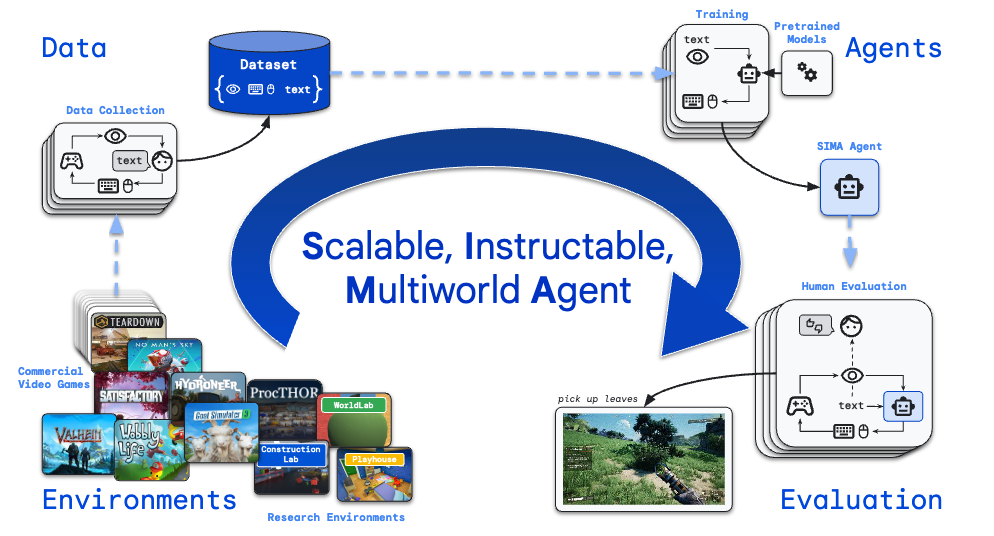
They also included the words “Scalable” and “Instructable” in the model name.
As mentioned in the SketchDrive introduction article, I consider these two properties extremely important, and they are characteristics that are easy to overlook for those encountering embodied agent research for the first time.
In particular, instructable is something that people tend to overlook.
People vaguely want “an agent that just does things well,” but many games do not have a single clear and obvious objective. Even without consciously recognizing it, everyone has an internal expectation about how the model should behave. Expecting the model to act in that desired manner without conveying that expectation in some form is equivalent to asking it to solve an impossible task.
This characteristic makes task definition extremely challenging in agent research.
I judged that existing deep learning–based driving research defined tasks (e.g., driving toward a goal image or following natural language instructions) in a suboptimal way, and our SketchDrive research was aimed at improving this issue.
Architecture of Agent
If you are an ML researcher encountering embodied agent research for the first time, you are probably most curious about which architecture to use.
In the SIMA work mentioned above, the model is multimodal but not based on MLLMs or LLMs.
However, in 2023, Google already proposed a strong MLLM-based architecture in RT-2.
More precisely, the architecture itself hardly changes. Since an MLLM already understands vision and language, all that remains is to add an action modality.
To handle actions as input/output, RT-2 uses token expansion.
They build an action tokenizer corresponding to the text tokenizer, represent actions as sequences of discrete action tokens, and then adjust embedding size and lm_head accordingly.
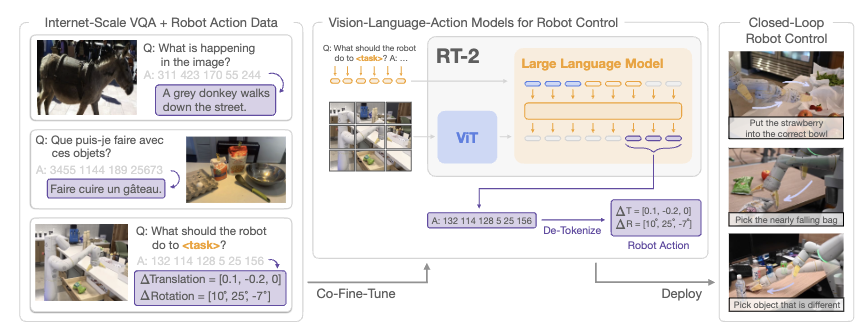
This structure already works well and is utilized in autonomous-driving research such as DriveLM.
Why tokenize?
If this is your first time encountering this research, you may wonder:
“Continuous action can just be predicted with a regression head—why tokenize and classify?”
The answer is explained in BeT, and can be illustrated with a simple example:
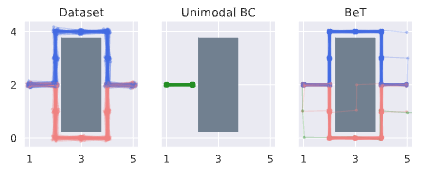
Suppose there is an obstacle ahead, and turning left or right are both correct options.
With regression, what will the steering output become?
→ 0, meaning no turn at all, because the mean of left and right is zero.
Regression—especially L2 regression—assumes a Gaussian (unimodal) output distribution.
However, action distributions in real environments are often multimodal.
A Gaussian cannot approximate multimodal distributions effectively, which makes regression inherently unsuitable.
In contrast, classification loss allows learning multimodal distributions.
Later work such as VQ-BeT proposes improved tokenization methods, but we found that even simple K-Means clustering is sufficient for waypoint prediction (predicting 2D coordinates for where a navigation robot should go next).
Key is Data & Env
In fact, architecture is the least important part.
With today’s MLLMs, simple token expansion is enough to manage the input/output format.
The real issue is whether:
- There is an environment to generate experience
- There is a data pipeline
- There is a reproducible open ecosystem
Imagine wanting to conduct agent research when no environment exists.
This is worse than trying to do LLM research without internet access. Without internet, you merely cannot collect training data—but you can still evaluate if you build a dataset manually.
But without an environment, you cannot generate data or evaluate at all.
Unfortunately, this is extremely common in agent research. Very few places perform agent research, and even fewer release it open-source, making high-quality data extremely difficult to obtain. Even if datasets exist, they are often low quality or do not satisfy necessary conditions.
The truly unfortunate reality is that, although data and environments are the most important parts of agent research, most closed-source groups hide them intentionally.
The WoRV team recognized this issue and has built a pipeline that allows ML researchers to collect desired data directly across various environments, including both real-world and simulation. (Reality is simply another kind of simulator.)
Through this process, we realized that engineering rather than ideas is the most critical component, and anyone entering this frontier will face the same burden.
More detail can be found in the article below:
Fortunately, as more people participate in and become interested in agent research, and as more standardized and general-purpose architectures for agent codebases become widespread, it will become much easier to begin and develop research in this field.
In closing...
There is much more I wanted to cover, but this post only discusses a small portion—intended for those unfamiliar with agent research to read lightly and develop interest. The amount we have learned through real agent R&D is far too large to include here.
I hope this post encourages you to explore Embodied AI and Embodied Agents.
If you would like to discuss related research—even casually—coffee chats are always welcome.
Please feel free to reach out through the coffee chat link on our careers page.
Thank you.